Clear Sky Science · sv
En modellbaserad bildfusionsram med diskreta bandbegränsade shearlet-transformer
Varför bättre foton spelar roll
Alla som försökt fotografera en solnedgång eller en nattlig stadssilhuett känner igen frustrationen: om himlen ser rätt ut blir byggnaderna för mörka; om byggnaderna är tydliga förvandlas himlen till en vit suddig yta. Denna artikel tar sig an det vardagliga problemet. Den presenterar ett nytt sätt att kombinera flera foton av samma scen, tagna vid olika ljusstyrkor, till en enda bild som bevarar både skugg- och högdagersdetaljer, utan att förlita sig på ogenomskinliga djupinlärningstrick.
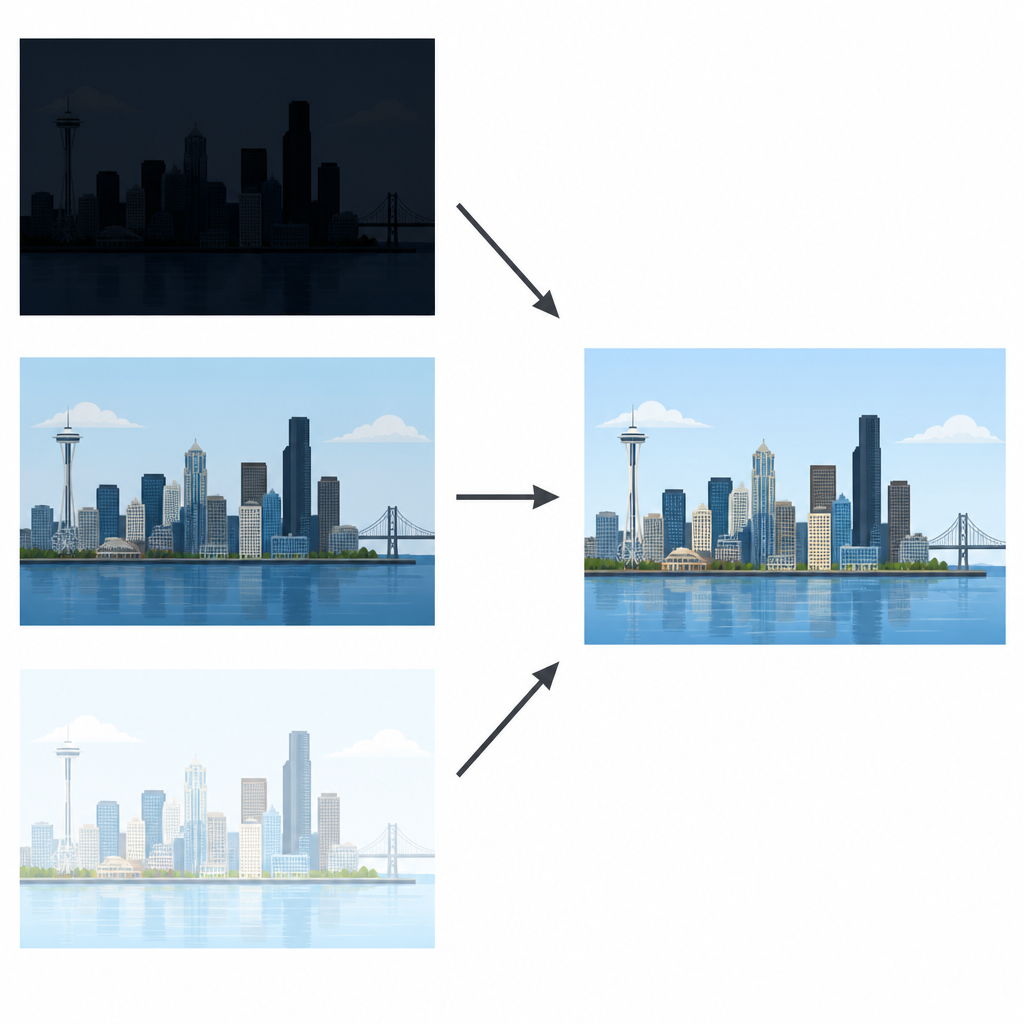
Att göra flera bilder till en klar vy
Moderna kamerasensorer kan inte matcha det mänskliga ögat, som bekvämt ser detaljer i både ljusa moln och dunkla gator samtidigt. Fotografer löser ofta detta genom att ta en sekvens bilder av samma scen: en underexponerad för att skydda ljusa områden, en normal och en överexponerad för att avslöja mörka partier. Målet med multi-exponeringsbildfusion är att kombinera dessa bilder till en enda bild som känns naturlig och detaljerad överallt. Tidigare metoder blandade antingen pixlar direkt eller använde enkla knep för att undvika spökbilder, men de gav ofta matta resultat eller suddade ut fin textur.
