Clear Sky Science · de
Ein modellbasiertes Bildfusions‑Rahmenwerk mit diskreten, bandbegrenzten Shearlets
Warum bessere Fotos wichtig sind
Wer schon einmal einen Sonnenuntergang oder eine nächtliche Skyline fotografiert hat, kennt die Frustration: Sieht der Himmel richtig aus, sind die Gebäude zu dunkel; sind die Gebäude klar, wird der Himmel zu einem weißen Fleck. Dieses Papier nimmt sich genau dieses alltägliche Problem an. Es stellt eine neue Methode zum Zusammenführen mehrerer Aufnahmen derselben Szene vor, die bei unterschiedlichen Helligkeiten gemacht wurden, zu einem einzigen Bild, das sowohl Schatten‑ als auch Spitzlichtdetails erhält, ohne auf undurchsichtige Deep‑Learning‑Tricks zurückzugreifen.
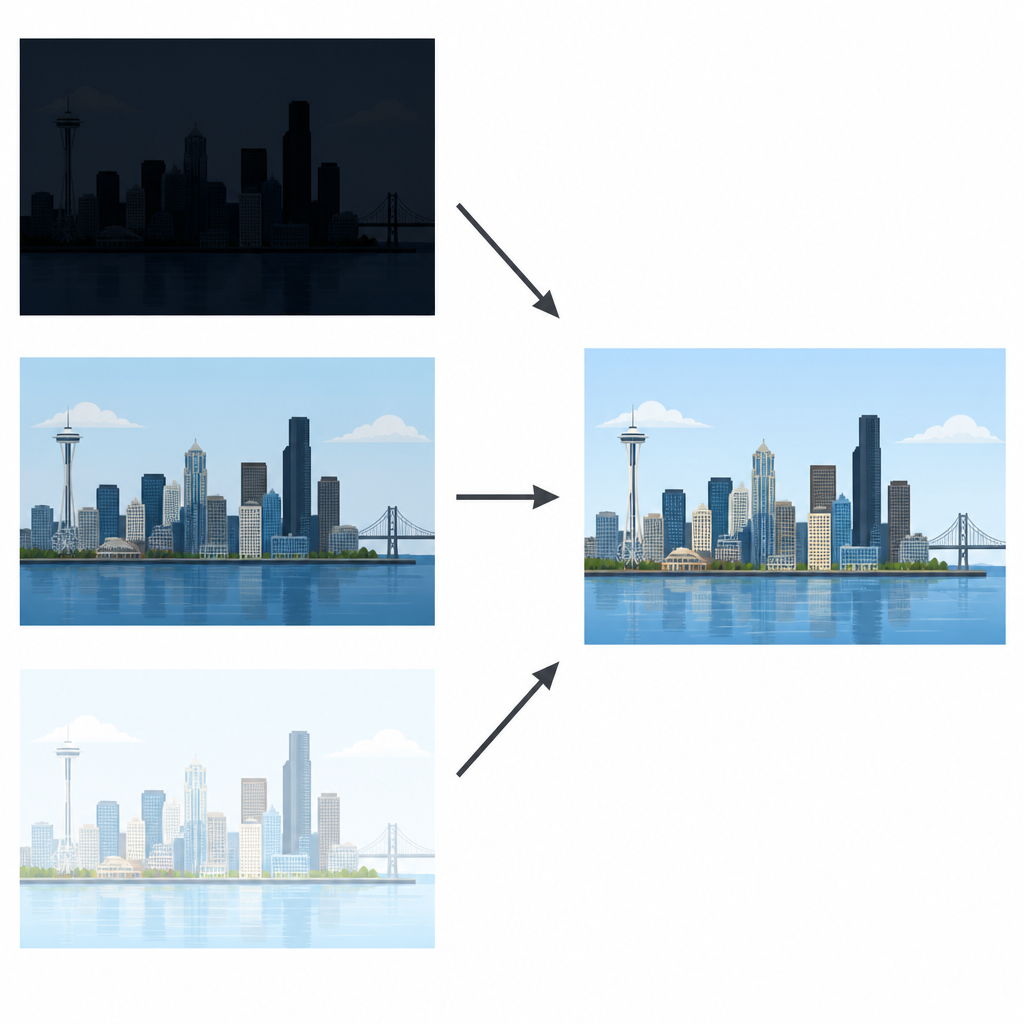
Mehrere Aufnahmen zu einer klaren Ansicht vereinen
Moderne Kamerasensoren können nicht mit dem menschlichen Auge mithalten, das gleichzeitig Details in hellen Wolken und dunklen Straßen erkennt. Fotografen umgehen das oft, indem sie eine Folge von Aufnahmen derselben Szene machen: eine unterbelichtet, um helle Bereiche zu schützen, eine normal belichtet und eine überbelichtet, um dunkle Regionen sichtbar zu machen. Ziel der Multi‑Exposure‑Bildfusion ist es, diese Aufnahmen zu einem einzelnen Bild zu vereinen, das überall natürlich und detailreich wirkt. Frühere Methoden mischten die Pixel oft direkt oder nutzten einfache Tricks, um Geisterbilder zu vermeiden, lieferten dabei jedoch häufig flache Ergebnisse oder verwischten feine Texturen.
