Clear Sky Science · pl
Zastosowanie gładkich operatorów OWA do klasyfikacji retinitis pigmentosa
Dlaczego to ma znaczenie dla wzroku
Stopniowa utrata wzroku wskutek dziedzicznej choroby oczu to przerażająca perspektywa, a wczesne rozpoznanie tych schorzeń jest kluczowe dla zachowania widzenia. Badanie to bada, jak nowoczesna sztuczna inteligencja może pomóc lekarzom odróżniać kilka rzadkich, lecz poważnych schorzeń siatkówki, w tym retinitis pigmentosa, na podstawie szczegółowych zdjęć tylnej części oka. Znajdując mądrzejszy sposób łączenia ocen wielu różnych modeli komputerowych, autorzy pokazują, że komputery potrafią rozpoznawać te choroby znacznie bardziej niezawodnie niż wcześniej, nawet gdy dostępna jest niewielka liczba obrazów pacjentów.
Wykrywanie choroby na zdjęciach oka
Retinitis pigmentosa to grupa schorzeń genetycznych, które stopniowo niszczą komórki światłoczułe w siatkówce. Ludzie często najpierw zauważają problemy z widzeniem po zmroku, potem tracą widzenie boczne, a niektórzy ostatecznie stają się niewidomi. Podobne zaburzenia, takie jak dystrofia czopkowo-pręcikowa czy zespół Ushera, mogą wyglądać podobnie na zdjęciach i dzielić subtelne wzorce wizualne. W tym badaniu specjaliści z ośrodka medycznego w Lublinie zebrali ultra-szerokokątne zdjęcia siatkówki od 186 pacjentów z tymi schorzeniami oraz zdjęcia zdrowych oczu pochodzące z oddzielnej bazy danych. Wynikiem było zadanie pięcioklasowej klasyfikacji: dwa genetyczne warianty retinitis pigmentosa, dystrofia czopkowo-pręcikowa, zespół Ushera oraz grupa kontrolna zdrowych oczu. Zestaw danych był mały i niezrównoważony, co odzwierciedla rzadkość w praktyce — niektóre kategorie miały znacznie więcej przykładów niż inne, co czyniło zadanie szczególnie trudnym.
Nauczanie maszyn „czytania” siatkówki
Aby interpretować te obrazy, autorzy sięgnęli po zaawansowane systemy rozpoznawania obrazów pierwotnie opracowane do zdjęć codziennych: sieci konwolucyjne oraz nowsze modele oparte na transformatorach. Testowali kilka architektur, w tym EfficientNet, ResNet, VGG, Inception oraz dwie wersje Vision Transformer. Każdą sieć najpierw trenowano na dużej, ogólnego przeznaczenia bazie obrazów, a następnie dopracowywano na zdjęciach siatkówki — strategia znana jako transfer learning. Standardowe augmentacje danych, takie jak odbicia, rotacje i lekkie zniekształcenia, pomogły modelom radzić sobie z różnicami w urządzeniach obrazujących i anatomii pacjentów. Nawet przy tych zaawansowanych technikach najlepsza pojedyncza sieć poprawnie sklasyfikowała jedynie około dwóch trzecich przypadków testowych, a wyniki były znacząco słabsze w najrzadszych kategoriach chorób.
Pozwalając wielu modelom głosować razem
Zamiast polegać na pojedynczej sieci, badacze zadali pytanie: co jeśli potraktujemy każdy model jak eksperta z panelu i połączymy ich opinie? Ten pomysł, zwany agregacją lub uczeniem zespołowym, jest powszechny w uczeniu maszynowym, ale często realizowany prostym głosowaniem lub uśrednianiem. Tutaj zespół zastosował bardziej elastyczną rodzinę narzędzi znanych jako operatory Ordered Weighted Averaging (OWA). Dla każdej możliwej diagnozy OWA bierze prawdopodobieństwa wygenerowane przez wszystkie sieci, sortuje je od najwyższego do najniższego, a następnie miesza je przy użyciu starannie dobranego zestawu wag. W praktyce daje to większy wpływ modelom bardziej pewnym swojej odpowiedzi, przy jednoczesnym uwzględnieniu pozostałych. Sama ta agregacja przyniosła dramatyczny wzrost dokładności ogólnej — z około 68% dla najlepszego pojedynczego modelu do ponad 93% po połączeniu wyników sieci przy użyciu podstawowego schematu OWA.
