Clear Sky Science · sv
2D multimodal bildsamling för fluorescensprediktion från transmittionsljusmikroskopi
Se celler utan omfattande preparering
Modern biologi förlitar sig ofta på lysande färgämnen för att avslöja vad som pågår inne i levande celler, men det har ett pris i tid, kostnad och cellhälsa. Den här artikeln presenterar databasen Light My Cells, en stor publik samling mikroskopbilder avsedd att hjälpa datorer lära sig återskapa dessa lysande vyer från skonsammare, märkningsfria bilder. För den som är intresserad av hur artificiell intelligens kan minska behovet av kemiska färgningar samtidigt som den visar cellernas inre liv, ligger detta arbete som grund.
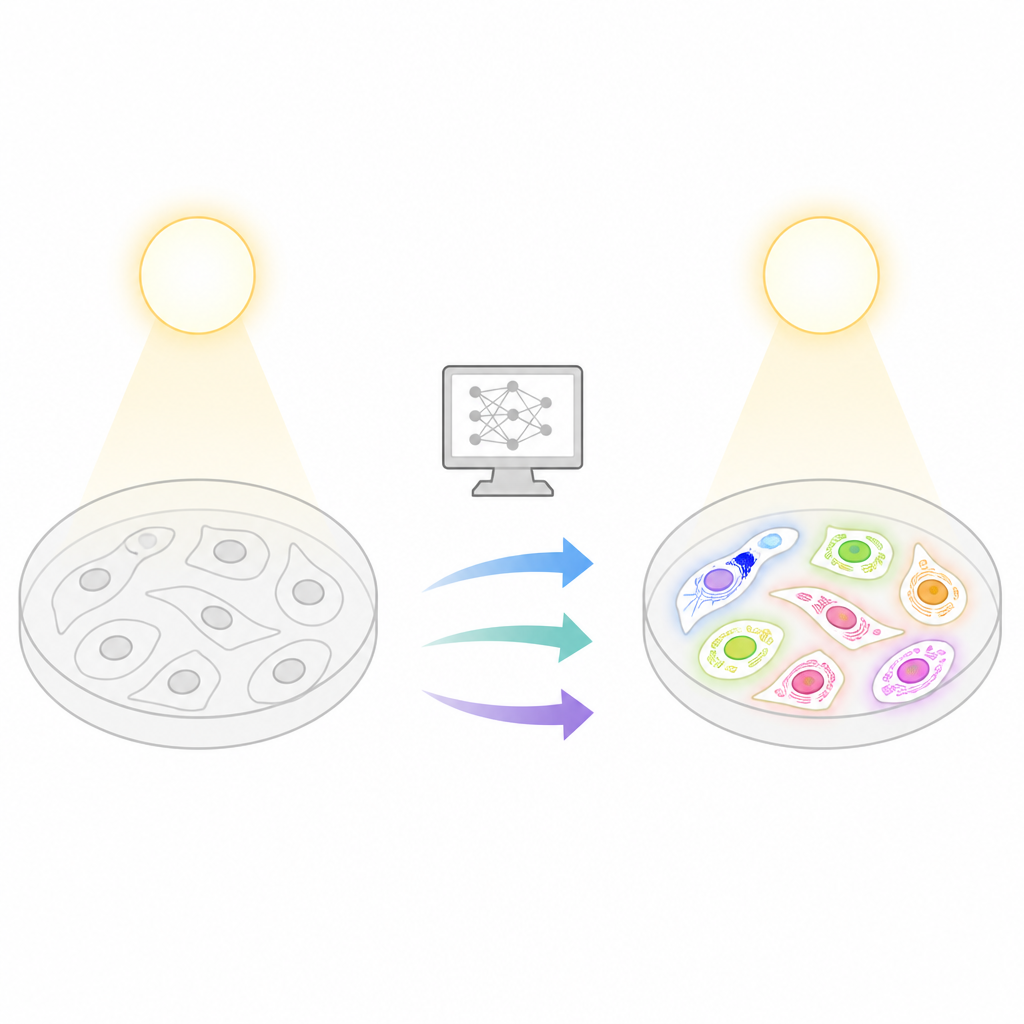
Varför lysande celler är både användbara och riskfyllda
Fluorescensmikroskopi låter forskare märka specifika delar av en cell så att de lyser upp, vilket gör strukturer som kärnan eller mitokondrierna lätta att följa. Men att preparera prover med fluorescerande färgämnen är arbetsintensivt, kan vara kostsamt och utsätter celler för ljus som kan bleka signalen eller till och med skada dem. Dessa problem växer i långa experiment eller stora screeningsprojekt där tusentals bilder måste tas. I kontrast är enkla transmittionsljustekniker, såsom brightfield eller faskontrast, skonsamma och märkningsfria, men de avslöjar inte direkt vilka strukturer som är vilka. Den centrala idén bakom Light My Cells är att överbrygga detta glapp genom att träna datorer att härleda fluorescensliknande bilder från dessa enkla, icke-skadliga vyer.
