Clear Sky Science · sv
Ett minimalt återkommande neuralt nät modellerar robustheten hos blandad träning vid motorisk sekvensinlärning
Varför hur vi övar spelar roll
När vi lär oss en ny fysisk färdighet — som att spela piano, skriva snabbare eller återlära rörelser efter en stroke — antar vi ofta att fler repetition alltid är bättre. Tränare och terapeuter har emellertid länge noterat ett paradoxalt fenomen: att växla mellan olika rörelser under träning kan kännas svårare i stunden men leder till bättre prestation senare. Denna studie använder en enkel datorbaserad modell av hjärnan för att ställa en grundläggande fråga: kan fördelen med "uppblandad" träning uppstå ur en mycket grundläggande inlärningsmekanism, utan några komplicerade biologiska tillägg?
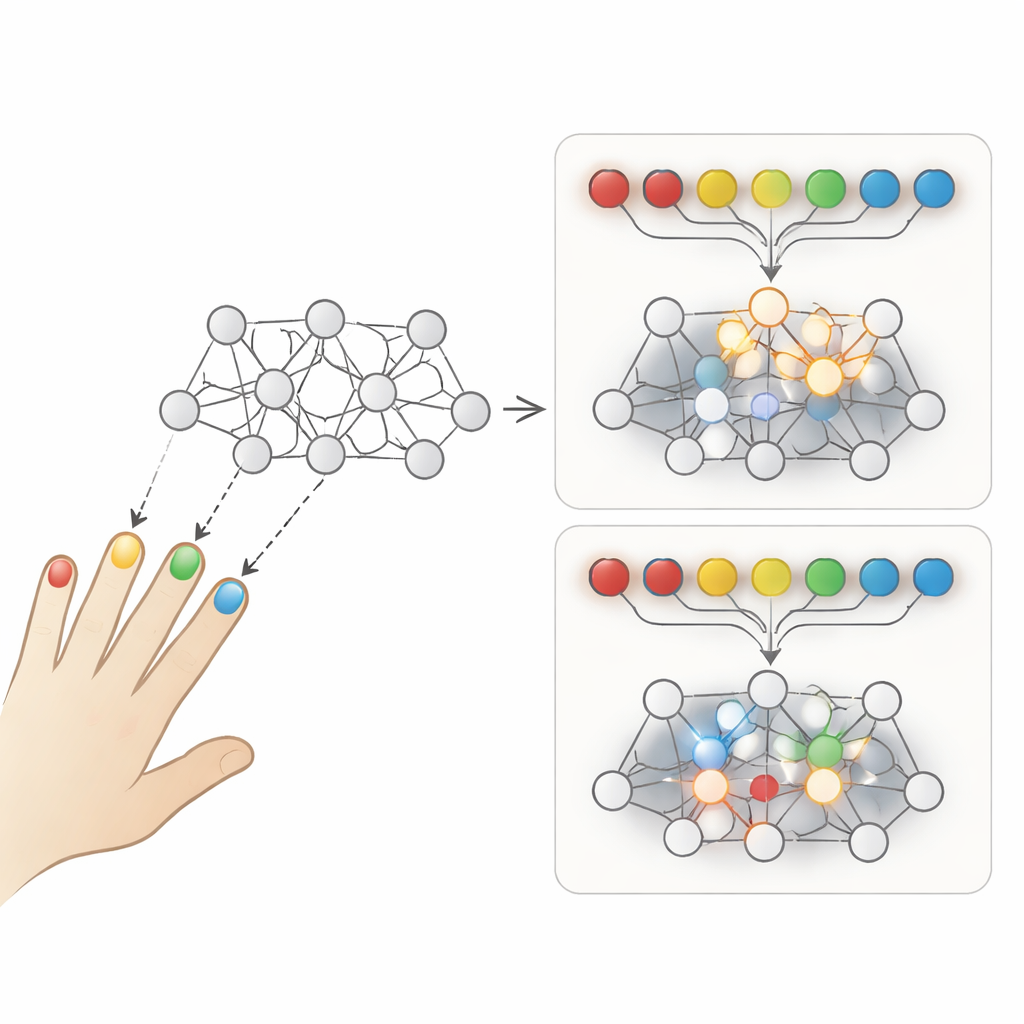
Två sätt att öva samma färdighet
Författarna fokuserar på en klassisk jämförelse mellan två träningsstilar. Vid repetitiv träning övar du en rörelsesekvens om och om igen innan du går vidare till nästa — till exempel genom att upprepa samma fingerkombination många gånger i följd. Vid blandad träning är olika sekvenser omblandade från försök till försök, så du ständigt byter vilket mönster du utför. Människor ser ofta bättre ut under repetitiv träning, eftersom den aktuella sekvensen känns smidigare och lättare. Men när man testar senare minns gruppen som tränat blandat vanligen mer och anpassar sig bättre till nya situationer. Denna förbryllande avvägning speglar ett välkänt problem inom artificiell intelligens kallat katastrofalt glömska, där en modell som tränas på uppgifter en efter en skriver över tidigare inlärt material.
