Clear Sky Science · pl
Framework fuzji obrazów oparty na modelu z dyskretnymi, pasmowo-ograniczonymi shearletami
Dlaczego lepsze zdjęcia mają znaczenie
Każdy, kto próbował fotografować zachód słońca lub nocną panoramę, zna to uczucie: jeśli niebo wygląda dobrze, budynki są zbyt ciemne; jeśli budynki są wyraźne, niebo staje się rozbielone. Artykuł rozwiązuje ten codzienny problem. Przedstawia nowy sposób łączenia kilku zdjęć tej samej sceny wykonanych przy różnych poziomach jasności w pojedynczy obraz, który zachowuje zarówno szczegóły w cieniach, jak i w światłach, bez polegania na nieprzejrzystych sztuczkach uczenia głębokiego.
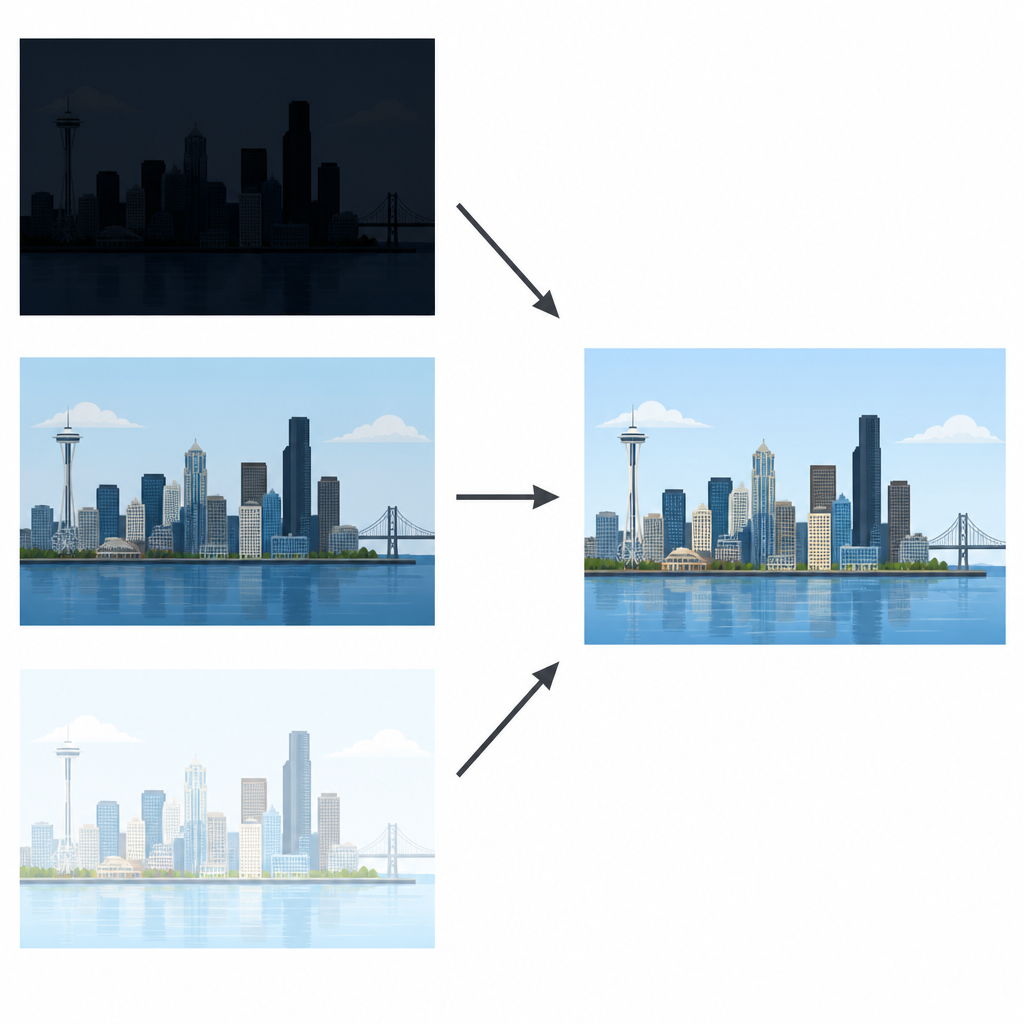
Przekształcanie wielu ujęć w jeden przejrzysty widok
Współczesne czujniki aparatów nie dorównują ludzkiemu oku, które jednocześnie wygodnie dostrzega detale w jasnych chmurach i ciemnych ulicach. Fotograficy często obejmują to, wykonując serię zdjęć tej samej sceny: jedno niedoświetlone, aby chronić jasne obszary, jedno normalne i jedno prześwietlone, by odsłonić ciemne fragmenty. Celem fuzji obrazów o wielu naświetleniach jest połączenie tych ujęć w pojedyncze zdjęcie, które wygląda naturalnie i zachowuje detale w każdym miejscu. Wcześniejsze metody albo mieszały piksele bezpośrednio, albo stosowały proste triki, by uniknąć duchów (ghostingu), lecz często dawały matowe rezultaty lub rozmazywały drobną fakturę.
