Clear Sky Science · en
A minimal recurrent neural network models the robustness of interleaved practice on motor sequence learning
Why the Way We Practice Matters
When we learn a new physical skill—like playing piano, typing faster, or relearning to move after a stroke—we often assume that more repetition is always better. Yet coaches and therapists have long noticed a paradox: shuffling different movements during practice can feel harder in the moment but leads to better performance later. This study uses a simple computer model of the brain to ask a deep question: can that benefit of “mixed-up” practice arise from a very basic learning mechanism, without any fancy biological add-ons?
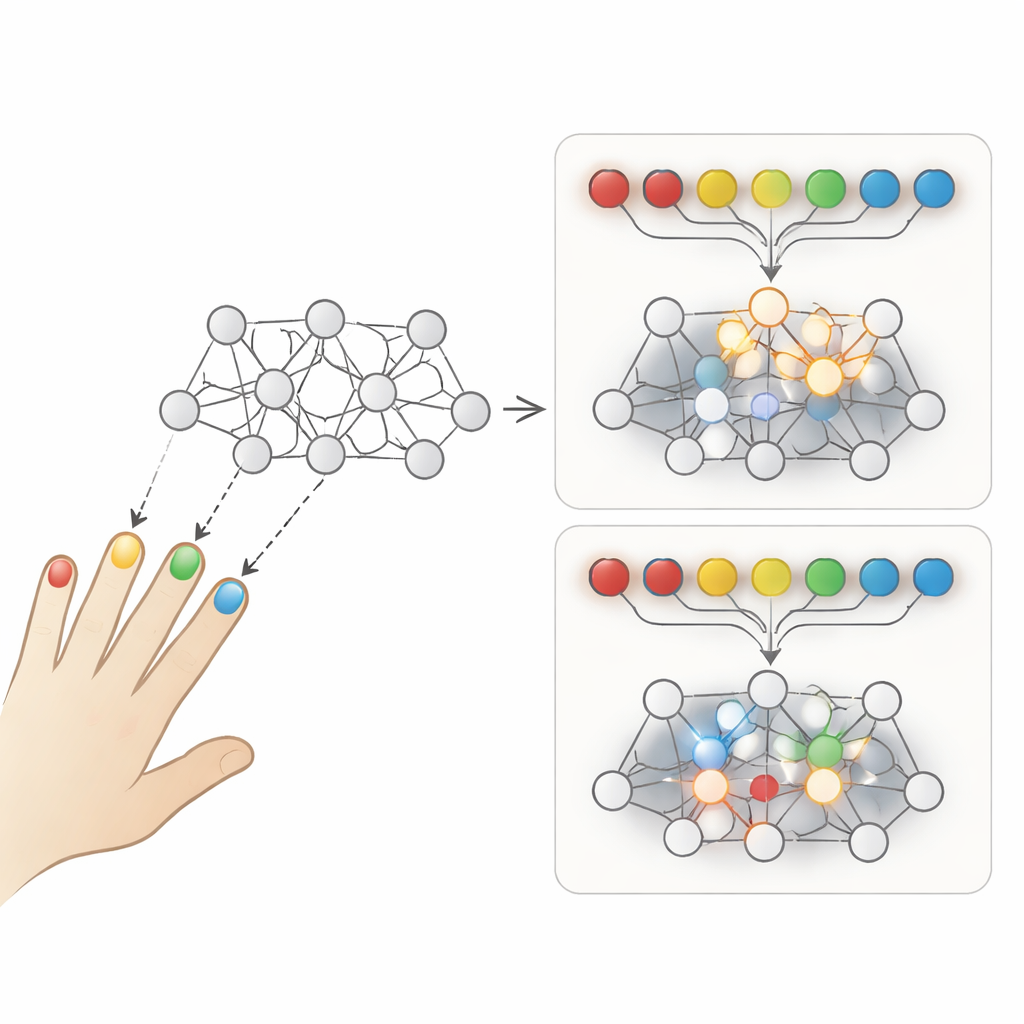
Two Ways to Practice the Same Skill
The authors focus on a classic comparison between two practice styles. In repetitive practice, you drill one movement sequence over and over before switching to the next—for example, tapping the same finger pattern many times in a row. In interleaved practice, different sequences are shuffled from trial to trial, so you constantly switch which pattern you produce. People typically look better during repetitive practice, because the current sequence feels smoother and easier. But when tested later, the interleaved group usually remembers more and adapts better to new situations. This puzzling trade-off mirrors a well-known problem in artificial intelligence called catastrophic forgetting, where a model trained on tasks one after another overwrites what it learned before.
A Tiny Brain-Inspired Network
To probe what drives these differences, the researchers built an extremely simple recurrent neural network, known as an Elman network. It receives a short series of “finger taps” as input and learns to generate the correct sequence of taps as output, mimicking a serial finger-tapping task used in motor-learning experiments. First, they pre-trained this network on a set of random sequences to get it out of its “infant” stage. Then they made two identical copies. One copy practiced three new sequences in repetitive blocks, while the other practiced the same three sequences in an interleaved order, trial by trial. Aside from the practice order, everything about the two networks was the same, including the learning rule and the amount of practice.
