Clear Sky Science · nl
Een minimale recurrente neuraal netwerk modelleert de robuustheid van afgewisselde oefening bij het leren van motorische reeksen
Waarom de manier van oefenen ertoe doet
Als we een nieuwe fysieke vaardigheid leren—zoals piano spelen, sneller typen of opnieuw leren bewegen na een beroerte—gaan we er vaak van uit dat meer herhaling altijd beter is. Toch merken coaches en therapeuten al lang een paradox op: het door elkaar oefenen van verschillende bewegingen voelt op het moment moeilijker, maar leidt later tot betere prestaties. Deze studie gebruikt een eenvoudig computermodel van de hersenen om een fundamentele vraag te stellen: kan dat voordeel van “door elkaar” oefenen voortkomen uit een zeer basaal leermechanisme, zonder ingewikkelde biologische toevoegingen?
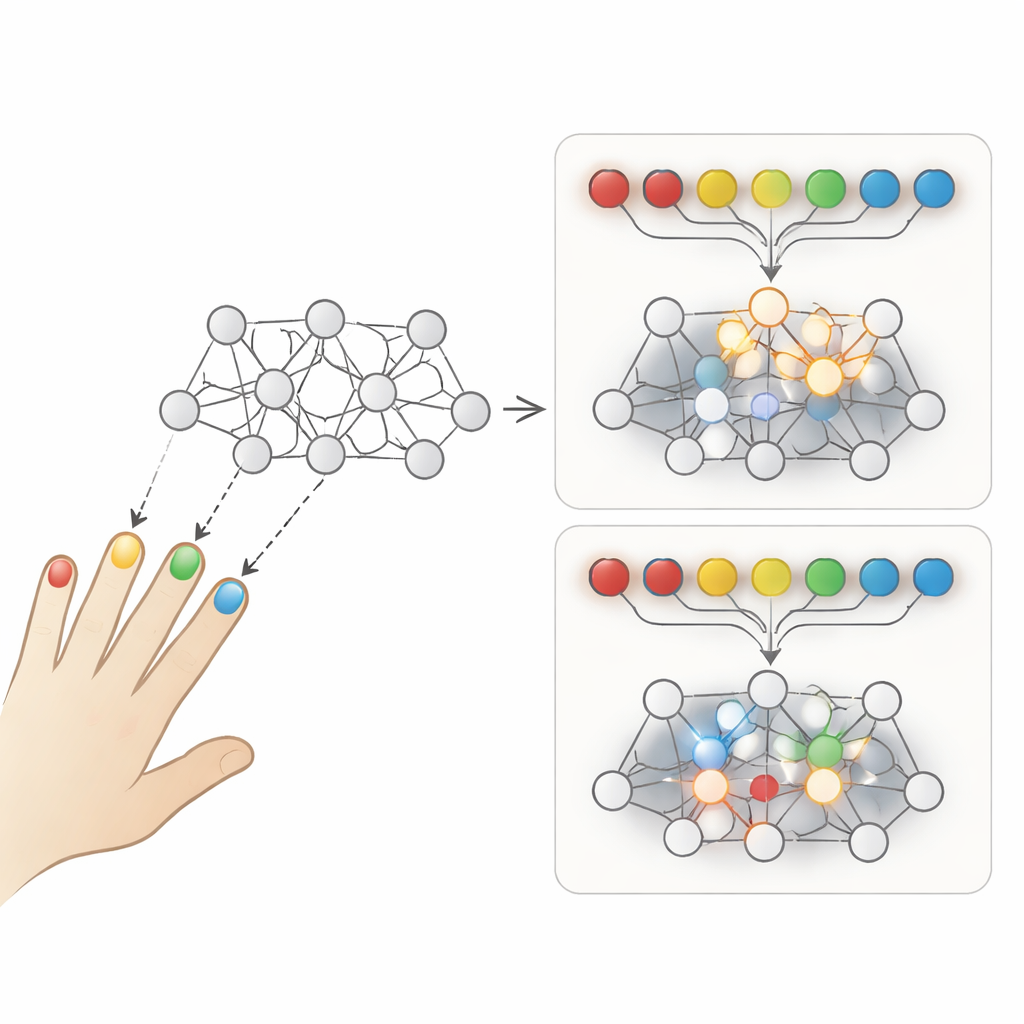
Twee manieren om dezelfde vaardigheid te oefenen
De auteurs richten zich op een klassieke vergelijking tussen twee oefenstijlen. Bij repetitieve oefening oefen je één bewegingssequentie steeds opnieuw voordat je naar de volgende schakelt—bijvoorbeeld hetzelfde vingerpatroon vele keren achter elkaar tappen. Bij afgewisselde oefening worden verschillende sequenties van proef tot proef door elkaar gehusseld, zodat je constant wisselt welke patroon je uitvoert. Mensen lijken tijdens repetitieve oefening beter te presteren, omdat de huidige sequentie vloeiender en makkelijker aanvoelt. Maar bij een latere test herinnert de groep met afgewisselde oefening zich meestal meer en past zich beter aan nieuwe situaties aan. Deze raadselachtige afweging weerspiegelt een bekend probleem in kunstmatige intelligentie, catastrofaal vergeten, waarbij een model dat taken na elkaar leert eerdere kennis overschrijft.