Eine klare Alternative zu Black‑Box‑Lösungen
In jüngster Zeit haben Deep‑Learning‑Systeme diese Aufgabe übernommen und gelernt, Bilder aus großen Trainingsbeständen zu verschmelzen. Diese Systeme können beeindruckende Bilder erzeugen, sind aber aufwendig zu trainieren, stark von den verwendeten Daten abhängig und schwer zu interpretieren. Im Gegensatz dazu entwickeln die Autoren einen vollständig transparenten, trainingsfreien Ansatz, der auf gut verstandener Mathematik beruht. Anstatt aus Beispielen zu lernen, wie Bilder zu fusionieren sind, folgt ihre Methode präzisen Regeln, die einsehbar, reproduzierbar und anpassbar sind — attraktiv in wissenschaftlichen, medizinischen oder sicherheitskritischen Bereichen, in denen Vertrauen und Nachvollziehbarkeit entscheidend sind.
Mit cleveren Richtungen Details verfolgen
Das Kernstück des neuen Ansatzes ist ein Werkzeug namens diskrete bandbegrenzte Shearlet‑Transformation. Einfach gesagt zerlegt dieses Werkzeug jedes Eingangsbild in Schichten, die Strukturen in verschiedenen Größen und Richtungen erfassen, etwa Kanten, Linien und Kurven. Im Gegensatz zu älteren Techniken, die Details meist richtungsunabhängig behandeln, ist diese Transformation besonders gut darin, schrägen und gekrümmten Merkmalen wie Dachkanten, Silhouetten und Wasserwellen zu folgen. Jedes Quellbild wird zunächst in niederfrequente Schichten umgewandelt, die die Gesamthelligkeit und Form tragen, und in hochfrequente Schichten, die feine Kanten und Texturen enthalten. Die Methode fusioniert diese Schichten dann mit sorgfältig gewählten Regeln, bevor sie das finale Bild rekonstruiert.
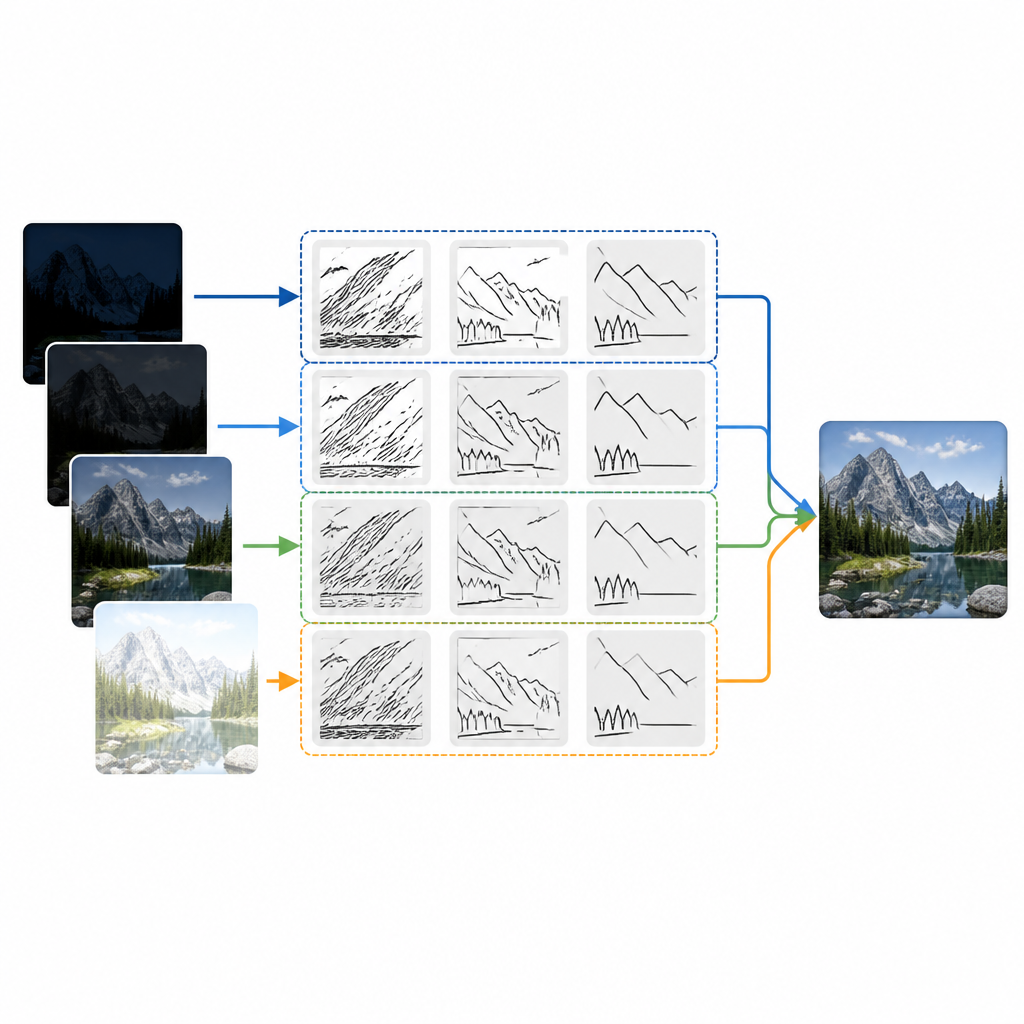
Auswählen, was von jeder Belichtung erhalten bleibt
Um zu entscheiden, welche Details aus jeder Belichtung im Endbild erscheinen sollen, testen die Autoren zwei einfache Strategien. Für langsam veränderliche Hintergrundinhalte werden die niederfrequenten Schichten gemittelt, damit Helligkeit und Szenenstruktur natürlich wirken. Für feine Details prüfen sie zwei konkurrierende Ideen. Eine Regel bevorzugt Regionen, in denen die Varianz in einer kleinen Nachbarschaft durchgängig stark ist, was dazu neigt, stabile Texturen zu erhalten und Rauschen zu widerstehen. Die andere Regel wählt einfach an jeder Stelle die auffälligste lokale Veränderung im Vergleich zur Umgebung aus, was Kanten schärfen kann, aber anfälliger für Rauschen ist. Experimente an Standardtestaufnahmen, wie Blicken auf einen Kanal und einem maskierten Straßenkünstler, zeigen, dass sich beide Regeln ähnlich verhalten, sobald sie mit den leistungsfähigen, richtungsabhängigen Shearlet‑Schichten kombiniert werden.
