Clear Sky Science · de
Ein minimales rekurrentes neuronales Netz modelliert die Robustheit von interleaved Practice beim Erlernen motorischer Sequenzen
Warum die Art des Übens wichtig ist
Wenn wir eine neue körperliche Fertigkeit lernen – etwa Klavierspielen, schnelleres Tippen oder das Wiedererlernen von Bewegungen nach einem Schlaganfall – gehen wir oft davon aus, dass mehr Wiederholung stets besser ist. Trainer und Therapeutinnen beobachten jedoch seit langem ein Paradox: Das Durchmischen verschiedener Bewegungen während des Trainings fühlt sich im Augenblick oft schwerer an, führt aber später zu besseren Leistungen. Diese Studie verwendet ein einfaches Computermodell des Gehirns, um eine grundlegende Frage zu stellen: Kann dieser Vorteil des „durcheinander“ übens aus einem sehr einfachen Lernmechanismus entstehen, ohne aufwendige biologische Zusatzannahmen?
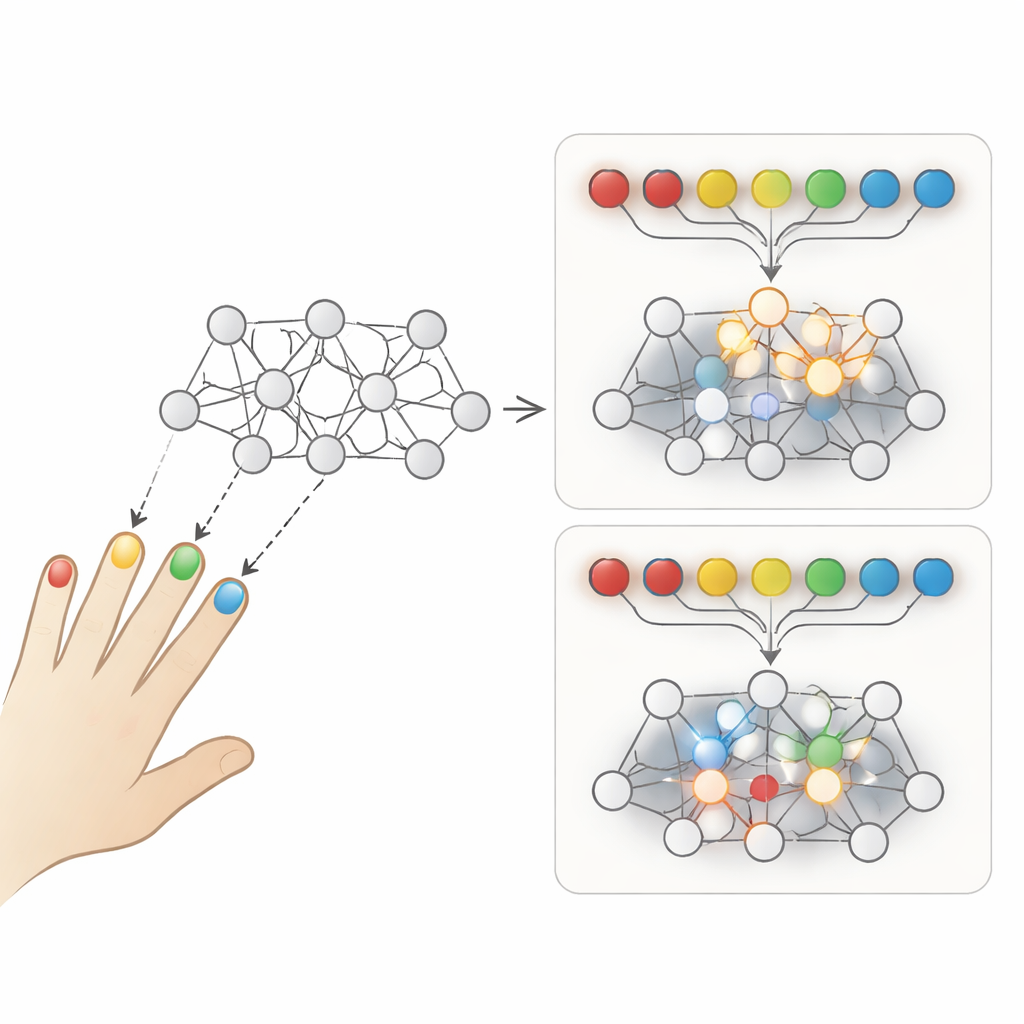
Zwei Arten, dieselbe Fertigkeit zu üben
Die Autoren konzentrieren sich auf einen klassischen Vergleich zwischen zwei Übungsstilen. Beim repetitiven Üben wiederholst du eine Bewegungssequenz immer wieder, bevor du zur nächsten übergehst – zum Beispiel dieselbe Fingerfolge viele Male hintereinander tippend. Beim interleaved Practice hingegen werden verschiedene Sequenzen von Versuch zu Versuch durchmischt, so dass du ständig wechselst, welches Muster du ausführst. Während des Trainings schneiden Menschen bei repetitivem Üben meist besser ab, weil die aktuelle Sequenz flüssiger und leichter erscheint. Bei Tests später erinnern sich jedoch Probanden aus der interleaved-Gruppe normalerweise mehr und passen sich besser an neue Situationen an. Dieser rätselhafte Zielkonflikt spiegelt ein bekanntes Problem der künstlichen Intelligenz wider, das als katastrophales Vergessen bezeichnet wird: Ein Modell, das Aufgaben nacheinander lernt, kann frühere Lerninhalte überschreiben.
