Clear Sky Science · fr
Application des opérateurs OWA lissés à la classification de la rétinite pigmentaire
Pourquoi cela importe pour la vue
Perdre progressivement la vue à cause d’une maladie oculaire héréditaire est une perspective effrayante, et un diagnostic précoce de ces affections est crucial pour préserver la vision. Cette étude examine comment l’intelligence artificielle moderne peut aider les médecins à distinguer plusieurs troubles rétiniens rares mais graves, dont la rétinite pigmentaire, à partir de photographies détaillées du fond de l’œil. En trouvant une manière plus intelligente de combiner les jugements de nombreux modèles informatiques différents, les chercheurs montrent que les ordinateurs peuvent repérer ces maladies de façon beaucoup plus fiable qu’auparavant, même lorsque le nombre d’images de patients disponibles est faible.
Détecter la maladie sur des photos du fond d’œil
La rétinite pigmentaire regroupe des affections génétiques qui détruisent progressivement les cellules photoréceptrices de la rétine. Les patients remarquent souvent d’abord des difficultés à voir la nuit, puis une perte du champ visuel latéral, et certains deviennent finalement aveugles. Des pathologies apparentées, comme la dystrophie cône-bâtonnets et le syndrome d’Usher, peuvent présenter un aspect similaire sur les images rétiniennes et partager des motifs visuels subtils. Dans cette étude, des spécialistes d’un centre médical à Lublin, en Pologne, ont collecté des images ultra-grand-angle de la rétine provenant de 186 patients atteints de ces affections, ainsi que des images d’yeux sains extraites d’une base de données distincte. Il en a résulté une tâche de classification à cinq classes : deux variantes génétiques de rétinite pigmentaire, la dystrophie cône-bâtonnets, le syndrome d’Usher et des témoins sains. Le jeu de données était petit et déséquilibré, reflétant la rareté en conditions réelles — certaines catégories comptaient bien plus d’exemples que d’autres, rendant la tâche particulièrement difficile.
Apprendre aux machines à lire la rétine
Pour interpréter ces images, les auteurs se sont tournés vers des systèmes puissants de reconnaissance d’images développés initialement pour des photos du quotidien : des réseaux de neurones convolutionnels et des modèles plus récents basés sur des transformeurs. Ils ont testé plusieurs architectures, notamment EfficientNet, ResNet, VGG, Inception et deux versions du Vision Transformer. Chaque réseau a d’abord été préentraîné sur une large base d’images généraliste, puis affiné sur les images rétiniennes, une stratégie connue sous le nom d’apprentissage par transfert. Des augmentations de données classiques, comme le retournement, la rotation et des distorsions légères, ont aidé les modèles à gérer les différences d’appareils d’imagerie et d’anatomie des patients. Même avec ces techniques avancées, le meilleur modèle unique a correctement classé seulement environ les deux tiers des cas de test, et les performances étaient nettement plus faibles pour les catégories de maladies les plus rares.
Laisser plusieurs modèles voter ensemble
Plutôt que de se fier à un seul réseau, les chercheurs se sont demandé : et si l’on considérait chaque modèle comme un expert d’un panel et que l’on combinait leurs opinions ? Cette idée, appelée agrégation ou apprentissage d’ensemble, est courante en apprentissage automatique mais est souvent mise en œuvre par un vote simple ou une moyenne. Ici, l’équipe a utilisé une famille d’outils plus souple connue sous le nom d’opérateurs d’Ordered Weighted Averaging (OWA). Pour chaque diagnostic possible, OWA prend les probabilités produites par tous les réseaux, les trie de la plus élevée à la plus faible, puis les mélange avec un ensemble de poids soigneusement choisi. En pratique, cela donne plus d’influence aux modèles qui sont plus confiants, tout en tenant compte des autres. Cette agrégation a à elle seule produit un bond spectaculaire de la précision globale, passant d’environ 68 % pour le meilleur modèle individuel à plus de 93 % lorsque les sorties des réseaux ont été combinées avec un schéma OWA basique.
