Clear Sky Science · es
Colección multimodal 2D de imágenes para la predicción de fluorescencia a partir de microscopía de luz transmitida
Ver las células sin preparación agresiva
La biología moderna a menudo depende de tintes fluorescentes para revelar lo que ocurre dentro de las células vivas, pero eso tiene un coste en tiempo, dinero y salud celular. Este artículo presenta la base de datos Light My Cells, una amplia colección pública de imágenes de microscopio diseñada para ayudar a las máquinas a aprender a recrear esas vistas fluorescentes a partir de imágenes más suaves y sin marcaje. Para quienes se interesan en cómo la inteligencia artificial puede reducir la necesidad de colorantes químicos y aun así mostrar la vida interna de las células, este trabajo sienta las bases.
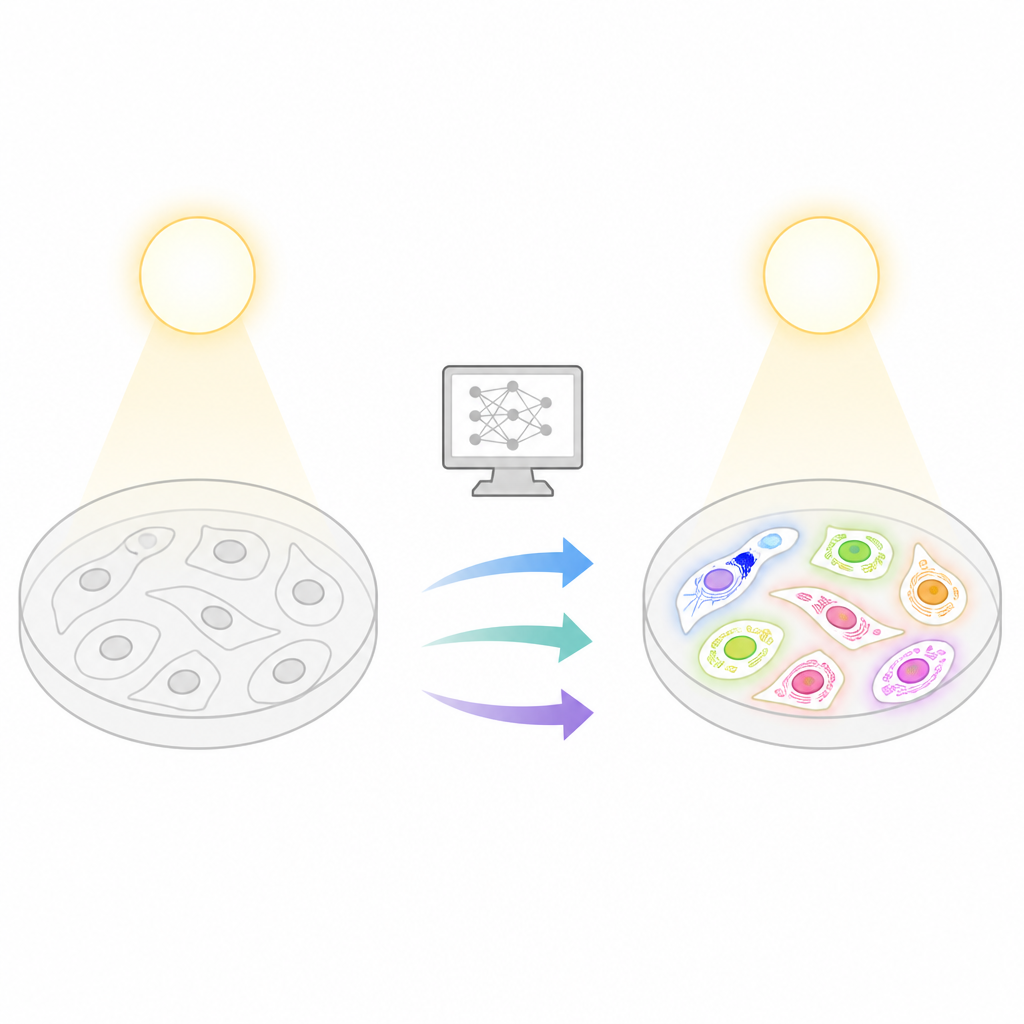
Por qué las células fluorescentes son útiles pero riesgosas
La microscopía de fluorescencia permite a los científicos etiquetar partes específicas de una célula para que se iluminen, lo que facilita el seguimiento de estructuras como el núcleo o las mitocondrias. Sin embargo, preparar muestras con tintes fluorescentes requiere mucho trabajo, puede ser costoso y expone a las células a la luz, que puede desvanecer la señal o incluso dañarlas. Estos problemas aumentan en experimentos largos o proyectos de cribado a gran escala, donde hay que capturar miles de imágenes. En contraste, técnicas sencillas de luz transmitida, como campo claro o contraste de fase, son más suaves y no requieren marcaje, pero no revelan directamente qué estructuras son cuáles. La idea central de Light My Cells es salvar esa brecha entrenando ordenadores para inferir imágenes similares a las de fluorescencia a partir de estas vistas simples y no dañinas.