Ein winziges, gehirninspiriertes Netzwerk
Um zu untersuchen, was diese Unterschiede antreibt, bauten die Forschenden ein extrem einfaches rekurrentes neuronales Netz, bekannt als Elman-Netz. Es erhält eine kurze Serie von „Fingeranschlägen“ als Eingabe und lernt, die korrekte Folge von Anschlägen als Ausgabe zu erzeugen – angelehnt an die serielle Finger-Tapping-Aufgabe, die in Experimenten zum motorischen Lernen verwendet wird. Zuerst wurden die Netzwerke an einer Menge zufälliger Sequenzen vortrainiert, um sie aus dem „Infant“-Zustand zu bringen. Dann machten die Forschenden zwei identische Kopien. Eine Kopie übte drei neue Sequenzen in repetitiven Blöcken, die andere übte dieselben drei Sequenzen in interleaved-Reihenfolge, Versuch für Versuch. Abgesehen von der Übungsreihenfolge war bei beiden Netzwerken alles gleich – inklusive der Lernregel und des Übungsumfangs.
Schnelle Fortschritte, fragile Erinnerungen
Während des Trainings reduzierte das repetitiv geübte Netzwerk seine Fehler schneller. Jedes Mal, wenn eine neue Sequenz eingeführt wurde, stieg seine Leistung nach einer kurzen Anpassungsphase deutlich an, und schließlich übertraf es das interleaved-Netzwerk bei der zuletzt trainierten Sequenz. Als das Training jedoch endete und die Forschenden alle drei Sequenzen testeten, zeigte sich ein ernüchternderes Bild: Beim repetitiven Üben waren die erste und zweite Sequenz weitgehend von der dritten überschrieben worden. Im Gegensatz dazu zeigte das interleaved-Netz bei allen drei Sequenzen eine gleichmäßigere Leistung, was darauf hindeutet, dass seine internen Gedächtnisspuren weniger anfällig dafür waren, verdrängt zu werden. Dasselbe Muster trat auf, als die Netzwerke gebeten wurden, 100 neue, nicht trainierte Sequenzen auszuführen. Beide verschlechterten sich etwas in ihrer Generalisierungsfähigkeit, doch das interleaved-Netz blieb deutlich besser, was darauf hinweist, dass seine internen Repräsentationen weniger eng auf die geübten Muster zugeschnitten waren.
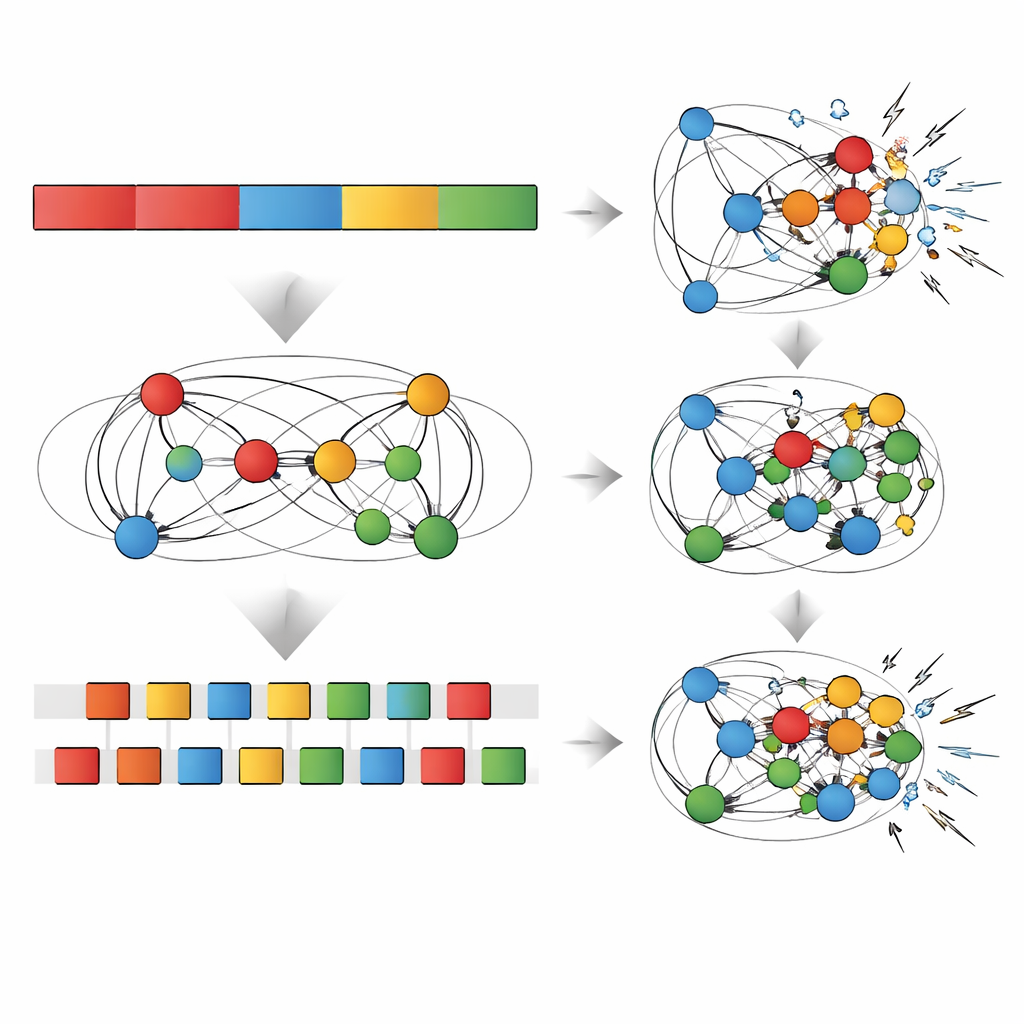
Wie robust sind die Erinnerungen?