Ett tydligt alternativ till black-box-inlärning
Nyligen har djupinlärningssystem tagit över denna uppgift och lärt sig hur man blandar bilder från stora träningsset. Dessa system kan producera slagkraftiga bilder, men de är dyra att träna, beroende av använda data och svåra att tolka. I kontrast utvecklar författarna en helt transparent, träningsfri metod som vilar på välkänd matematik. Istället för att lära sig att fusera bilder från exempel följer deras metod precisa regler som kan inspekteras, reproduceras och justeras, vilket är attraktivt i vetenskapliga, medicinska eller säkerhetskritiska sammanhang där förtroende och spårbarhet är viktiga.
Använda smarta riktningar för att följa detaljer
Hjärtat i den nya ansatsen är ett verktyg kallat den diskreta bandbegränsade shearlet-transformen. Enkelt uttryckt delar detta verktyg upp varje ingångsbild i lager som fångar strukturer i olika storlekar och riktningar, såsom kanter, linjer och kurvor. Till skillnad från äldre tekniker som mest behandlar detalj likadant i alla riktningar är denna transform särskilt bra på att följa lutande och böjda formationer som taklinjer, silhuetter och krusningar på vatten. Varje källbild omvandlas först till lågfreventa lager som innehåller övergripande ljusstyrka och form, och högfreventa lager som bär fina kanter och texturer. Metoden fuserar sedan dessa lager med noggrant valda regler innan den återbygger den slutliga bilden.
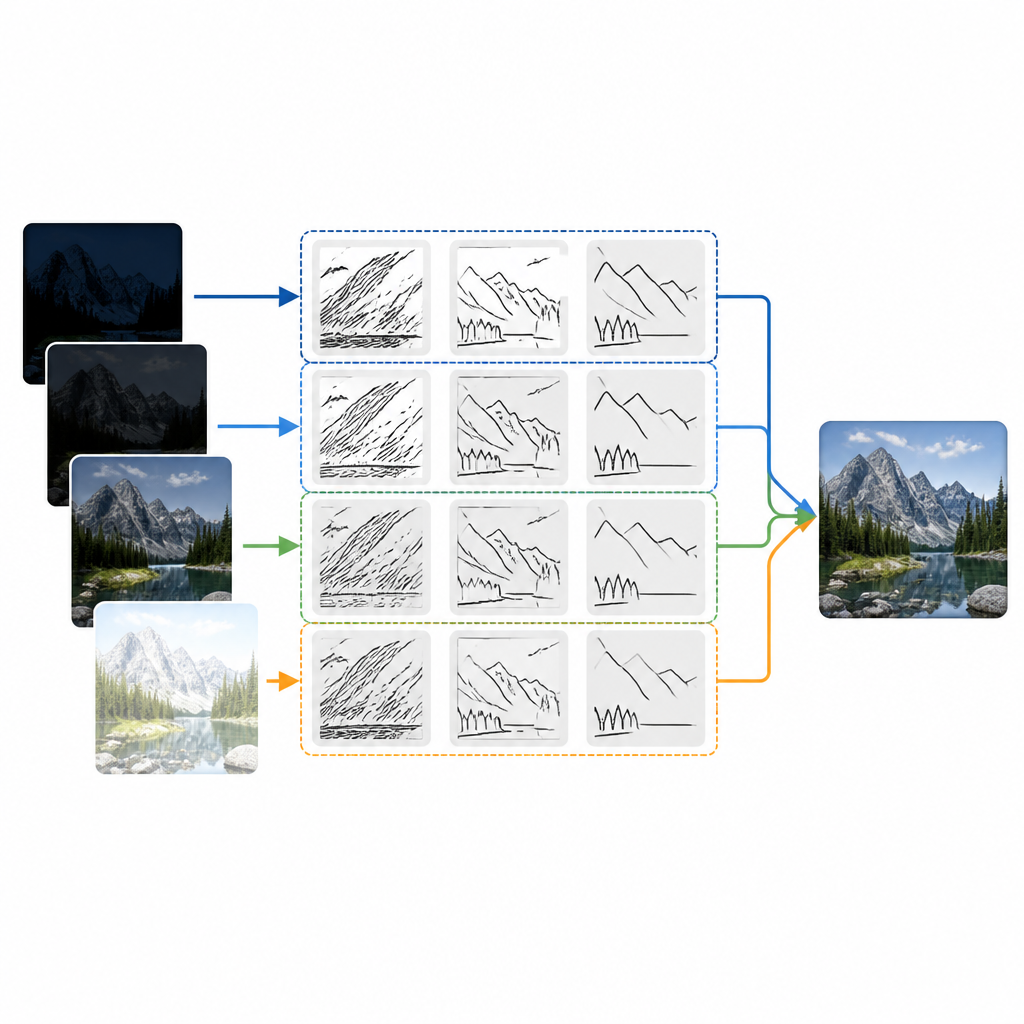
Välja vad som ska behållas från varje exponering
För att avgöra vilka detaljer från varje exponering som ska synas i slutbilden testar författarna två enkla strategier. För långsamt förändrande bakgrundsinnehåll tar de medelvärdet av de lågfreventa lagren så att den övergripande ljusstyrkan och scenstrukturen ser naturlig ut. För fin detalj testar de två konkurrerande idéer. En regel gynnar områden där variationen i ett litet grannskap konsekvent är stark, vilket tenderar att behålla stabil textur samtidigt som brus motstås. Den andra regeln väljer helt enkelt, på varje plats, den mest iögonfallande lokala förändringen i förhållande till omgivningen, vilket kan skärpa kanter men vara mer känsligt för brus. Experiment på standardtestscener, såsom vyer över en kanal och en maskerad gatupraegare, visar att båda reglerna beter sig likartat när de kombineras med shearlet-transformens kraftfulla riktade lager.