Fast Gains, Fragile Memories
During training, the repetitive-practice network reduced its errors more quickly. Each time a new sequence was introduced, its performance jumped up after a short adjustment period and eventually beat the interleaved network on the most recently trained sequence. But when training ended and the researchers tested all three sequences, a more sobering picture emerged: under repetitive practice, the first and second sequences had been largely overwritten by the third. In contrast, the interleaved network performed more evenly across all three sequences, suggesting that its internal memory traces were less vulnerable to being pushed aside. The same pattern appeared when the networks were asked to perform 100 new, untrained sequences. Both had become somewhat worse at generalizing, but the interleaved network stayed noticeably better, indicating that its internal representations were less narrowly tuned to the practiced patterns.
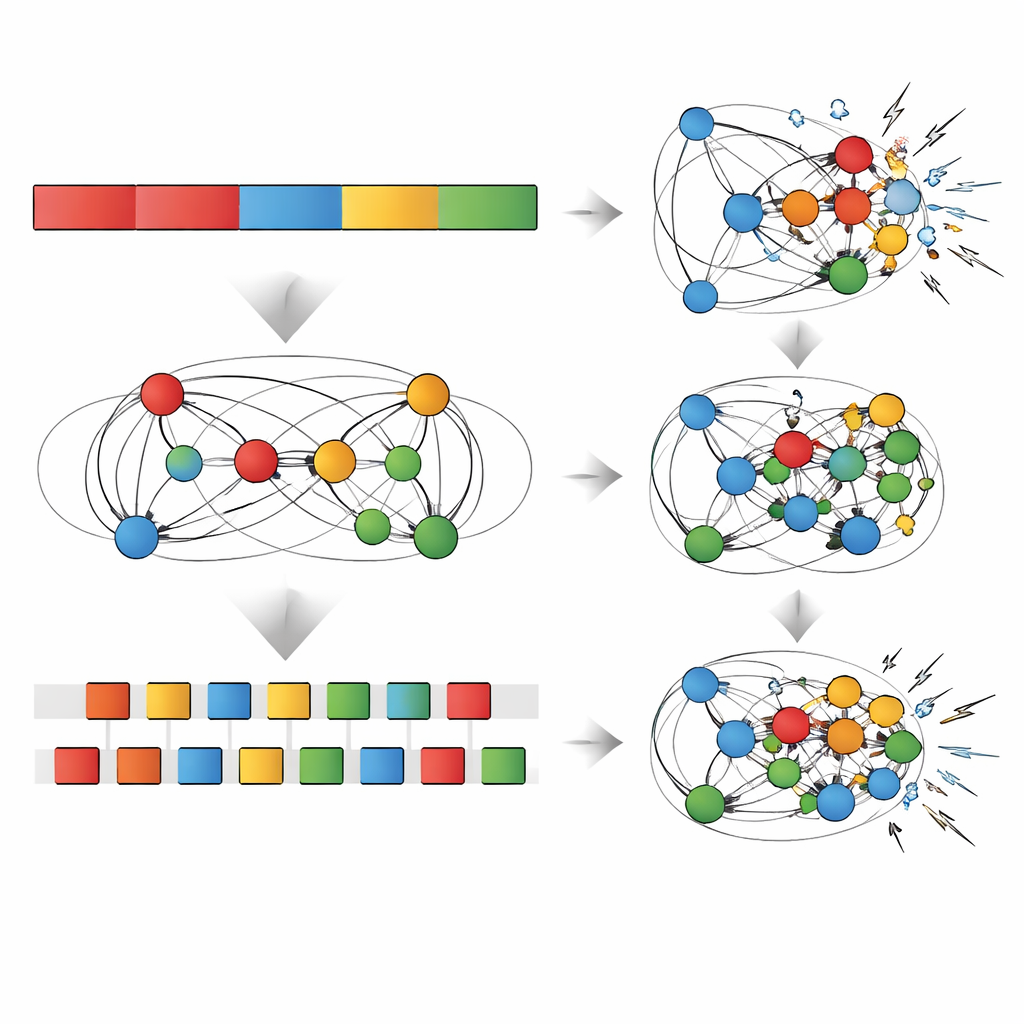
Testing How Tough the Memories Are
The team then subjected both networks to a series of “stress tests” designed to mimic real-world challenges to memory. They gradually added random noise to the network’s connections, snipped away a fraction of those connections (a pruning test), or forced the networks to learn yet another new sequence and watched how performance changed. In every case, the apparent advantage of repetitive practice on the most recent sequence faded quickly: a bit of noise, pruning, or new learning was enough to erode these gains and bring performance down to—or even below—the interleaved network’s level. By contrast, the generalization edge created by interleaved practice was more resilient, surviving moderate noise, pruning, and extra training. In some cases, pruning even improved the ability to generalize, echoing findings that slimming down a network can help it focus on the most meaningful patterns.
A Simple Principle with Wide Reach
Taken together, the results show that a very basic recurrent network—without detailed biological learning rules or special “context” modules—naturally reproduces the key features of interleaved practice seen in human motor learning. Repetitive practice yields quick but brittle gains, built on overspecialized internal codes that are easily disrupted and that interfere with other memories. Interleaved practice forces the system to juggle multiple contexts at once, pushing it toward more robust, broadly useful representations that support both retention and transfer to new sequences. For everyday learners and rehabilitation specialists, this work reinforces a practical message: mixing tasks during practice may feel harder and slower, but it helps the brain (and brain-inspired machines) build skills that last and adapt.
Citation: Song, Y., Kim, H. & Kim, T. A minimal recurrent neural network models the robustness of interleaved practice on motor sequence learning. Sci Rep 16, 10068 (2026). https://doi.org/10.1038/s41598-026-40162-w
Keywords: motor learning, interleaved practice, recurrent neural networks, catastrophic forgetting, skill rehabilitation