Ett litet hjärninspirerat nätverk
För att undersöka vad som driver dessa skillnader byggde forskarna ett extremt enkelt återkommande neuralt nätverk, känt som ett Elman-nätverk. Det får en kort serie "fingertappar" som input och lär sig generera den korrekta sekvensen av tapp som output, vilket efterliknar en seriefinger-tapping-uppgift som används i experiment om motorisk inlärning. Först förtränade de nätverket på en uppsättning slumpmässiga sekvenser för att få det ur sitt "spädbarns"-stadium. Sedan gjorde de två identiska kopior. Den ena kopian övade tre nya sekvenser i repetitiva block, medan den andra övade samma tre sekvenser i en blandad ordning, försök för försök. Bortsett från träningsordningen var allt annat om de två näten lika, inklusive inlärningsregeln och mängden träning.
Snabba vinster, sköra minnen
Under träningen minskade det repetitiva nätverket sina fel snabbare. Varje gång en ny sekvens introducerades steg dess prestation upp efter en kort anpassningsperiod och slutligen slog den det blandade nätverket på den senast tränade sekvensen. Men när träningen avslutats och forskarna testade alla tre sekvenserna framträdde en mer dämpad bild: vid repetitiv träning hade den första och andra sekvensen i stor utsträckning skrivits över av den tredje. I kontrast presterade det blandade nätverket jämnare över alla tre sekvenser, vilket tyder på att dess interna minnesspår var mindre sårbara för att bli undanträngda. Samma mönster uppträdde när näten ombads utföra 100 nya, otränade sekvenser. Båda hade blivit något sämre på att generalisera, men det blandade nätverket förblev märkbart bättre, vilket indikerar att dess interna representationer var mindre snävt ställda in på de tränade mönstren.
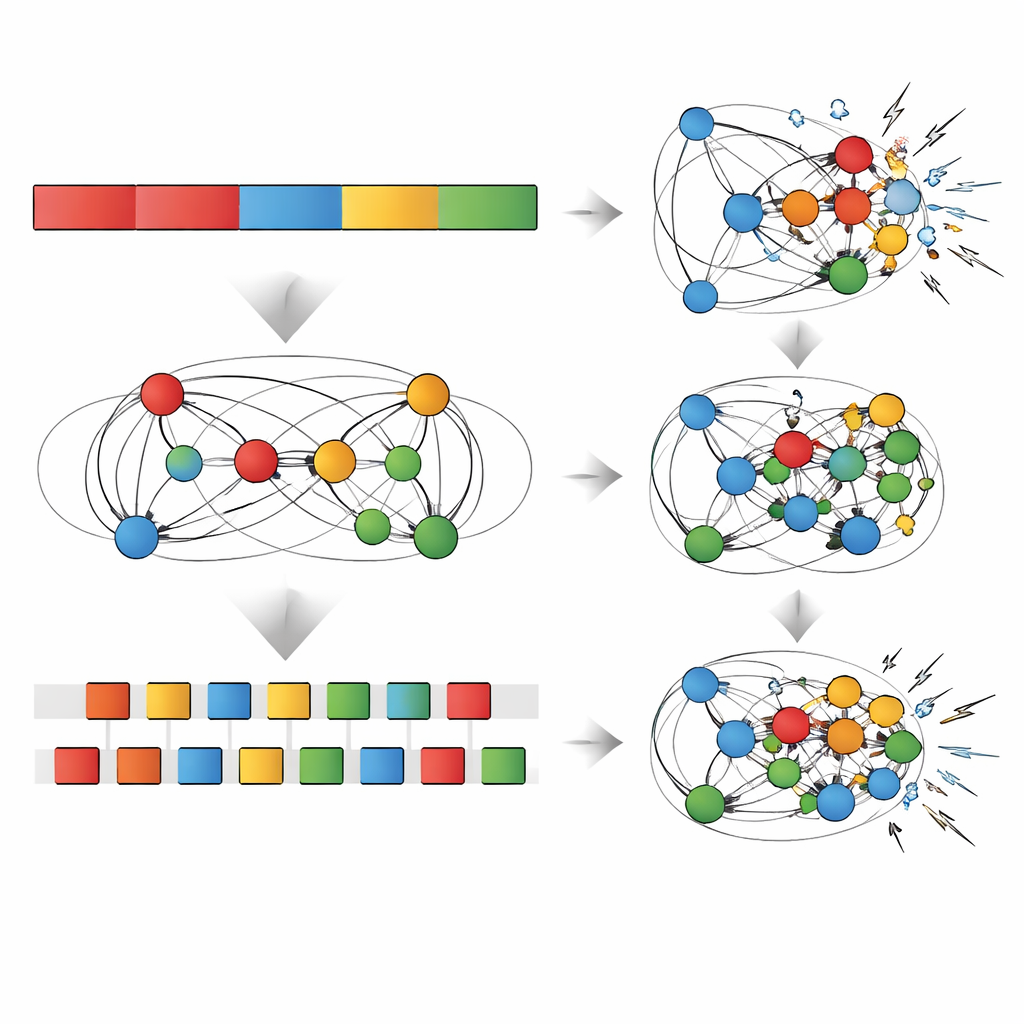
Test av hur tåliga minnena är