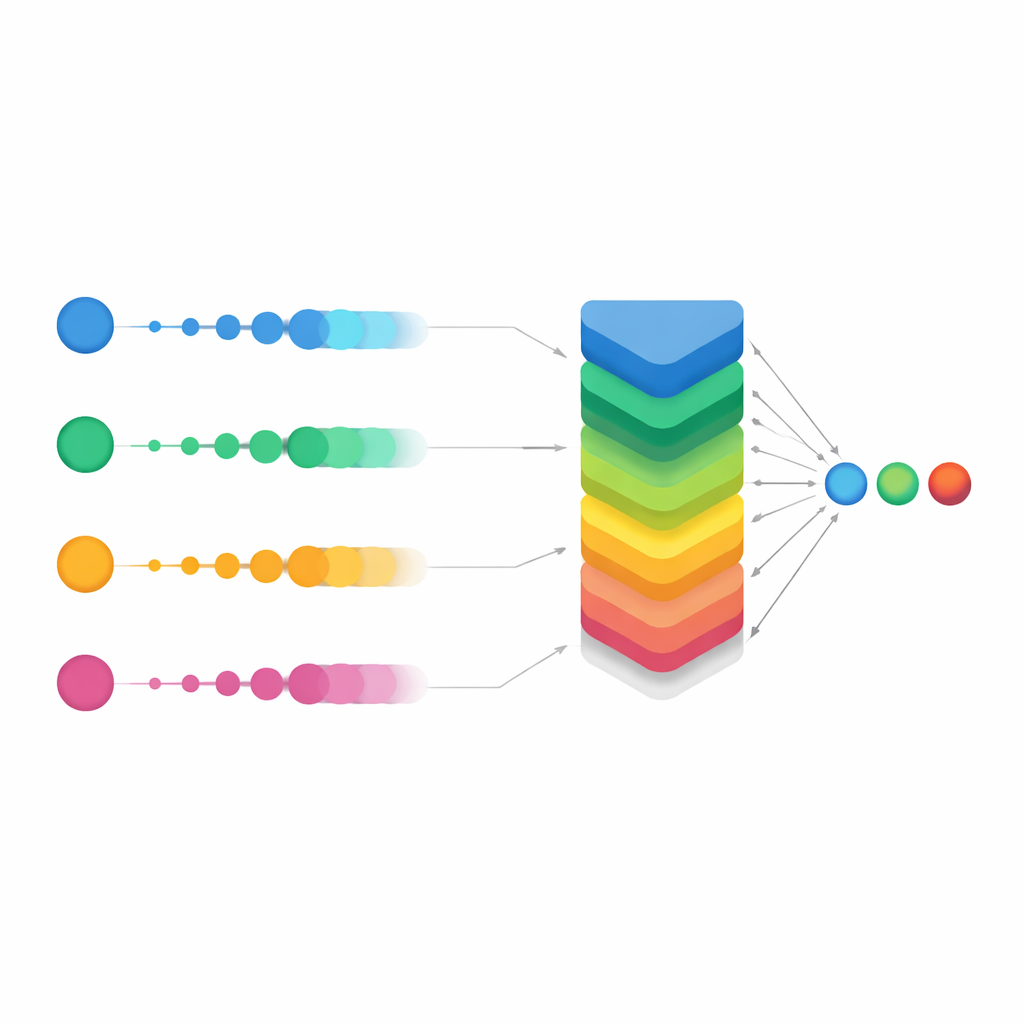
Wygładzanie głosu w trudnych przypadkach
Główną innowacją badania była ulepszona wersja nazwana Smooth OWA. Zamiast traktować każde prawdopodobieństwo modelu w izolacji, Smooth OWA delikatnie „wygładza” każdą wartość, korzystając z sąsiednich wyników, zanim zastosuje ważone łączenie. Zasady wygładzania zapożyczono z klasycznych formuł całkowania numerycznego, zwanych kwadraturami Newtona–Cotesa, które zwykle stosuje się do precyzyjnych obliczeń pól. Przeniesione do tego kontekstu pomagają wyrównać niestabilne lub graniczne przewidywania między modelami. Choć dodatkowy zysk w porównaniu ze standardowym OWA był umiarkowany — rzędu pół punktu procentowego w dokładności — to był konsekwentny w powtarzanych testach i podniósł wydajność do około 94%. Co ważne, macierze pomyłek pokazały wyraźny spadek błędnych klasyfikacji we wszystkich pięciu klasach, zwłaszcza w przypadku najrzadszych chorób. W niektórych grupach wskaźniki poprawnego rozpoznania wzrosły z około dwóch trzecich przy najlepszym pojedynczym modelu do znacznie ponad 90% przy zastosowaniu Smooth OWA.
Co to oznacza dla pacjentów i lekarzy
Dla osoby niebędącej specjalistą kluczowy komunikat jest taki: żaden pojedynczy model sztucznej inteligencji nie musi być perfekcyjny, aby mieć wartość kliniczną. Poprzez staranne łączenie kilku dobrych, lecz niedoskonałych modeli i delikatne stabilizowanie ich wyników, badacze przekształcili zestaw „całkiem dobrych” narzędzi w jedno bardzo skuteczne wsparcie decyzyjne. Podejście Smooth OWA poradziło sobie z małym, niezrównoważonym zbiorem danych i mimo to osiągnęło poziomy wydajności trudne do uzyskania w inny sposób. Chociaż prace są nadal na etapie badań i wymagają walidacji w większych, wieloośrodkowych badaniach zanim będą mogły kierować opieką nad pacjentem, wskazują one wyraźną drogę naprzód: przyszłe systemy diagnostyczne dla rzadkich chorób oczu mogą opierać się nie na jednym algorytmie, lecz na skoordynowanej „radzie” algorytmów, których wspólny osąd jest zarówno bardziej trafny, jak i bardziej wiarygodny.
Cytowanie: Rachwał, A., Rachwał, A., Powroźnik, P. et al. Application of smooth OWA operators to classification of retinitis pigmentosa. Sci Rep 16, 11995 (2026). https://doi.org/10.1038/s41598-026-41840-5
Słowa kluczowe: retinitis pigmentosa, uczenie głębokie, obrazowanie siatkówki, metody zespołowe, Sztuczna inteligencja w diagnostyce medycznej