Clear Sky Science · de
2D multimodale Bildersammlung zur Vorhersage von Fluoreszenz aus Durchlichtmikroskopie
Zellen ohne aufwändige Vorbereitung sichtbar machen
Die moderne Biologie nutzt häufig leuchtende Farbstoffe, um das Geschehen in lebenden Zellen zu zeigen, doch das hat seinen Preis in Zeit, Kosten und Zellgesundheit. Dieser Artikel stellt die Light My Cells-Datenbank vor, eine große öffentliche Sammlung von Mikroskopbildern, die Computern das Erlernen dieser leuchtenden Ansichten aus schonenderen, kennzeichnungsfreien Bildern ermöglichen soll. Für alle, die wissen wollen, wie künstliche Intelligenz den Bedarf an chemischen Färbungen reduzieren und dennoch das Innenleben von Zellen zeigen kann, legt diese Arbeit das Fundament.
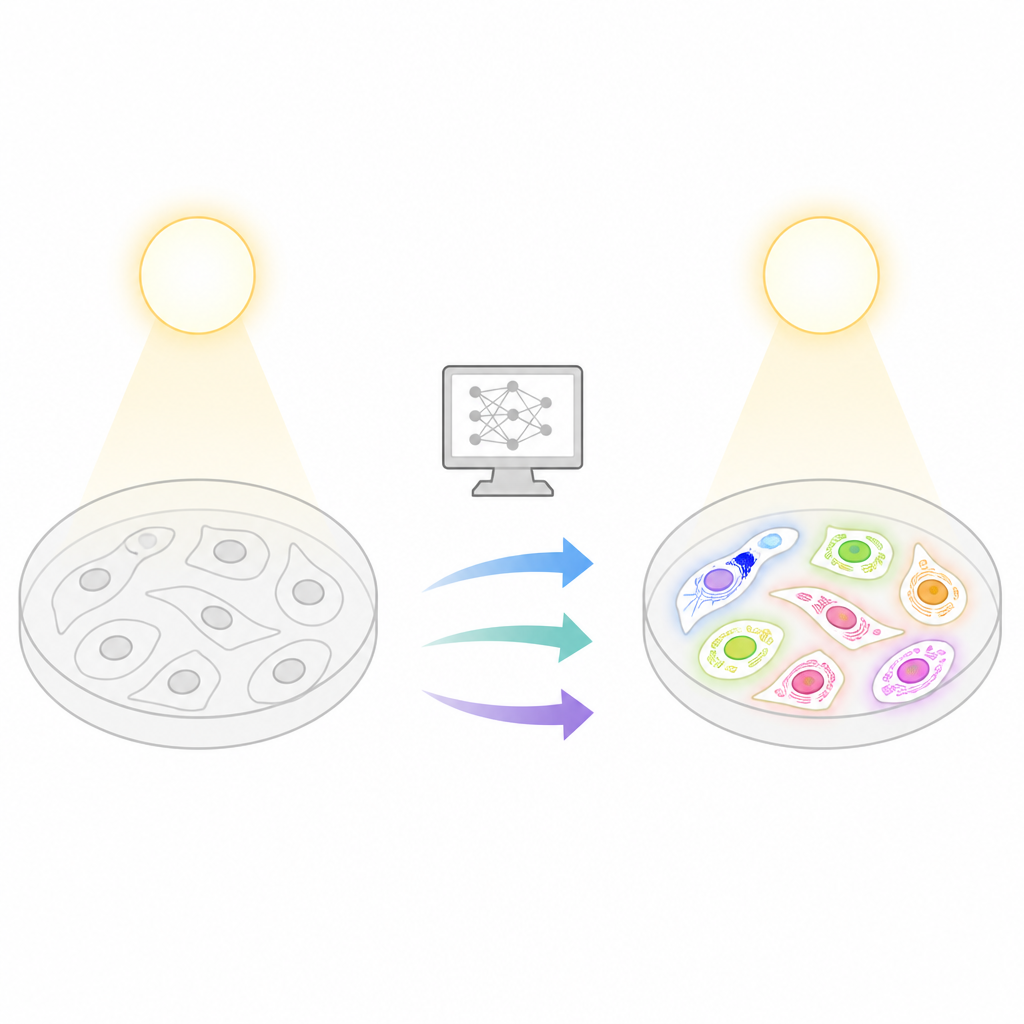
Warum leuchtende Zellen nützlich, aber riskant sind
Die Fluoreszenzmikroskopie erlaubt es Wissenschaftlern, bestimmte Zellbereiche gezielt zu markieren, sodass sie aufleuchten und Strukturen wie der Zellkern oder Mitochondrien leicht zu verfolgen sind. Die Probenvorbereitung mit Fluorochromen ist jedoch arbeitsintensiv, kann teuer sein und setzt Zellen dem Licht aus, das das Signal verblassen lassen oder die Zellen schädigen kann. Diese Probleme werden bei Langzeitexperimenten oder groß angelegten Screenings, in denen Tausende Bilder aufgenommen werden müssen, besonders gravierend. Im Gegensatz dazu sind einfache Durchlichtverfahren wie Hellfeld oder Phasenkontrast schonender und kennzeichnungsfrei, zeigen aber nicht direkt, welche Struktur welche Funktion hat. Die zentrale Idee von Light My Cells ist, diese Lücke zu schließen, indem Computer darin trainiert werden, fluoreszenzähnliche Bilder aus diesen einfachen, schonenden Ansichten zu erschließen.