Een piepklein hersenachtig netwerk
Om te onderzoeken wat deze verschillen veroorzaakt, bouwden de onderzoekers een uiterst eenvoudig recurrent neuraal netwerk, bekend als een Elman-netwerk. Het krijgt een korte reeks “vingertikken” als input en leert de juiste tikvolgorde als output te genereren, nabootsend een seriële vinger-tiktaak die in motorische leersettingen wordt gebruikt. Eerst pretrainden ze dit netwerk op een set willekeurige sequenties om het uit zijn "babyfase" te halen. Daarna maakten ze twee identieke kopieën. De ene kopie oefende drie nieuwe sequenties in repetitieve blokken, terwijl de andere dezelfde drie sequenties proef voor proef in afgewisselde volgorde oefende. Behalve de volgorde van oefenen was alles aan de twee netwerken hetzelfde, inclusief de leerscore en de hoeveelheid oefening.
Snelle winst, broze herinneringen
Tijdens training verminderde het netwerk met repetitieve oefening zijn fouten sneller. Elke keer dat een nieuwe sequentie werd geïntroduceerd, verbeterde de prestatie na een korte aanpassingsperiode en uiteindelijk deed het beter dan het afgewisselde netwerk op de meest recent geoefende sequentie. Maar toen de training eindigde en de onderzoekers alle drie de sequenties testten, ontstond een relativerend beeld: bij repetitieve oefening waren de eerste en tweede sequenties grotendeels overschreven door de derde. Daarentegen presteerde het afgewisselde netwerk gelijkmatiger over alle drie de sequenties, wat suggereert dat de interne geheugensporen minder kwetsbaar waren om opzij geduwd te worden. Hetzelfde patroon verscheen toen de netwerken 100 nieuwe, niet-geoefende sequenties moesten uitvoeren. Beide waren iets minder goed geworden in generaliseren, maar het afgewisselde netwerk bleef duidelijk beter, wat aangeeft dat zijn interne representaties minder smal afgestemd waren op de geoefende patronen.
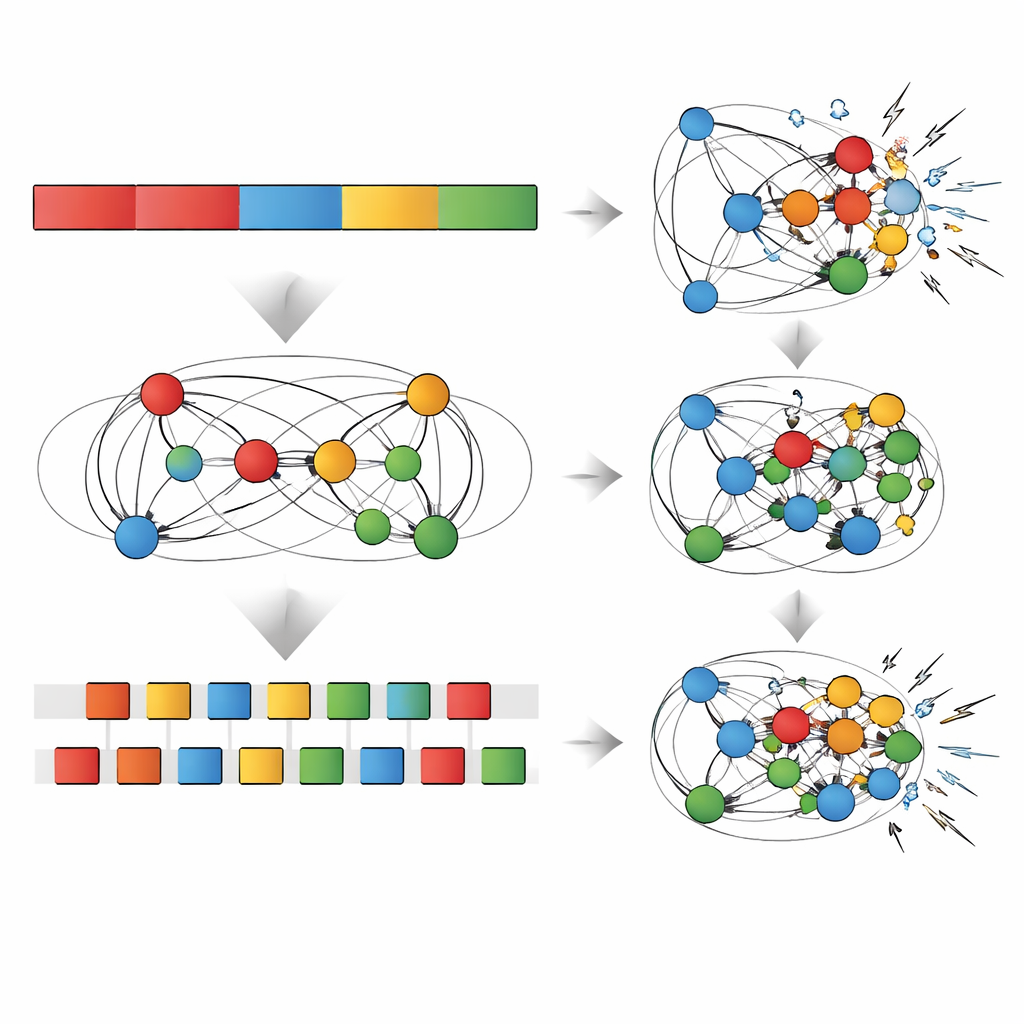
Testen hoe taai de herinneringen zijn
