Clear Sky Science · it
Un framework di fusione di immagini basato su modello usando shearlet discreti a banda limitata
Perché foto migliori contano
Chiunque abbia provato a fotografare un tramonto o lo skyline notturno conosce la frustrazione: se il cielo è corretto, gli edifici risultano troppo scuri; se gli edifici sono chiari, il cielo diventa una macchia bianca. Questo articolo affronta quel problema quotidiano. Presenta un nuovo modo di combinare diverse foto della stessa scena, scattate a livelli di luminosità differenti, in un’unica immagine che mantiene sia i dettagli delle ombre sia quelli delle alte luci, senza affidarsi a trucchi opachi di deep learning.
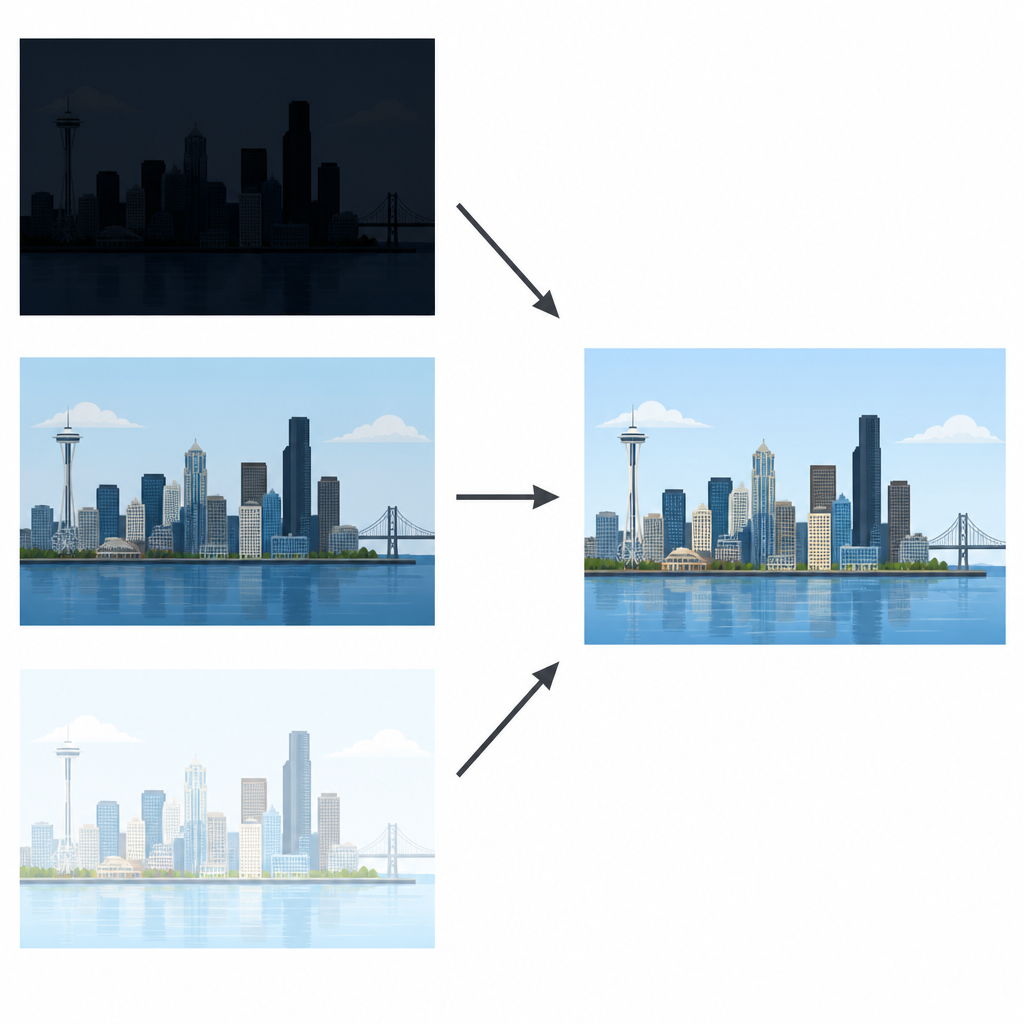
Trasformare più scatti in una vista nitida
I sensori delle fotocamere moderne non riescono a eguagliare l’occhio umano, che vede comodamente dettagli sia nelle nuvole luminose sia nelle strade buie allo stesso tempo. I fotografi aggirano spesso questo limite scattando una sequenza della stessa scena: una sottoesposta per proteggere le zone luminose, una normale e una sovraesposta per rivelare le aree scure. Lo scopo della fusione di immagini a esposizione multipla è combinare questi scatti in un’unica immagine che appaia naturale e dettagliata ovunque. I metodi precedenti o miscelavano i pixel direttamente o usavano accorgimenti semplici per evitare il ghosting, ma spesso producevano risultati spenti o sfocavano le trame fini.