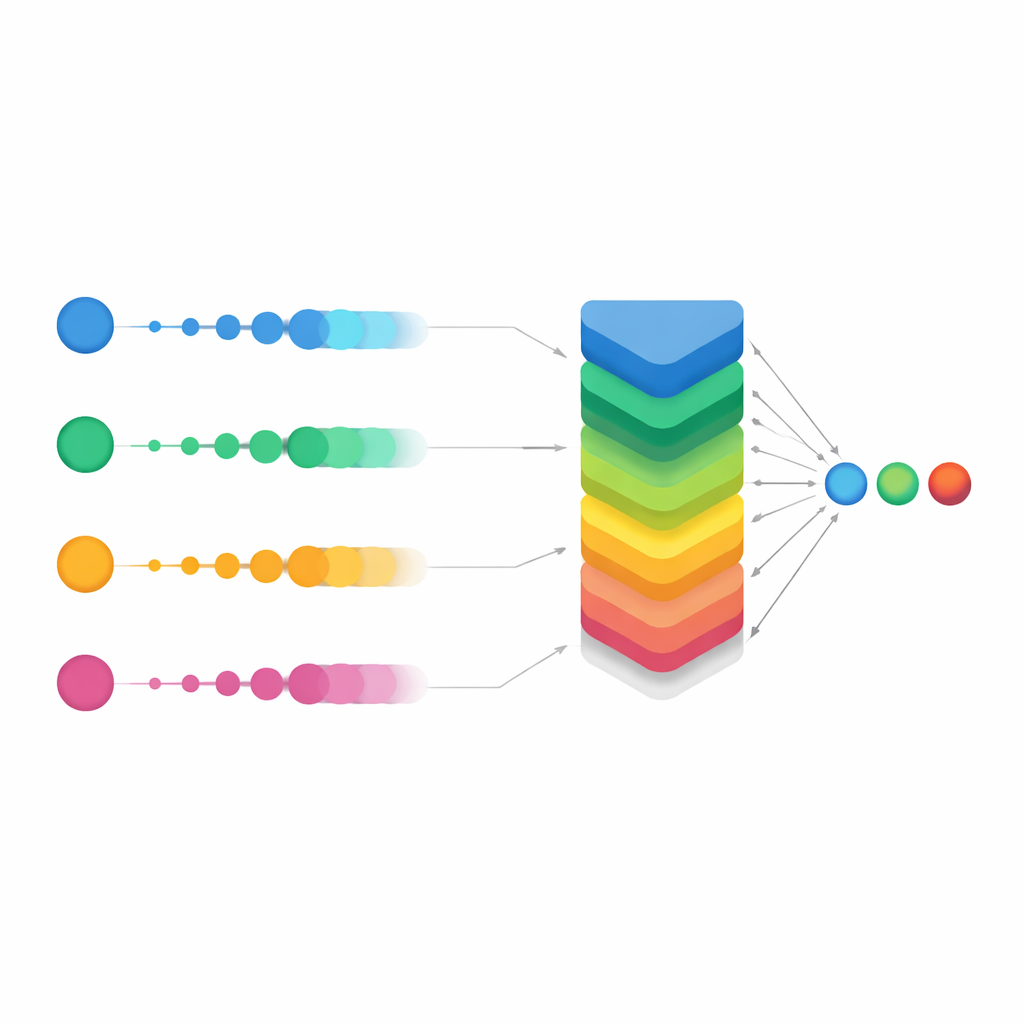
Lisser le vote pour les cas difficiles
L’innovation principale de l’étude est une version affinée appelée Smooth OWA. Plutôt que de traiter chaque probabilité de modèle isolément, Smooth OWA « lisse » légèrement chaque valeur en utilisant ses voisines avant d’appliquer le mélange pondéré. Les règles de lissage sont empruntées à des formules classiques d’intégration numérique, connues sous le nom de quadratures de Newton–Cotes, normalement utilisées pour des calculs d’aires précis. Transposées à ce contexte, elles permettent d’atténuer des prédictions instables ou limites entre les modèles. Si le gain supplémentaire par rapport à l’OWA standard est modeste — de l’ordre d’un demi-point de pourcentage en précision — il a été régulier à travers les tests répétés et a porté la performance à environ 94 %. De manière cruciale, les matrices de confusion ont montré que les erreurs de classification ont chuté fortement sur les cinq classes, en particulier pour les maladies les plus rares. Dans certains groupes, les taux de reconnaissance correcte sont passés d’environ deux tiers avec le meilleur modèle unique à bien au-delà de 90 % avec Smooth OWA.
Ce que cela signifie pour les patients et les médecins
Pour un non-spécialiste, le message clé est qu’aucun modèle d’intelligence artificielle unique n’a besoin d’être parfait pour être cliniquement utile. En combinant soigneusement plusieurs modèles bons mais imparfaits et en stabilisant légèrement leurs sorties, les chercheurs ont transformé un ensemble d’outils « assez bons » en un aide à la décision très performant. Leur approche Smooth OWA a géré un jeu de données petit et déséquilibré et atteint des niveaux de performance difficiles à obtenir autrement. Bien que ce travail soit encore au stade de la recherche et doive être validé dans des études plus larges et multicentriques avant d’orienter la prise en charge réelle des patients, il suggère une voie claire : les futurs systèmes diagnostiques pour les maladies oculaires rares pourraient ne pas reposer sur un seul algorithme, mais sur un « conseil » coordonné d’algorithmes dont le jugement collectif est à la fois plus précis et plus fiable.
Citation: Rachwał, A., Rachwał, A., Powroźnik, P. et al. Application of smooth OWA operators to classification of retinitis pigmentosa. Sci Rep 16, 11995 (2026). https://doi.org/10.1038/s41598-026-41840-5
Mots-clés: rétinite pigmentaire, apprentissage profond, imagerie rétinienne, méthodes d’ensemble, IA pour le diagnostic médical