En nationell samling av varierande cellbilder
För att göra detta möjligt gick avbildningsexperter över hela Frankrike samman för att bygga en rik, delad dataset. Light My Cells-databasen samlar 56 984 tvådimensionella bilder grupperade i 2 574 matchade set, bidragna av åtta avbildningscenter och 30 oberoende studier. Varje set visar samma fält av levande däggdjursceller först med transmittionsljus och sedan med en eller flera fluorescerande markörer som framhäver kärnan, mitokondrier, tubulin eller aktin. Bilderna samlades in på en mängd olika mikroskop och med många provtyper, vilket fångar den variation som verkliga laboratorier möter varje dag. Denna mångfald är avgörande för att lära djuplärande modeller som kan hantera olika instrument, cellinjer och förvärvsförhållanden istället för att överanpassa sig till en enda, prydlig uppställning.
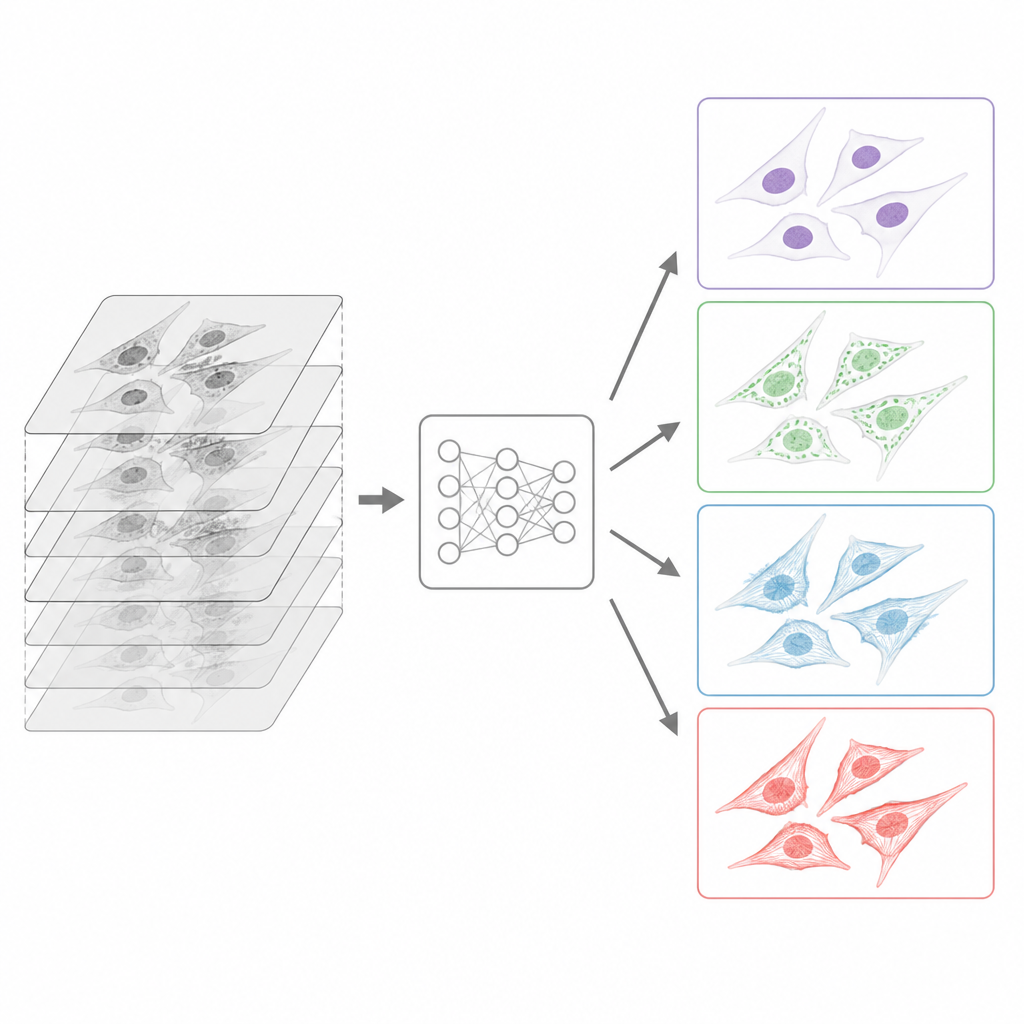
Hur bilderna standardiserades för datorer
Eftersom data kom från många platser byggde teamet en noggrann förberedelsepipeline innan de släppte samlingen. Alla ursprungliga filer, producerade i många proprietära mikroskopformat, konverterades till ett gemensamt öppet format kallat OME-TIFF som lagrar både bilden och detaljerad information om hur den togs. Bidragsgivare fyllde i rika metadata-mallar som beskriver provet, ljusvägen, objektiven och märkningsstrategin, enligt gemenskapens riktlinjer för återanvändbar avbildningsdata. För varje stack av bilder tagna på olika djup valde algoritmer automatiskt den mest fokuserade skivan, med en metod anpassad för transmittionsljus och en annan för fluorescenssignal. Medan alla transmittionsljusskivor bevarades, reducerades varje fluorescenskanal till ett enda skarpt plan, vilket matchar den typiska inlärningsuppgiften att förutsäga en väl fokuserad fluorescensvy från märkningsfritt input.
Vad databasen innehåller och hur kvalitet kontrollerades
Den slutliga resursen inkluderar över femtio tusen transmittionsljusbilder, mestadels brightfield men även faskontrast och differential interference contrast, plus mer än fyra tusen parade fluorescensbilder. Kärnan och mitokondrierna är väl representerade, medan tubulin och aktin förekommer mindre ofta, vilket skapar en naturlig klassobalans som användare måste beakta vid träning av modeller. Varje