Clear Sky Science · es
Una red neuronal recurrente mínima modela la robustez de la práctica entrelazada en el aprendizaje de secuencias motoras
Por qué importa cómo practicamos
Cuando aprendemos una nueva habilidad física —como tocar el piano, escribir más rápido o reaprender a moverse tras un ictus— solemos suponer que más repeticiones siempre son mejores. Sin embargo, entrenadores y terapeutas llevan tiempo observando una paradoja: mezclar distintos movimientos durante la práctica puede sentirse más difícil en el momento, pero conduce a un mejor rendimiento después. Este estudio utiliza un modelo informático muy sencillo del cerebro para plantear una pregunta profunda: ¿puede ese beneficio de la práctica “mezclada” surgir a partir de un mecanismo de aprendizaje muy básico, sin añadidos biológicos complejos?
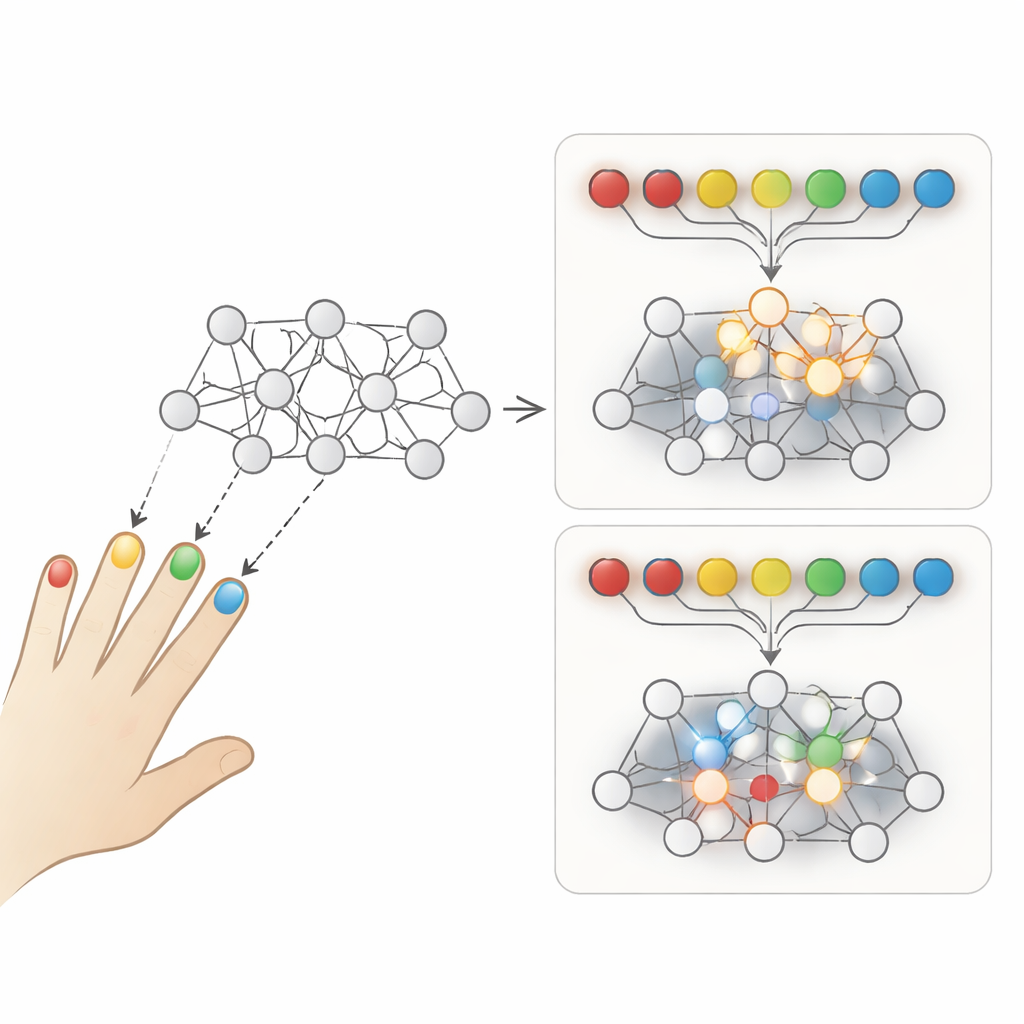
Dos formas de practicar la misma habilidad
Los autores se centran en una comparación clásica entre dos estilos de práctica. En la práctica repetitiva, repites una secuencia de movimiento una y otra vez antes de cambiar a la siguiente —por ejemplo, golpear el mismo patrón con los dedos muchas veces seguidas. En la práctica entrelazada, diferentes secuencias se barajan de ensayo en ensayo, de modo que cambias constantemente el patrón que produces. La gente suele rendir mejor durante la práctica repetitiva, porque la secuencia actual se siente más fluida y fácil. Pero al evaluarse más tarde, el grupo entrelazado por lo general recuerda más y se adapta mejor a situaciones nuevas. Este trade-off desconcertante refleja un problema bien conocido en la inteligencia artificial llamado olvido catastrófico, donde un modelo entrenado en tareas sucesivas sobrescribe lo aprendido anteriormente.