Het team onderwierp beide netwerken vervolgens aan een reeks "stresstests" die echte werelduitdagingen voor geheugen moesten nabootsen. Ze voegden geleidelijk willekeurige ruis toe aan de verbindingen van het netwerk, knipten een fractie van die verbindingen weg (een snoeitest), of dwongen de netwerken om nog een nieuwe sequentie te leren en keken hoe de prestaties veranderden. In elk geval vervaagde het schijnbare voordeel van repetitieve oefening op de meest recente sequentie snel: een beetje ruis, snoeiwerk of nieuwe leerstof was genoeg om deze winst te eroderen en de prestatie terug te brengen tot—of zelfs onder—het niveau van het afgewisselde netwerk. Daarentegen was het generalisatievoordeel dat door afgewisselde oefening ontstond veerkrachtiger en overleefde matige ruis, snoeiingen en extra training. In sommige gevallen verbeterde snoeien zelfs het generalisatievermogen, wat echoot met bevindingen dat het slanker maken van een netwerk kan helpen zich te concentreren op de meest betekenisvolle patronen.
Een eenvoudig principe met brede reikwijdte
Gezamenlijk laten de resultaten zien dat een zeer eenvoudig recurrent netwerk—zonder gedetailleerde biologische leerregels of speciale "context"-modules—natuurlijk de kernkenmerken van afgewisselde oefening nabootst die bij menselijk motorisch leren worden gezien. Repetitieve oefening levert snelle maar kwetsbare winst op, gebaseerd op overgespecialiseerde interne codes die gemakkelijk verstoord worden en die interfereren met andere herinneringen. Afgewisselde oefening dwingt het systeem meerdere contexten tegelijkertijd te hanteren, waardoor het naar meer robuuste, breed toepasbare representaties wordt geduwd die zowel retentie als overdracht naar nieuwe sequenties ondersteunen. Voor alledaagse leerlingen en revalidatiespecialisten versterkt dit werk een praktische boodschap: taken door elkaar oefenen kan moeilijker en langzamer aanvoelen, maar het helpt de hersenen (en hersengeïnspireerde machines) vaardigheden op te bouwen die blijvend zijn en zich kunnen aanpassen.
Bronvermelding: Song, Y., Kim, H. & Kim, T. A minimal recurrent neural network models the robustness of interleaved practice on motor sequence learning. Sci Rep 16, 10068 (2026). https://doi.org/10.1038/s41598-026-40162-w
Trefwoorden: motorisch leren, afgewisselde oefening, recurrente neurale netwerken, catastrofaal vergeten, vaardigheidsrevalidatie