Eine landesweite Sammlung vielfältiger Zellbilder
Um dies zu ermöglichen, haben sich Bildgebungsexperten in ganz Frankreich zusammengeschlossen, um einen umfangreichen, gemeinsam nutzbaren Datensatz zu erstellen. Die Light My Cells-Datenbank vereint 56.984 zweidimensionale Bilder, gruppiert in 2.574 passende Sets, beigesteuert von acht Bildgebungszentren und 30 unabhängigen Studien. Jedes Set zeigt dasselbe Sichtfeld lebender Säugerzellen zuerst im Durchlicht und dann mit einer oder mehreren fluoreszierenden Markierungen, die Kern, Mitochondrien, Tubulin oder Actin hervorheben. Die Bilder wurden mit einer breiten Palette von Mikroskopen und Probenarten aufgenommen und erfassen die Variation, der echte Labore im Alltag begegnen. Diese Vielfalt ist entscheidend, um Deep-Learning-Modelle zu trainieren, die mit unterschiedlichen Instrumenten, Zelllinien und Aufnahmebedingungen umgehen können, anstatt sich auf ein einzelnes, ordentliches Setup zu überanpassen.
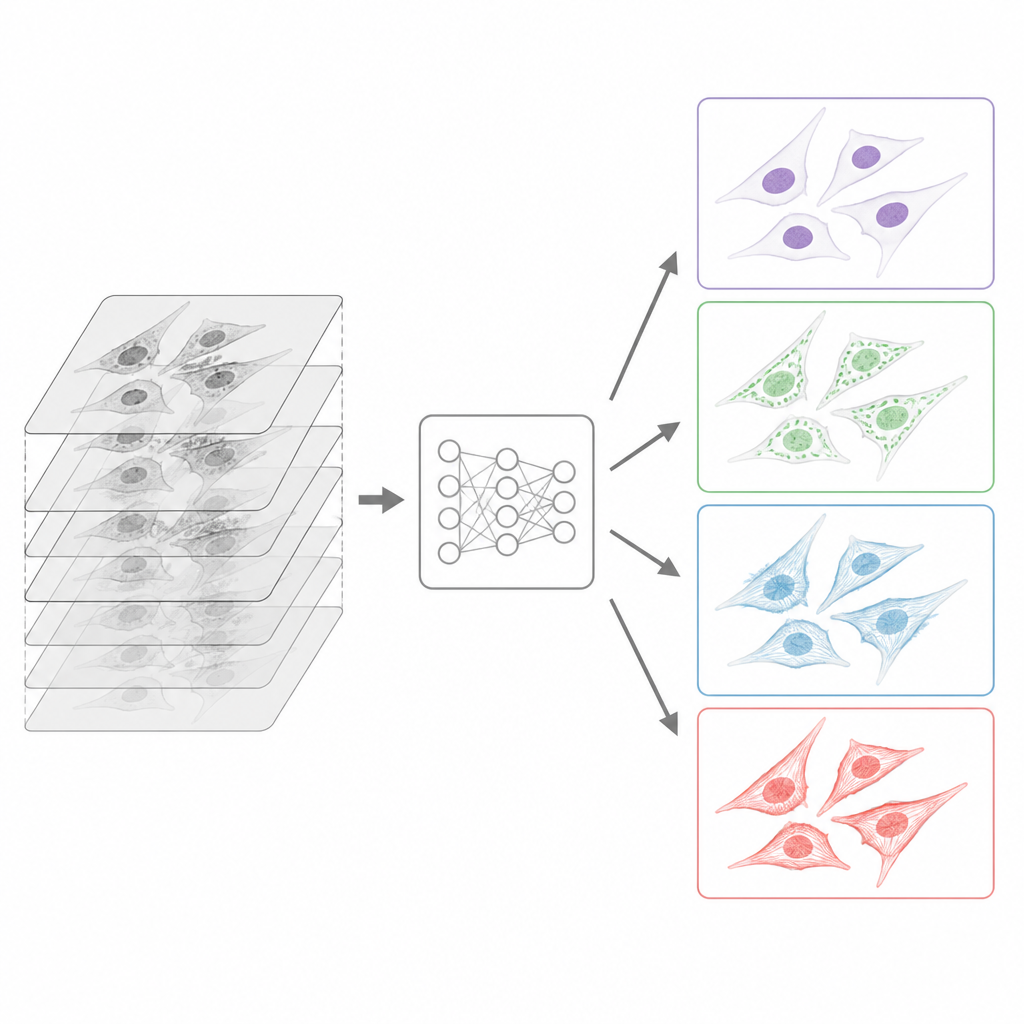
Wie die Bilder für Computer standardisiert wurden
Da die Daten von vielen Standorten stammten, entwickelte das Team eine sorgfältige Vorverarbeitungspipeline, bevor die Sammlung veröffentlicht wurde. Alle Originaldateien, die in vielen proprietären Mikroskopformaten vorlagen, wurden in ein gemeinsames, offenes Format namens OME-TIFF konvertiert, das sowohl das Bild als auch detaillierte Informationen über die Aufnahme speichert. Beitragende füllten umfangreiche Metadatenvorlagen aus, die Probe, Lichtweg, Objektive und Markierungsstrategie beschreiben, gemäß den Richtlinien der Gemeinschaft für wiederverwendbare Bilddaten. Für jeden Stapel von Bildern, die in unterschiedlichen Tiefen aufgenommen wurden, wählten Algorithmen automatisch die am besten fokussierte Ebene aus, wobei eine Methode für Durchlicht und eine andere für Fluoreszenzsignale abgestimmt war. Während alle Durchlicht-Schnitte erhalten blieben, wurde jeder Fluoreszenzkanal auf eine einzelne scharfe Ebene reduziert, was der typischen Lernaufgabe entspricht, aus kennzeichnungsfreien Eingaben eine gut fokussierte Fluoreszenzansicht vorherzusagen.