Una colección nacional de imágenes celulares diversas
Para hacerlo posible, expertos en imagenología de toda Francia unieron esfuerzos para construir un conjunto de datos compartido y detallado. La base Light My Cells reúne 56.984 imágenes bidimensionales agrupadas en 2.574 conjuntos emparejados, aportadas por ocho centros de imagen y 30 estudios independientes. Cada conjunto muestra el mismo campo de células mamíferas vivas primero con luz transmitida y luego con una o varias etiquetas fluorescentes que resaltan el núcleo, las mitocondrias, la tubulina o la actina. Las imágenes se recogieron con una amplia variedad de microscopios y tipos de muestras, capturando la variación que los laboratorios reales encuentran a diario. Esta diversidad es crucial para enseñar a modelos de aprendizaje profundo que puedan tratar con distintos instrumentos, líneas celulares y condiciones de adquisición, en lugar de sobreajustarse a una única configuración ordenada.
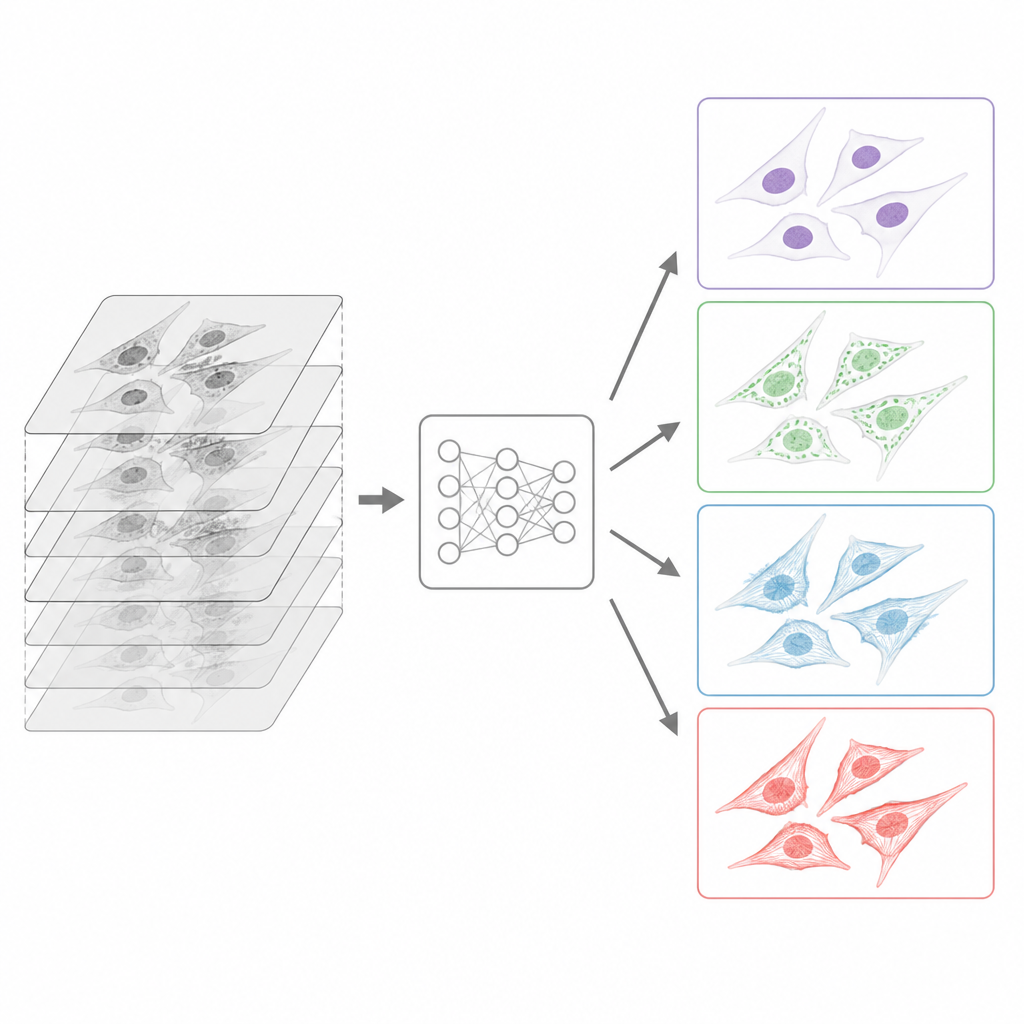
Cómo se estandarizaron las imágenes para los ordenadores
Como los datos provinieron de muchos sitios, el equipo construyó una canalización de preparación cuidadosa antes de publicar la colección. Todos los archivos originales, producidos en numerosos formatos propietarios de microscopio, se convirtieron a un formato común y abierto llamado OME-TIFF que almacena tanto la imagen como información detallada sobre cómo se adquirió. Los colaboradores completaron plantillas de metadatos extensas describiendo la muestra, el trayecto óptico, los objetivos y la estrategia de marcado, siguiendo directrices comunitarias para datos de imagen reutilizables. Para cada pila de imágenes tomada a distintas profundidades, algoritmos eligieron automáticamente el plano mejor enfocado, usando un método afinado para luz transmitida y otro para la señal fluorescente. Mientras que se conservaron todas las láminas de luz transmitida, cada canal fluorescente se redujo a un único plano nítido, coincidiendo con la tarea típica de aprendizaje de predecir una vista fluorescente bien enfocada a partir de entrada sin marcaje.
Qué contiene la base de datos y cómo se comprobó la calidad
El recurso final incluye más de cincuenta mil imágenes de luz transmitida, principalmente campo claro pero también contraste de fase y contraste de interferencia diferencial, además de más de cuatro mil imágenes de fluorescencia emparejadas. El núcleo y las mitocondrias están bien representados, mientras que tubulina y actina aparecen con menos frecuencia, creando un desequilibrio natural de clases que los usuarios deben tener en cuenta