Se vinsterna i siffror och scener
Teamet jämför sin metod med flera välanvända verktyg som dekomponerar bilder på olika sätt, inklusive klassiska wavelets och mer avancerade kontur- och shear-baserade scheman. Med vanliga kvalitetsmått som mäter skärpa, informationsinnehåll och strukturell likhet producerar deras ansats konsekvent bilder med skarpare kanter och rikare detaljer än dessa äldre metoder. De fusionerade fotona visar läsbar textur i båtar, byggnader och himlar som antingen gick förlorade i bländning eller var dolda i skugga i originalexponeringarna. Även om den nya metoden är långsammare än vissa alternativ, eftersom den arbetar i frekvensdomänen med många riktade filter, förblir den praktisk för offline-bearbetning där visuell kvalitet och tolkbarhet väger tyngre än hastighet.
Vad detta betyder för bättre och klarare bilder
Enkelt uttryckt visar detta arbete att ett omsorgsfullt utformat matematiskt verktyg kan konkurrera med och till och med överträffa både traditionella och inlärda tillvägagångssätt för att blanda multi-exponeringsfoton, utan behov av träningsdata. Genom att fokusera på hur kanter och texturer framträder i olika storlekar och riktningar kan metoden plocka fram de bästa synliga delarna från varje ingångsbild och väva dem till en enhetlig, balanserad bild. För fotografer, ingenjörer och forskare som behöver förtroendefulla, reproducerbara bildförbättringar erbjuder den en klar, väl förklarad väg till HDR-bilder som ser närmare ut det mänskliga ögat naturligt uppfattar.
Citering: Ji, W., Chen, X. A model-based image fusion framework using discrete band-limited shearlets. Sci Rep 16, 15204 (2026). https://doi.org/10.1038/s41598-025-34942-z
Nyckelord: multi-exponeringsbildfusion, hög dynamisk omfångsbild (HDR), shearlet-transform, förbättring av bilddetaljer, beräkningsfotografi