Das Team unterzog beide Netzwerke anschließend einer Reihe von „Stresstests“, die reale Herausforderungen für Gedächtnis simulieren sollten. Sie fügten schrittweise zufälliges Rauschen zu den Verbindungen des Netzwerks hinzu, schnitten einen Teil dieser Verbindungen weg (Pruning-Test) oder zwangen die Netzwerke, noch eine weitere neue Sequenz zu lernen, und beobachteten, wie sich die Leistung veränderte. In jedem Fall verblasste der scheinbare Vorteil des repetitiven Übens für die zuletzt gelernte Sequenz schnell: Ein wenig Rauschen, Pruning oder neues Lernen reichte aus, um diese Gewinne zu verringern und die Leistung auf das Niveau des interleaved-Netzwerks – oder darunter – zu drücken. Dagegen war der Generalisierungsvorsprung durch interleaved Practice widerstandsfähiger und überstand moderates Rauschen, Pruning und zusätzliches Training. In einigen Fällen verbesserte Pruning sogar die Generalisierungsfähigkeit, was Befunde widerspiegelt, wonach ein Verschlanken eines Netzes ihm helfen kann, sich auf die bedeutendsten Muster zu konzentrieren.
Ein einfaches Prinzip mit großer Wirkung
Insgesamt zeigen die Ergebnisse, dass ein sehr einfaches rekurrentes Netz – ohne detaillierte biologische Lernregeln oder spezielle „Kontext“-Module – auf natürliche Weise die Kernmerkmale von interleaved Practice nachbildet, wie sie beim menschlichen motorischen Lernen beobachtet werden. Repetitives Üben liefert schnelle, aber brüchige Verbesserungen, die auf überspezialisierten internen Codes beruhen, die leicht gestört werden und andere Erinnerungen beeinträchtigen. Interleaved Practice zwingt das System, mehrere Kontexte gleichzeitig zu handhaben, und treibt es zu robusteren, breit einsetzbaren Repräsentationen, die sowohl Behalten als auch Transfer auf neue Sequenzen unterstützen. Für Alltagslernende und Rehabilitationsexpertinnen verstärkt diese Arbeit eine praktische Botschaft: Das Durchmischen von Aufgaben während des Trainings kann sich schwieriger und langsamer anfühlen, hilft dem Gehirn (und gehirninspirierten Maschinen) aber, Fertigkeiten aufzubauen, die dauerhaft sind und sich anpassen.
Zitation: Song, Y., Kim, H. & Kim, T. A minimal recurrent neural network models the robustness of interleaved practice on motor sequence learning. Sci Rep 16, 10068 (2026). https://doi.org/10.1038/s41598-026-40162-w
Schlüsselwörter: motorisches Lernen, interleaved Practice, rekurrente neuronale Netze, katastrophales Vergessen, Fähigkeitsrehabilitation