Clear Sky Science · ru
Применение сглаженных OWA-операторов для классификации пигментного ретинита
Почему это важно для зрения
Постепенная потеря зрения из‑за наследственного заболевания — пугающая перспектива, и ранняя диагностика важных для сохранения зрения состояний критична. В этом исследовании изучается, как современные методы искусственного интеллекта могут помочь врачам отличать несколько редких, но серьёзных заболеваний сетчатки, включая пигментный ретинит, по детальным фотографиям заднего отдела глаза. Найдя более умный способ комбинировать суждения множества компьютерных моделей, авторы показывают, что машины способны обнаруживать эти заболевания значительно надежнее, чем раньше, даже при небольшом количестве доступных снимков пациентов.
Распознавание болезней на фотографиях глаза
Пигментный ретинит — это группа генетических состояний, которые постепенно разрушают светочувствительные клетки сетчатки. Люди часто сначала замечают затруднения при ночном зрении, затем теряют боковое зрение, и у некоторых в конечном счёте развивается слепота. Родственные расстройства, такие как конусно‑палочковая дистрофия и синдром Ушера, на снимках глаза могут выглядеть похоже и иметь сходные тонкие визуальные признаки. В исследовании специалисты медицинского центра в Люблине (Польша) собрали ультра‑широкоугольные снимки сетчатки у 186 пациентов с такими состояниями, а также снимки здоровых глаз из отдельной базы данных. В результате получилась задача пятиклассовой классификации: два генетических варианта пигментного ретинита, конусно‑палочковая дистрофия, синдром Ушера и здоровые контролы. Набор данных был малым и несбалансированным, что отражает реальную редкость заболеваний — в некоторых категориях было существенно больше примеров, чем в других, что делало задачу особенно сложной.
Обучение машин «читать» сетчатку
Для интерпретации этих изображений авторы обратились к мощным системам распознавания изображений, изначально разработанным для повседневных фотографий: сверточным нейронным сетям и более новым моделям на базе трансформеров. Они протестировали несколько архитектур, включая EfficientNet, ResNet, VGG, Inception и две версии Vision Transformer. Каждая сеть сначала проходила предобучение на большой общей базе изображений, а затем дообучалась на ретинальных снимках — стратегия, известная как transfer learning. Стандартные методы аугментации данных, такие как отражение, вращение и небольшие искажения изображений, помогли моделям справляться с различиями в аппаратуре и анатомии пациентов. Даже с этими современными приёмами лучшая одиночная сеть правильно классифицировала лишь примерно две трети тестовых случаев, причём результаты были заметно хуже для самых редких категорий заболеваний.
Разрешив моделям «голосовать» вместе
Вместо того чтобы полагаться на одну сеть, исследователи задали вопрос: что если рассматривать каждую модель как эксперта в панели и объединять их мнения? Эта идея, называемая агрегацией или ансамблевым обучением, обычна в машинном обучении, но часто реализуется простым голосованием или усреднением. Здесь команда использовала более гибкий класс инструментов — упорядоченные взвешенные усреднения (OWA). Для каждого возможного диагноза OWA берёт вероятности, выданные всеми сетями, сортирует их от наибольшего к наименьшему и затем смешивает с помощью тщательно подобранного набора весов. Фактически это придаёт больший вес моделям, которые более уверены, одновременно учитывая вклад остальных. Такая агрегация сама по себе дала драматический скачок в общей точности: примерно с 68% для лучшей одиночной модели до более чем 93% при объединении выходов сетей с базовой схемой OWA.