Una red pequeña inspirada en el cerebro
Para investigar qué impulsa estas diferencias, los investigadores construyeron una red neuronal recurrente extremadamente simple, conocida como red de Elman. Recibe como entrada una breve serie de “golpes con los dedos” y aprende a generar la secuencia correcta de toques como salida, imitando una tarea serial de digitación usada en experimentos de aprendizaje motor. Primero preentrenaron esta red con un conjunto de secuencias aleatorias para sacarla de su etapa “infantil”. Luego hicieron dos copias idénticas. Una copia practicó tres nuevas secuencias en bloques repetitivos, mientras que la otra practicó las mismas tres secuencias en orden entrelazado, ensayo a ensayo. Aparte del orden de práctica, todo sobre las dos redes era igual, incluida la regla de aprendizaje y la cantidad de práctica.
Ganancias rápidas, memorias frágiles
Durante el entrenamiento, la red de práctica repetitiva redujo sus errores más rápidamente. Cada vez que se introducía una nueva secuencia, su rendimiento subía tras un breve periodo de ajuste y finalmente superaba a la red entrelazada en la secuencia entrenada más recientemente. Pero cuando terminó el entrenamiento y los investigadores evaluaron las tres secuencias, emergió una imagen más sobria: bajo práctica repetitiva, la primera y la segunda secuencia habían sido en gran parte sobrescritas por la tercera. En contraste, la red entrelazada rindió de manera más uniforme en las tres secuencias, lo que sugiere que sus huellas de memoria internas eran menos vulnerables a ser desplazadas. El mismo patrón apareció cuando se pidió a las redes ejecutar 100 secuencias nuevas no entrenadas. Ambas empeoraron algo en la capacidad de generalizar, pero la red entrelazada se mantuvo notablemente mejor, indicando que sus representaciones internas estaban menos afinadas exclusivamente a los patrones practicados.
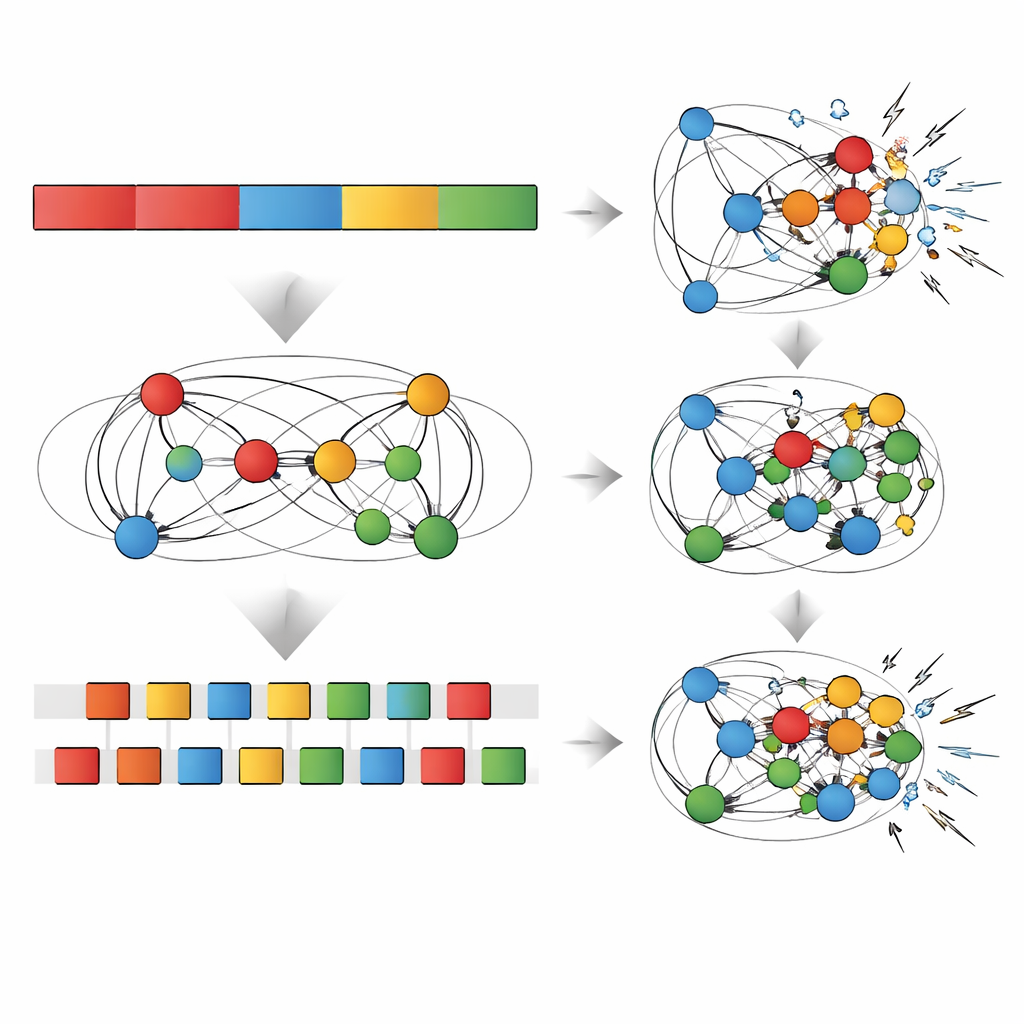
Poniendo a prueba la resistencia de las memorias