Was die Datenbank enthält und wie die Qualität geprüft wurde
Die endgültige Ressource umfasst über fünfzigtausend Durchlichtbilder, hauptsächlich Hellfeld, aber auch Phasenkontrast und differentiellen Interferenzkontrast, sowie mehr als viertausend gekoppelte Fluoreszenzaufnahmen. Zellkern und Mitochondrien sind gut vertreten, während Tubulin und Actin seltener vorkommen, wodurch eine natürliche Klassenungleichheit entsteht, die Nutzer beim Training von Modellen berücksichtigen müssen. Jede Studie im Archiv ist mit strukturierten Beschreibungen des biologischen Modells, der Bildgebungshardware und der Aufnahmeparameter dokumentiert, sodass Anwender nach Kontext filtern oder Bedingungen vergleichen können. Die Autoren führten auch technische Prüfungen durch, um beschädigte Dateien zu entfernen, zu verifizieren, dass Metadateneinträge vollständig sind, und zu bestätigen, dass die gewählten Fokusebenen dem Expertenurteil entsprechen. Testskripte stellten sicher, dass gängige Werkzeuge wie ImageJ, Napari und Standard-Python-Bibliotheken die Bilder problemlos öffnen und verarbeiten können.
Wie Forschende diese offene Ressource nutzen können
Über ihre ursprüngliche Verwendung in einer Deep-Learning-Challenge hinaus ist die Light My Cells-Datenbank als allgemeines Testfeld für Methoden gedacht, die kennzeichnungsfreie Bilder übersetzen oder analysieren. Die gepaarten Daten eignen sich für Aufgaben wie die Vorhersage von Fluoreszenz aus Durchlicht, die Segmentierung von Zellstrukturen oder das Profiling von Zellzuständen ohne zusätzliche Farbstoffe. Da die Durchlichtstapel erhalten bleiben, können Forschende auch Modelle untersuchen, die Tiefeninformationen oder Fokusabschätzung nutzen. Alle Daten und die Vorverarbeitungsskripte sind unter großzügigen Lizenzen offen verfügbar und laden andere ein, auf der Pipeline aufzubauen, den Datensatz zu erweitern oder neue Algorithmen zu benchmarken.
Was das für die zukünftige Zellbildgebung bedeutet
Für Nichtfachleute lautet die Kernbotschaft: Light My Cells liefert das Rohmaterial, das nötig ist, damit Computer lernen, mit schonenderen Formen der Mikroskopie ins Innere von Zellen zu blicken. Anstatt immer leuchtende Marker hinzuzufügen und damit Risiken einzugehen, werden Wissenschaftler zunehmend auf intelligente Software setzen können, die auf Sammlungen wie dieser trainiert wurde, um zu zeigen, wo wichtige Strukturen liegen. Die Datenbank löst die fluoreszenzfreie Bildgebung nicht allein, aber sie macht hochwertige, gut dokumentierte Beispiele für alle zugänglich und beschleunigt den Fortschritt hin zu weniger invasiven und besser skalierbaren Methoden, lebende Zellen in Aktion zu beobachten.
Zitation: Kauffmann, D., Gay, G., Mateos-Langerak, J. et al. 2D Multimodal Image Collection for Fluorescence Prediction from Transmitted Light Microscopy. Sci Data 13, 743 (2026). https://doi.org/10.1038/s41597-026-07004-w
Schlüsselwörter: Fluoreszenzmikroskopie, Durchlichtbildgebung, Tiefes Lernen, Bioimage-Datenbank, in-silico Kennzeichnung