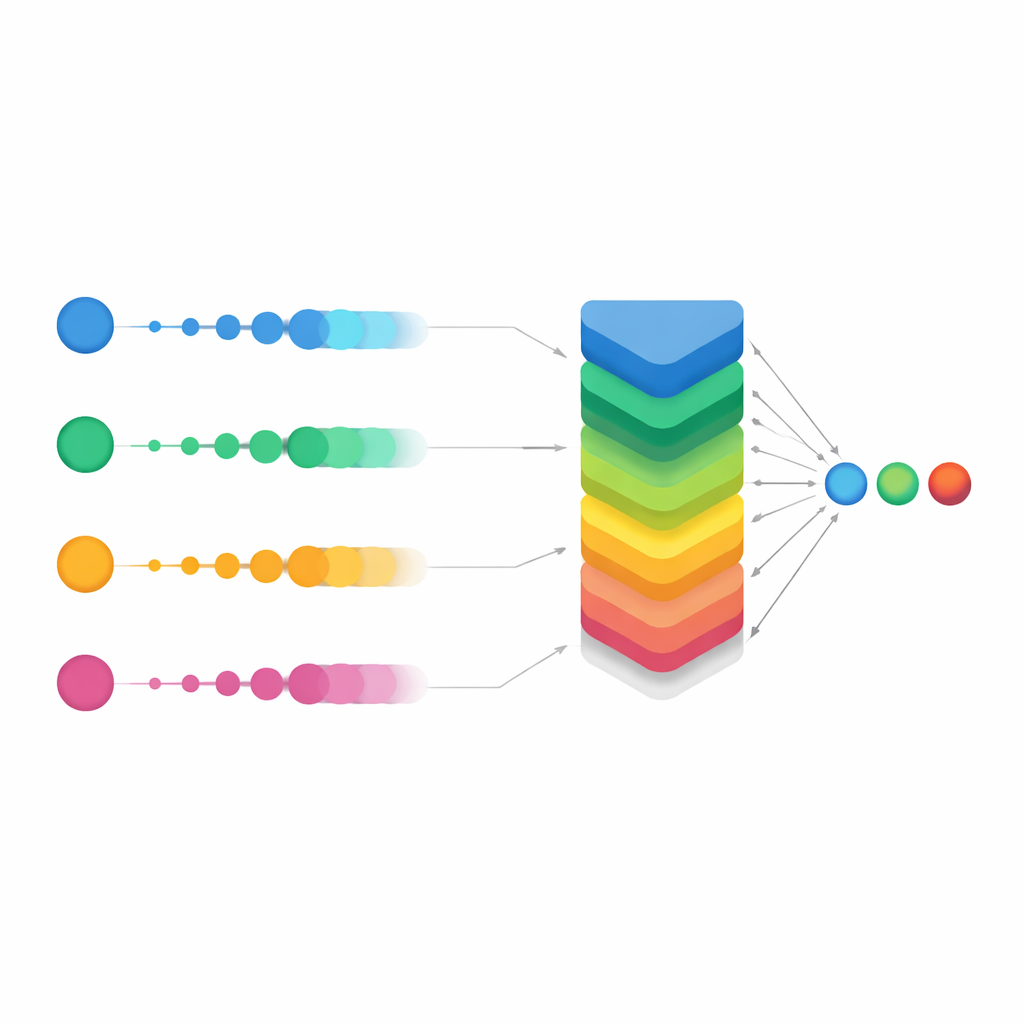
Сглаживание голосования для сложных случаев
Главное новшество исследования — усовершенствованная версия, названная Smooth OWA. Вместо рассмотрения каждой вероятности модели по‑отдельности, Smooth OWA мягко «сглаживает» каждое значение при помощи соседних перед применением взвешенного усреднения. Правила сглаживания заимствованы из классических формул численного интегрирования, известных как квадратуры Ньютона–Котеса, которые обычно применяются для точных вычислений площадей. В этом контексте они помогают уравновесить нестабильные или пограничные предсказания между моделями. Хотя дополнительный выигрыш по сравнению со стандартным OWA был скромным — порядка полупроцентного пункта в точности — он был стабилен в повторных тестах и повысил общую производительность примерно до 94%. Важнее того, матрицы ошибок показали резкое снижение числа неверных классификаций по всем пяти классам, особенно для самых редких заболеваний. В некоторых группах доля правильных распознаваний выросла с примерно двух третей у лучшей одиночной модели до значительно выше 90% с применением Smooth OWA.
Что это значит для пациентов и врачей
Для неспециалиста ключевая мысль в том, что ни одна модель искусственного интеллекта не обязана быть идеально точной, чтобы быть клинически полезной. Тщательно объединив несколько хороших, но несовершенных моделей и плавно стабилизировав их выходы, исследователи превратили набор «довольно хороших» инструментов в один очень сильный помощник при принятии решений. Подход Smooth OWA справился с небольшим, несбалансированным набором данных и всё же достиг показателей производительности, которые было бы сложно получить иными способами. Хотя работа остаётся на этапе исследований и требует валидации в больших многоцентровых исследованиях до применения в клинике, она указывает ясный путь: будущие диагностические системы для редких заболеваний глаза могут опираться не на одиночный алгоритм, а на скоординированный «совет» алгоритмов, чьё коллективное суждение более точное и надёжное.
Цитирование: Rachwał, A., Rachwał, A., Powroźnik, P. et al. Application of smooth OWA operators to classification of retinitis pigmentosa. Sci Rep 16, 11995 (2026). https://doi.org/10.1038/s41598-026-41840-5
Ключевые слова: пигментный ретинит, глубокое обучение, ретинальная визуализация, ансамблевые методы, ИИ для медицинской диагностики