Un’alternativa chiara alle scatole nere del learning
Negli ultimi tempi, i sistemi di deep learning hanno preso il sopravvento in questo compito, imparando a fondere immagini a partire da ampi set di addestramento. Questi sistemi possono produrre immagini impressionanti, ma sono costosi da addestrare, dipendono fortemente dai dati usati e sono difficili da interpretare. Al contrario, gli autori sviluppano un approccio completamente trasparente e privo di addestramento che si basa su una matematica ben compresa. Invece di imparare a fondere le immagini dagli esempi, il loro metodo segue regole precise che possono essere ispezionate, riprodotte e adattate, caratteristica utile in ambiti scientifici, medici o critici per la sicurezza dove fiducia e tracciabilità sono essenziali.
Usare direzioni intelligenti per seguire i dettagli
Il cuore del nuovo approccio è uno strumento chiamato trasformata shearlet discreta a banda limitata. In termini semplici, questo strumento scompone ogni immagine di ingresso in strati che catturano strutture a diverse scale e direzioni, come bordi, linee e curve. A differenza delle tecniche più vecchie che trattano i dettagli allo stesso modo in tutte le direzioni, questa trasformata è particolarmente efficace nel seguire caratteristiche inclinate e curve come i profili dei tetti, le sagome e le increspature sull’acqua. Ogni immagine sorgente viene prima convertita in strati a bassa frequenza che contengono la luminosità e la forma complessiva, e in strati ad alta frequenza che trasportano bordi fini e texture. Il metodo fonde poi questi strati usando regole accuratamente scelte prima di ricostruire l’immagine finale.
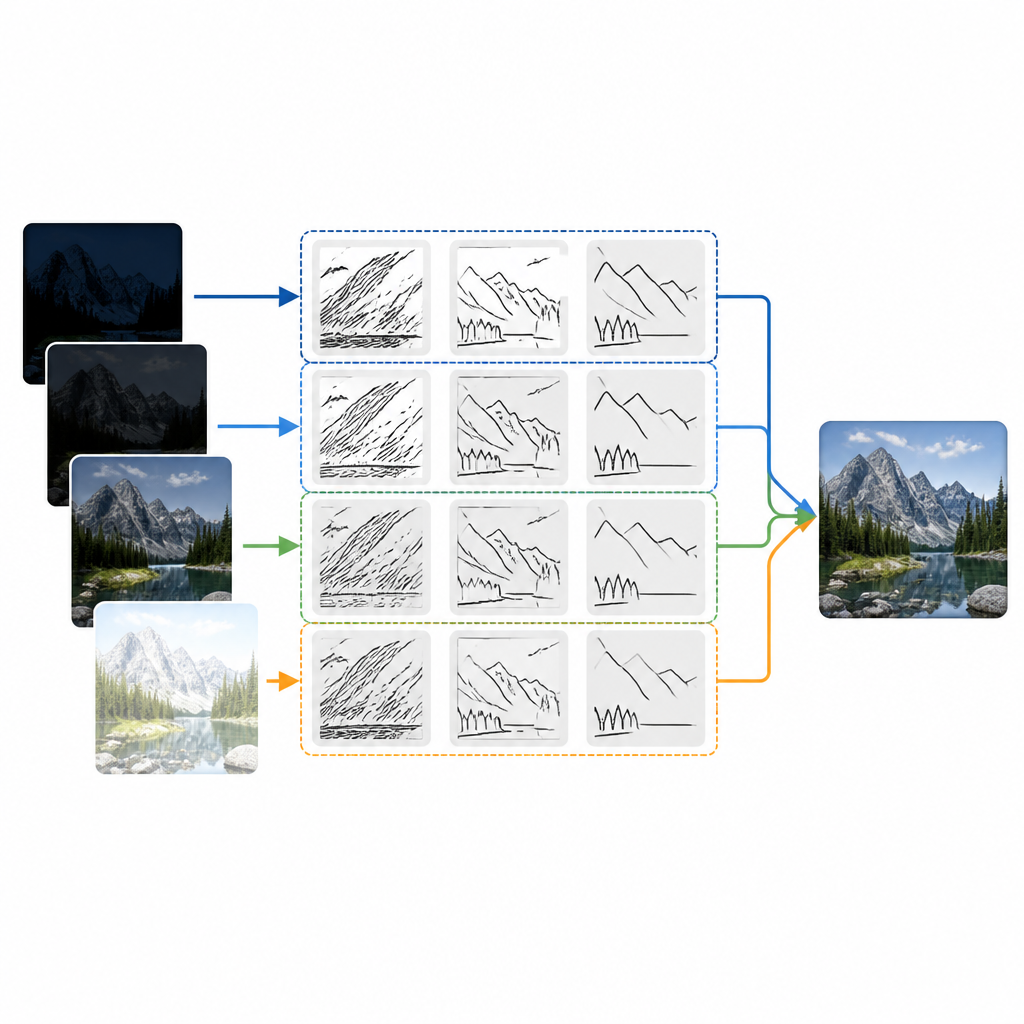
Scegliere cosa mantenere da ogni esposizione
Per decidere quali dettagli di ciascuna esposizione dovrebbero comparire nell’immagine finale, gli autori testano due strategie semplici. Per contenuti di sfondo che cambiano lentamente, fanno la media degli strati a bassa frequenza in modo che la luminosità complessiva e la struttura della scena appaiano naturali. Per i dettagli fini, provano due idee alternative. Una regola favorisce le regioni in cui la variazione in un piccolo vicinato è costantemente forte, il che tende a preservare texture stabili resistendo al rumore. L’altra regola sceglie, in ogni posizione, il cambiamento locale più evidente rispetto all’intorno, il che può affinare i bordi ma può essere più sensibile al rumore. Esperimenti su scene di test standard, come vedute di un canale e un artista di strada mascherato, mostrano che entrambe le regole si comportano in modo simile una volta combinate con i potenti strati direzionali della trasformata shearlet.