Teamet utsatte sedan båda näten för en serie "stressprov" utformade för att efterlikna verkliga påfrestningar på minnet. De tillsatte gradvis slumpmässigt brus i nätverkens kopplingar, kapade bort en del av dessa kopplingar (ett beskärningstest), eller tvingade näten att lära sig ännu en ny sekvens och observerade hur prestationen förändrades. I varje fall försvann den uppenbara fördelen med repetitiv träning på den senaste sekvensen snabbt: en aning brus, beskärning eller ny inlärning var nog för att erodera dessa vinster och sänka prestationen till — eller till och med under — nivåer hos det blandade nätverket. Däremot var generaliseringsfördelen som skapades av blandad träning mer motståndskraftig och överlevde måttlig brus, beskärning och extra träning. I vissa fall förbättrade beskärning till och med förmågan att generalisera, vilket ekar fynd som visar att ett avskalad nätverk kan hjälpa det att fokusera på de mest meningsfulla mönstren.
En enkel princip med bred räckvidd
Tillsammans visar resultaten att ett mycket grundläggande återkommande nätverk — utan detaljerade biologiska inlärningsregler eller särskilda "kontext"-moduler — naturligt reproducerar de viktigaste egenskaperna hos blandad träning som ses vid mänsklig motorisk inlärning. Repetitiv träning ger snabba men sköra vinster, byggda på överspecialiserade interna koder som lätt störs och som stör andra minnen. Blandad träning tvingar systemet att jonglera flera kontexter samtidigt och driver det mot mer robusta, allmänt användbara representationer som stödjer både kvarhållning och överföring till nya sekvenser. För vardagliga lärande och rehabiliteringsspecialister förstärker detta arbete ett praktiskt budskap: att blanda uppgifter under träning kan kännas svårare och långsammare, men det hjälper hjärnan (och hjärninspirerade maskiner) att bygga färdigheter som håller och kan anpassas.
Citering: Song, Y., Kim, H. & Kim, T. A minimal recurrent neural network models the robustness of interleaved practice on motor sequence learning. Sci Rep 16, 10068 (2026). https://doi.org/10.1038/s41598-026-40162-w
Nyckelord: motorisk inlärning, blandad träning, återkommande neurala nätverk, katastrofalt glömska, rehabilitering av färdigheter