El equipo sometió entonces a ambas redes a una serie de “pruebas de estrés” diseñadas para imitar desafíos reales a la memoria. Fueron añadiendo gradualmente ruido aleatorio a las conexiones de la red, cortaron una fracción de esas conexiones (una prueba de poda), o forzaron a las redes a aprender otra nueva secuencia y observaron cómo cambiaba el rendimiento. En todos los casos, la aparente ventaja de la práctica repetitiva en la secuencia más reciente se desvaneció rápidamente: un poco de ruido, poda o aprendizaje nuevo bastaba para erosionar esas ganancias y bajar el rendimiento al nivel de —o incluso por debajo de— la red entrelazada. Por el contrario, la ventaja de generalización creada por la práctica entrelazada resultó más resistente, sobreviviendo a ruido moderado, poda y entrenamiento adicional. En algunos casos, la poda incluso mejoró la capacidad de generalizar, lo que recuerda hallazgos según los cuales adelgazar una red puede ayudarla a centrarse en los patrones más significativos.
Un principio simple con amplio alcance
En conjunto, los resultados muestran que una red recurrente muy básica —sin reglas de aprendizaje biológicas detalladas ni módulos especiales de “contexto”— reproduce de forma natural las características clave de la práctica entrelazada observadas en el aprendizaje motor humano. La práctica repetitiva produce ganancias rápidas pero frágiles, construidas sobre códigos internos sobreespecializados que se interrumpen con facilidad e interfieren con otros recuerdos. La práctica entrelazada obliga al sistema a gestionar múltiples contextos a la vez, empujándolo hacia representaciones más robustas y de uso más amplio que favorecen tanto la retención como la transferencia a nuevas secuencias. Para aprendices cotidianos y especialistas en rehabilitación, este trabajo refuerza un mensaje práctico: mezclar tareas durante la práctica puede parecer más difícil y más lento, pero ayuda al cerebro (y a las máquinas inspiradas en el cerebro) a construir habilidades que perduran y se adaptan.
Cita: Song, Y., Kim, H. & Kim, T. A minimal recurrent neural network models the robustness of interleaved practice on motor sequence learning. Sci Rep 16, 10068 (2026). https://doi.org/10.1038/s41598-026-40162-w
Palabras clave: aprendizaje motor, práctica entrelazada, redes neuronales recurrentes, olvido catastrófico, rehabilitación de habilidades