Osservare i miglioramenti nei numeri e nelle scene
Il team confronta il proprio metodo con diversi strumenti ampiamente usati che scompongono le immagini in modi differenti, incluse le onde classiche e schemi più avanzati basati su contorni e shear. Usando punteggi di qualità comuni che misurano nitidezza, contenuto informativo e similarità strutturale, il loro approccio produce costantemente immagini con bordi più netti e dettagli più ricchi rispetto a questi metodi più datati. Le foto fuse mostrano texture leggibili su barche, edifici e cieli che nelle esposizioni originali erano o perse nel bagliore o sepolte nelle ombre. Sebbene il nuovo metodo sia più lento di alcune alternative, perché opera nel dominio delle frequenze con molti filtri direzionali, rimane praticabile per l’elaborazione offline dove la qualità visiva e l’interpretabilità contano più della velocità.
Cosa significa per immagini migliori e più chiare
In termini semplici, questo lavoro mostra che uno strumento matematico accuratamente progettato può rivaleggiare e persino superare sia gli approcci tradizionali sia quelli appresi per la fusione di foto a esposizione multipla, senza la necessità di dati di addestramento. Concentrandosi su come bordi e texture appaiono a diverse scale e direzioni, il metodo riesce a estrarre le migliori porzioni visibili di ciascuno scatto di ingresso e a tessere il tutto in un’unica immagine bilanciata. Per fotografi, ingegneri e scienziati che necessitano di miglioramenti delle immagini affidabili e riproducibili, offre un percorso chiaro e ben spiegato verso immagini ad alto intervallo dinamico che somigliano di più a ciò che l’occhio umano vede naturalmente.
Citazione: Ji, W., Chen, X. A model-based image fusion framework using discrete band-limited shearlets. Sci Rep 16, 15204 (2026). https://doi.org/10.1038/s41598-025-34942-z
Parole chiave: fusione di immagini a esposizione multipla, imaging ad alto intervallo dinamico, trasformata shearlet, miglioramento dei dettagli dell'immagine, fotografia computazionale