Przejrzysta alternatywa dla „czarnej skrzynki” uczenia
Ostatnio zadanie to przejęły systemy uczenia głębokiego, które uczą się, jak łączyć obrazy na podstawie dużych zbiorów treningowych. Systemy te potrafią wygenerować uderzające obrazy, ale są drogie w trenowaniu, silnie zależą od użytych danych i są trudne do interpretacji. W przeciwieństwie do nich autorzy opracowują w pełni przejrzyste, wolne od treningu podejście oparte na dobrze rozumianej matematyce. Zamiast uczyć się fuzji z przykładów, ich metoda podąża za precyzyjnymi regułami, które można sprawdzić, odtworzyć i dostosować — co jest atrakcyjne w środowiskach naukowych, medycznych lub krytycznych dla bezpieczeństwa, gdzie zaufanie i możliwość śledzenia są niezbędne.
Wykorzystanie kierunków do śledzenia detali
Rdzeniem nowego podejścia jest narzędzie zwane dyskretną, pasmowo-ograniczoną transformatą shearletów. Mówiąc prościej, narzędzie to rozkłada każdy obraz wejściowy na warstwy, które wychwytują struktury o różnych rozmiarach i kierunkach, takie jak krawędzie, linie i krzywizny. W przeciwieństwie do starszych technik, które w większości traktują detale jednakowo we wszystkich kierunkach, ta transformata jest szczególnie dobra w podążaniu za pochyłymi i zakrzywionymi elementami, jak krawędzie dachów, sylwetki czy fale na wodzie. Każde źródłowe zdjęcie najpierw konwertowane jest na warstwy niskich częstotliwości, zawierające ogólną jasność i kształt, oraz warstwy wysokich częstotliwości, niosące drobne krawędzie i tekstury. Metoda następnie scala te warstwy przy użyciu starannie dobranych reguł, po czym rekonstruuje końcowy obraz.
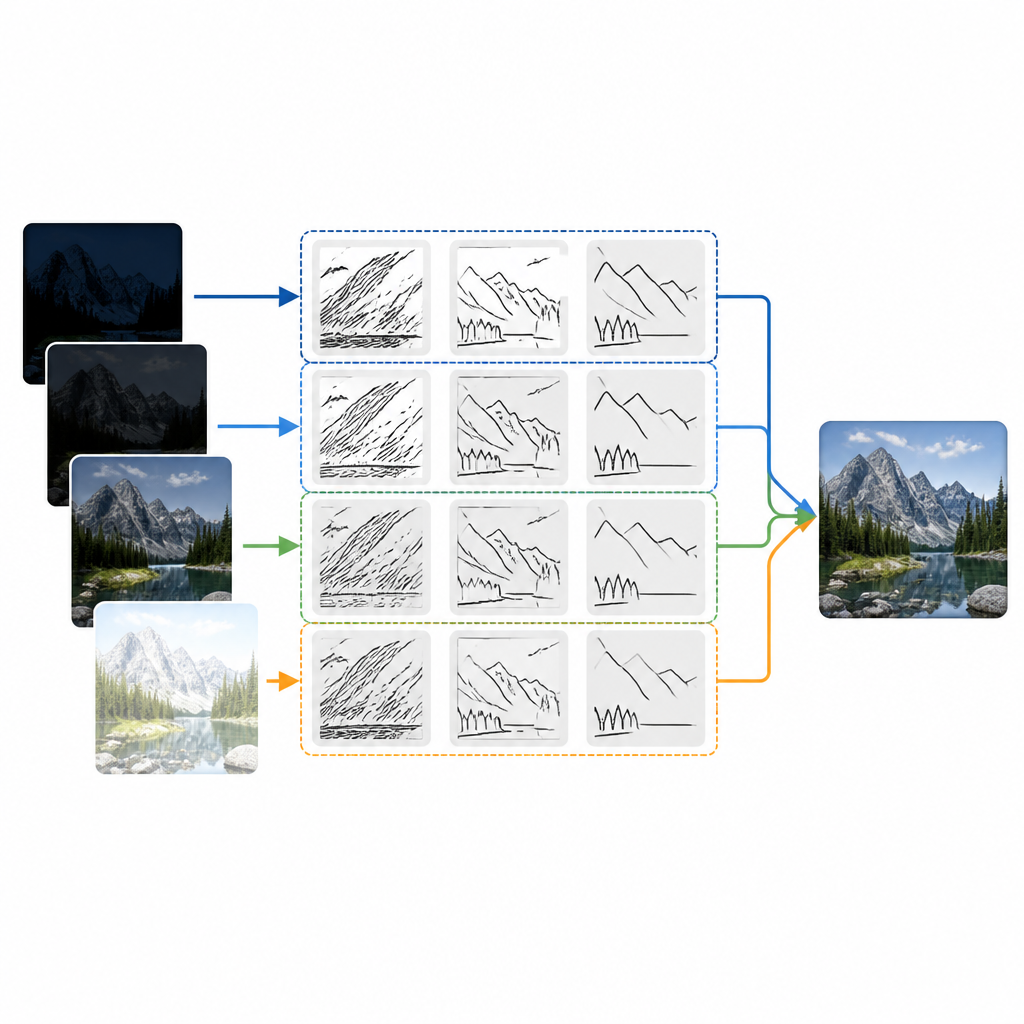
Wybieranie, co zachować z każdej ekspozycji
Aby zdecydować, które detale z każdej ekspozycji powinny pojawić się w obrazie końcowym, autorzy testują dwie proste strategie. Dla powoli zmieniających się elementów tła uśredniają warstwy niskich częstotliwości, tak by ogólna jasność i struktura sceny wyglądały naturalnie. Dla drobnych detali rozważają dwie konkurujące koncepcje. Jedna reguła faworyzuje regiony, w których wariancja w małym sąsiedztwie jest konsekwentnie silna — co zwykle zachowuje stabilne tekstury i odporne jest na szum. Druga reguła po prostu wybiera, w każdym punkcie, najbardziej wyraźną lokalną zmianę względem otoczenia, co może wyostrzyć krawędzie, ale być bardziej wrażliwe na szumy. Eksperymenty na standardowych scenach testowych, takich jak widoki kanału czy zamaskowany artysta uliczny, pokazują, że obie reguły zachowują się podobnie, gdy są połączone z mocnymi, kierunkowymi warstwami transformacji shearletów.
