Clear Sky Science · fr
Collection d’images multimodales 2D pour la prédiction de fluorescence à partir de la microscopie en lumière transmise
Voir les cellules sans préparation lourde
La biologie moderne s’appuie souvent sur des colorants fluorescents pour révéler ce qui se passe à l’intérieur des cellules vivantes, mais cela a un coût en temps, en argent et pour la santé des cellules. Cet article présente la base Light My Cells, une grande collection publique d’images au microscope conçue pour aider les ordinateurs à apprendre à recréer ces vues « lumineuses » à partir d’images plus douces et sans marquage. Pour quiconque s’intéresse à la façon dont l’intelligence artificielle peut réduire le besoin de colorants chimiques tout en montrant la vie intérieure des cellules, ce travail pose des bases importantes.
Pourquoi les cellules fluorescentes sont à la fois utiles et risquées
La microscopie par fluorescence permet aux scientifiques d’étiqueter des parties spécifiques d’une cellule pour les faire briller, rendant des structures comme le noyau ou les mitochondries faciles à suivre. Toutefois, la préparation des échantillons avec des colorants fluorescents est laborieuse, peut être coûteuse et expose les cellules à une lumière qui peut estomper le signal ou même les endommager. Ces problèmes s’aggravent lors d’expériences longues ou de grands projets de criblage, où des milliers d’images doivent être acquises. En revanche, des techniques simples en lumière transmise, comme le champ clair ou le contraste de phase, sont douces et sans marquage, mais elles ne révèlent pas directement quelles structures correspondent à quoi. L’idée centrale de Light My Cells est de combler cet écart en entraînant des ordinateurs à inférer des images de type fluorescence à partir de ces vues simples et non dommageables.
Une collection nationale d’images cellulaires diversifiées
Pour rendre cela possible, des spécialistes de l’imagerie de toute la France ont uni leurs forces pour constituer un jeu de données partagé et riche. La base Light My Cells regroupe 56 984 images bidimensionnelles réparties en 2 574 ensembles appariés, contributions de huit centres d’imagerie et de 30 études indépendantes. Chaque ensemble montre le même champ de cellules mammifères vivantes d’abord en lumière transmise, puis avec une ou plusieurs étiquettes fluorescentes mettant en évidence le noyau, les mitochondries, la tubuline ou l’actine. Les images ont été collectées sur une grande variété de microscopes et avec de nombreux types d’échantillons, capturant la variabilité rencontrée dans les laboratoires réels. Cette diversité est cruciale pour enseigner aux modèles d’apprentissage profond à gérer différents instruments, lignées cellulaires et conditions d’acquisition plutôt que de se suradapter à un unique dispositif parfaitement contrôlé.
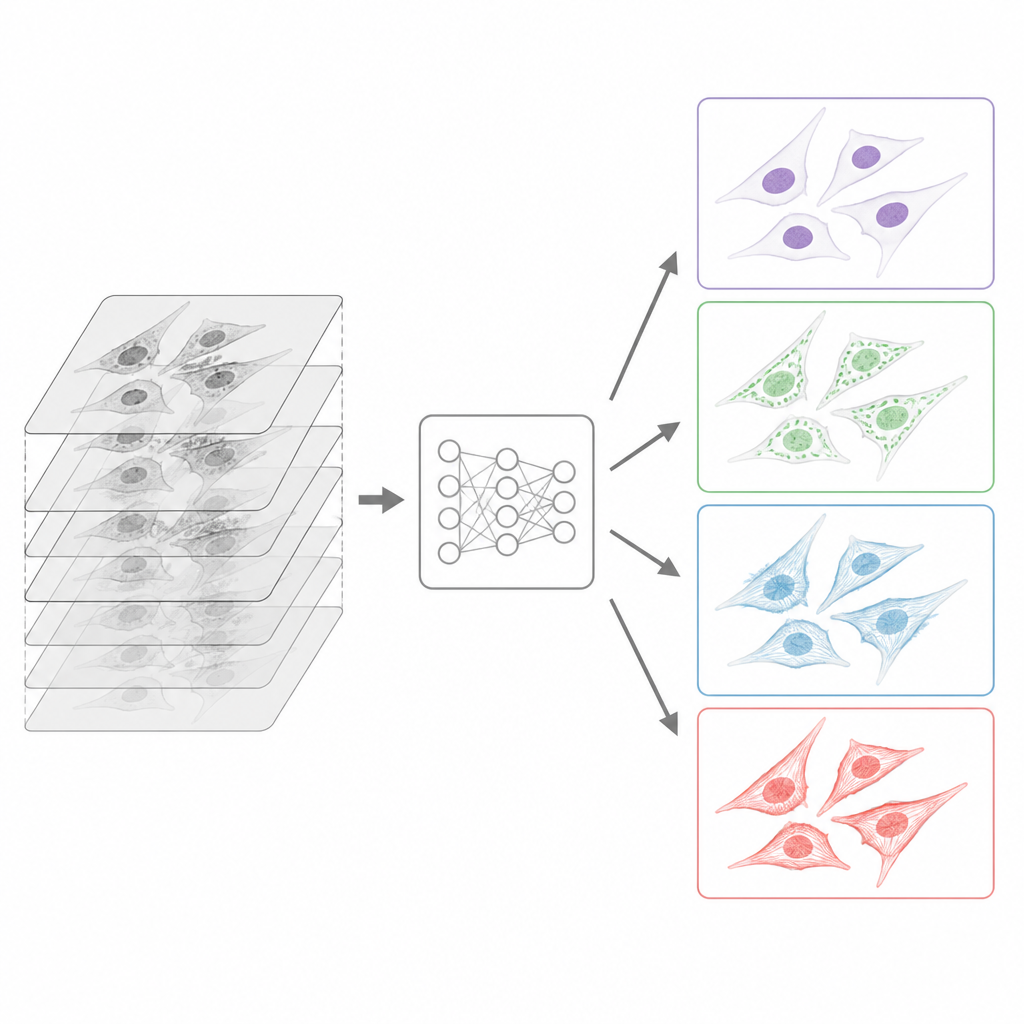
Comment les images ont été standardisées pour les ordinateurs
Parce que les données provenaient de nombreux sites, l’équipe a construit une chaîne de préparation soignée avant la mise à disposition de la collection. Tous les fichiers d’origine, produits dans de nombreux formats propriétaires de microscopes, ont été convertis en un format ouvert commun appelé OME-TIFF qui stocke à la fois l’image et des informations détaillées sur son acquisition. Les contributeurs ont rempli des modèles de métadonnées riches décrivant l’échantillon, le trajet optique, les objectifs et la stratégie de marquage, en suivant les recommandations communautaires pour des données d’imagerie réutilisables. Pour chaque pile d’images prises à différentes profondeurs, des algorithmes ont automatiquement choisi la tranche la mieux focalisée, en utilisant une méthode adaptée à la lumière transmise et une autre réglée pour le signal fluorescent. Alors que toutes les tranches en lumière transmise ont été conservées, chaque canal fluorescent a été réduit à un seul plan net, correspondant à la tâche d’apprentissage habituelle qui consiste à prédire une vue fluorescente bien focalisée à partir d’une entrée sans marquage.