Gewinne in Zahlen und Szenen sichtbar machen
Das Team vergleicht seine Methode mit mehreren weit verbreiteten Werkzeugen, die Bilder auf unterschiedliche Weise zerlegen, darunter klassische Wavelets und fortgeschrittene Kontur‑ und Shear‑basierte Verfahren. Anhand gängiger Qualitätsmaße, die Schärfe, Informationsgehalt und strukturelle Ähnlichkeit bewerten, liefert ihr Ansatz durchweg Bilder mit klareren Kanten und reichhaltigeren Details als diese älteren Methoden. Die fusionierten Fotos zeigen lesbare Texturen in Booten, Gebäuden und Himmeln, die in den Originalbelichtungen entweder durch Blendung verloren gingen oder in Schatten verschwanden. Obwohl die neue Methode langsamer ist als einige Alternativen, weil sie im Frequenzbereich mit vielen Richtungsfiltern arbeitet, bleibt sie für Offline‑Verarbeitung praktikabel, wenn Bildqualität und Interpretierbarkeit wichtiger sind als Geschwindigkeit.
Was das für bessere und klarere Bilder bedeutet
Kurz gesagt zeigt diese Arbeit, dass ein sorgfältig gestaltetes mathematisches Werkzeug mit traditionellen und gelernten Ansätzen zur Verschmelzung von Multi‑Exposure‑Fotos konkurrieren und sie sogar übertreffen kann, ohne Trainingsdaten zu benötigen. Indem es darauf fokussiert, wie Kanten und Texturen in verschiedenen Größen und Richtungen erscheinen, kann die Methode die besten sichtbaren Teile jeder Aufnahme herausziehen und zu einem einzigen, ausgewogenen Bild verweben. Für Fotografen, Ingenieure und Wissenschaftler, die vertrauenswürdige, reproduzierbare Bildverbesserung benötigen, bietet sie einen klaren, gut erklärten Weg zu HDR‑Bildern, die dem entsprechen, was das menschliche Auge natürlich sieht.
Zitation: Ji, W., Chen, X. A model-based image fusion framework using discrete band-limited shearlets. Sci Rep 16, 15204 (2026). https://doi.org/10.1038/s41598-025-34942-z
Schlüsselwörter: Multi‑Exposure‑Bildfusion, High‑Dynamic‑Range‑Imaging, Shearlet‑Transformation, Bilddetailverbesserung, Computational Photography