studie i arkivet dokumenteras med strukturerade beskrivningar av den biologiska modellen, avbildningshårdvaran och förvärvsinställningarna, så att användare kan filtrera efter kontext eller jämföra förhållanden. Författarna utförde också tekniska kontroller för att ta bort korrupta filer, verifiera att metadatafält var kompletta och bekräfta att de valda fokusplanen överensstämde med expertbedömning. Testskript säkerställde att vanliga verktyg som ImageJ, Napari och standard Python-bibliotek enkelt kan öppna och bearbeta bilderna.
Hur forskare kan använda denna öppna resurs
Bortom dess ursprungliga användning i en djuplärandeutmaning är Light My Cells-databasen avsedd som en generell testbädd för metoder som översätter eller analyserar märkningsfria bilder. Den parade karaktären hos datan gör den lämplig för uppgifter som att förutsäga fluorescens från transmittionsljus, segmentera cellstrukturer eller profilera celltillstånd utan extra färgningar. Eftersom transmittionsljusstackarna bevaras kan forskare också utforska modeller som använder djupinformation eller fokusestimering. All data och förberedelsekod är fritt tillgänglig under tillåtande licenser, vilket inbjuder andra att bygga på pipelinen, utöka datasetet eller benchmarka nya algoritmer.
Vad detta betyder för framtida cellavbildning
För icke-specialister är huvudbudskapet att Light My Cells tillhandahåller råmaterialet som behövs för att lära datorer att se inne i celler med skonsammare former av mikroskopi. Istället för att alltid tillsätta lysande markörer och riskera skada, kan forskare i allt större utsträckning förlita sig på smart mjukvara tränad på samlingar som denna för att avslöja var viktiga strukturer ligger. Databasen löser inte fluorescensfri avbildning på egen hand, men den gör högkvalitativa, väl dokumenterade exempel tillgängliga för alla och påskyndar framsteg mot mindre invasiva och mer skalbara sätt att iaktta levande celler i naturlig handling.
Citering: Kauffmann, D., Gay, G., Mateos-Langerak, J. et al. 2D Multimodal Image Collection for Fluorescence Prediction from Transmitted Light Microscopy. Sci Data 13, 743 (2026). https://doi.org/10.1038/s41597-026-07004-w
Nyckelord: fluorescensmikroskopi, transmittionsljusavbildning, djupt lärande, bioimage-databas, in silico-märkning