Ce que contient la base et comment la qualité a été vérifiée
La ressource finale inclut plus de cinquante mille images en lumière transmise, principalement en champ clair mais aussi en contraste de phase et en contraste interférentiel différentiel, ainsi que plus de quatre mille images fluorescentes appariées. Le noyau et les mitochondries sont bien représentés, tandis que la tubuline et l’actine apparaissent moins souvent, créant un déséquilibre de classes naturel que les utilisateurs doivent prendre en compte lors de l’entraînement de modèles. Chaque étude de l’archive est documentée par des descriptions structurées du modèle biologique, du matériel d’imagerie et des paramètres d’acquisition, permettant aux utilisateurs de filtrer par contexte ou de comparer des conditions. Les auteurs ont également effectué des contrôles techniques pour supprimer les fichiers corrompus, vérifier la complétude des champs de métadonnées et confirmer que les plans de mise au point choisis correspondaient au jugement d’experts. Des scripts de test ont assuré que des outils courants tels qu’ImageJ, Napari et les bibliothèques Python standards peuvent ouvrir et traiter facilement les images.
Comment les chercheurs peuvent utiliser cette ressource ouverte
Au-delà de son usage initial dans un défi d’apprentissage profond, la base Light My Cells est destinée à servir de banc d’essai général pour des méthodes qui traduisent ou analysent des images sans marquage. Le caractère apparié des données la rend adaptée à des tâches telles que la prédiction de fluorescence à partir de la lumière transmise, la segmentation des structures cellulaires ou le profilage des états cellulaires sans colorants supplémentaires. Étant donné que les piles en lumière transmise sont préservées, les chercheurs peuvent aussi explorer des modèles qui exploitent l’information de profondeur ou l’estimation de la mise au point. Toutes les données et le code de préparation sont disponibles en open source sous des licences permissives, invitant d’autres à étendre la chaîne, enrichir l’ensemble ou évaluer de nouveaux algorithmes.
Ce que cela signifie pour l’imagerie cellulaire future
Pour les non spécialistes, le message principal est que Light My Cells fournit la matière première nécessaire pour apprendre aux ordinateurs à voir l’intérieur des cellules en utilisant des formes de microscopie plus douces. Plutôt que d’ajouter systématiquement des marqueurs fluorescents au risque d’endommager les cellules, les scientifiques pourront de plus en plus s’appuyer sur des logiciels intelligents entraînés sur des collections comme celle-ci pour révéler la localisation des structures clés. La base ne résout pas à elle seule l’imagerie sans fluorescence, mais elle rend des exemples de haute qualité et bien documentés accessibles à tous, accélérant les progrès vers des méthodes d’observation des cellules vivantes moins invasives et plus évolutives.
Citation: Kauffmann, D., Gay, G., Mateos-Langerak, J. et al. 2D Multimodal Image Collection for Fluorescence Prediction from Transmitted Light Microscopy. Sci Data 13, 743 (2026). https://doi.org/10.1038/s41597-026-07004-w
Mots-clés: microscopie par fluorescence, imagerie en lumière transmise, apprentissage profond, base de données bioimage, étiquetage in silico