al entrenar modelos. Cada estudio en el archivo está documentado con descripciones estructuradas del modelo biológico, el hardware de imagen y los ajustes de adquisición, de modo que los usuarios puedan filtrar por contexto o comparar condiciones. Los autores también realizaron comprobaciones técnicas para eliminar archivos corruptos, verificar que los campos de metadatos estuvieran completos y confirmar que los planos de enfoque elegidos coincidieran con el criterio de expertos. Scripts de prueba aseguraron que herramientas comunes como ImageJ, Napari y las bibliotecas estándar de Python pueden abrir y procesar fácilmente las imágenes.
Cómo pueden usar los investigadores este recurso abierto
Más allá de su uso original en un desafío de aprendizaje profundo, la base Light My Cells está pensada como un banco de pruebas general para métodos que traduzcan o analicen imágenes sin marcaje. La naturaleza emparejada de los datos la hace adecuada para tareas como predecir fluorescencia a partir de luz transmitida, segmentar estructuras celulares o perfilar estados celulares sin tintes adicionales. Dado que se conservan las pilas de luz transmitida, los investigadores también pueden explorar modelos que usen información de profundidad o estimación de enfoque. Todos los datos y el código de preparación están disponibles abiertamente bajo licencias permisivas, invitando a otros a construir sobre la canalización, ampliar el conjunto de datos o comparar nuevos algoritmos.
Qué significa esto para la microscopía celular futura
Para el público no especializado, el mensaje clave es que Light My Cells proporciona la materia prima necesaria para enseñar a los ordenadores a mirar dentro de las células usando formas de microscopía más suaves. En lugar de recurrir siempre a etiquetas fluorescentes y arriesgar daños, los científicos podrían confiar cada vez más en software inteligente entrenado con colecciones como esta para revelar dónde se encuentran las estructuras clave. La base de datos no resuelve por sí sola la imagen sin fluorescencia, pero pone a disposición ejemplos de alta calidad y bien documentados para todos, acelerando el progreso hacia formas menos invasivas y más escalables de observar células vivas en acción.
Cita: Kauffmann, D., Gay, G., Mateos-Langerak, J. et al. 2D Multimodal Image Collection for Fluorescence Prediction from Transmitted Light Microscopy. Sci Data 13, 743 (2026). https://doi.org/10.1038/s41597-026-07004-w
Palabras clave: microscopía de fluorescencia, imágenes por luz transmitida, aprendizaje profundo, base de datos de bioimágenes, etiquetado in silico