Widoczne zyski w liczbach i w scenach
Zespół porównuje swoją metodę z kilkoma powszechnie stosowanymi narzędziami dekompozycji obrazów, w tym klasycznymi falami (wavelet) oraz bardziej zaawansowanymi schematami opartymi na konturach i shearletach. Korzystając z powszechnych miar jakości, które oceniają ostrość, zawartość informacji i podobieństwo strukturalne, ich podejście konsekwentnie generuje obrazy z ostrzejszymi krawędziami i bogatszymi detalami niż te starsze metody. Zsynchronizowane zdjęcia ujawniają czytelną fakturę w łodziach, budynkach i niebach, która w oryginalnych ekspozycjach była albo utracona przez olśnienie, albo pogrzebana w cieniu. Choć nowa metoda jest wolniejsza od niektórych alternatyw, ponieważ działa w dziedzinie częstotliwości z wieloma filtrami kierunkowymi, pozostaje praktyczna do przetwarzania offline tam, gdzie ważniejsza jest jakość wizualna i interpretowalność niż prędkość.
Co to oznacza dla lepszych i czytelniejszych obrazów
Mówiąc wprost, praca pokazuje, że starannie zaprojektowane narzędzie matematyczne może dorównać, a nawet przewyższyć zarówno tradycyjne, jak i uczone podejścia do łączenia zdjęć o wielu naświetleniach, bez potrzeby danych treningowych. Koncentrując się na tym, jak krawędzie i tekstury pojawiają się w różnych rozmiarach i kierunkach, metoda potrafi wydobyć najlepsze widoczne fragmenty z każdego wejściowego ujęcia i spleść je w pojedynczy, zrównoważony obraz. Dla fotografów, inżynierów i naukowców, którzy potrzebują wiarygodnego, odtwarzalnego wzmacniania obrazu, oferuje jasną, dobrze opisaną ścieżkę do zdjęć o wysokim zakresie dynamicznym, które wyglądają bliżej tego, co ludzkie oko naturalnie dostrzega.
Cytowanie: Ji, W., Chen, X. A model-based image fusion framework using discrete band-limited shearlets. Sci Rep 16, 15204 (2026). https://doi.org/10.1038/s41598-025-34942-z
Słowa kluczowe: fuzja obrazów o wielu naświetleniach, obrazowanie o wysokim zakresie dynamicznym, transformata shearlet, wzmacnianie szczegółów obrazu, fotografia obliczeniowa