Clear Sky Science · nl
2D multimodale beeldverzameling voor fluorescentievoorspelling vanuit doorgelaten-lichtmicroscopie
Cellen zien zonder zware voorbereiding
De moderne biologie vertrouwt vaak op gloedende kleurstoffen om te laten zien wat er in levende cellen gebeurt, maar dat brengt kosten met zich mee op het gebied van tijd, geld en de gezondheid van cellen. Dit artikel presenteert de Light My Cells-database, een grote openbare verzameling microscoopbeelden die computers helpt te leren om die gloeiende weergaven te reconstrueren vanuit zachtere, labelvrije beelden. Voor iedereen die wil weten hoe kunstmatige intelligentie de behoefte aan chemische kleuring kan verminderen en toch het innerlijke leven van cellen kan tonen, legt dit werk de basis.
Waarom gloeiende cellen zowel nuttig als riskant zijn
Fluorescentiemicroscopie stelt wetenschappers in staat specifieke delen van een cel te markeren zodat ze oplichten, waardoor structuren zoals de kern of mitochondriën gemakkelijk te volgen zijn. Het prepareren van monsters met fluorescentiekleurstoffen is echter arbeidsintensief, kan duur zijn en stelt cellen bloot aan licht dat het signaal kan doen vervagen of hen zelfs kan beschadigen. Deze problemen nemen toe bij lange experimenten of grootschalige screeningsprojecten, waar duizenden beelden gemaakt moeten worden. In tegenstelling tot dat zijn eenvoudige doorgelaten-lichttechnieken, zoals bright-field of fasecontrast, zacht en labelvrij, maar geven ze niet direct aan welke structuren welke zijn. Het centrale idee achter Light My Cells is deze kloof te overbruggen door computers te trainen om fluorescentieachtige beelden af te leiden uit deze eenvoudige, niet-schadelijke weergaven.
Een landelijk samengestelde collectie diverse celbeelden
Om dit mogelijk te maken, bundelden beeldvormingsexperts uit heel Frankrijk hun krachten om een rijke, gedeelde dataset op te bouwen. De Light My Cells-database verzamelt 56.984 tweedimensionale beelden gegroepeerd in 2.574 gekoppelde sets, bijgedragen door acht beeldvormingscentra en 30 onafhankelijke studies. Elke set toont hetzelfde veld van levende zoogdiercellen eerst met doorgelaten licht en vervolgens met één of meerdere fluorescentielabels die de kern, mitochondriën, tubuline of actine benadrukken. De beelden werden verzameld met een breed scala aan microscopen en met veel verschillende monstertypen, waarmee de variatie wordt vastgelegd die echte laboratoria dagelijks tegenkomen. Deze diversiteit is cruciaal voor het trainen van deep learning-modellen die met verschillende instrumenten, cellijnen en acquisitiecondities overweg kunnen in plaats van overmatig aan te passen aan één nette opstelling.
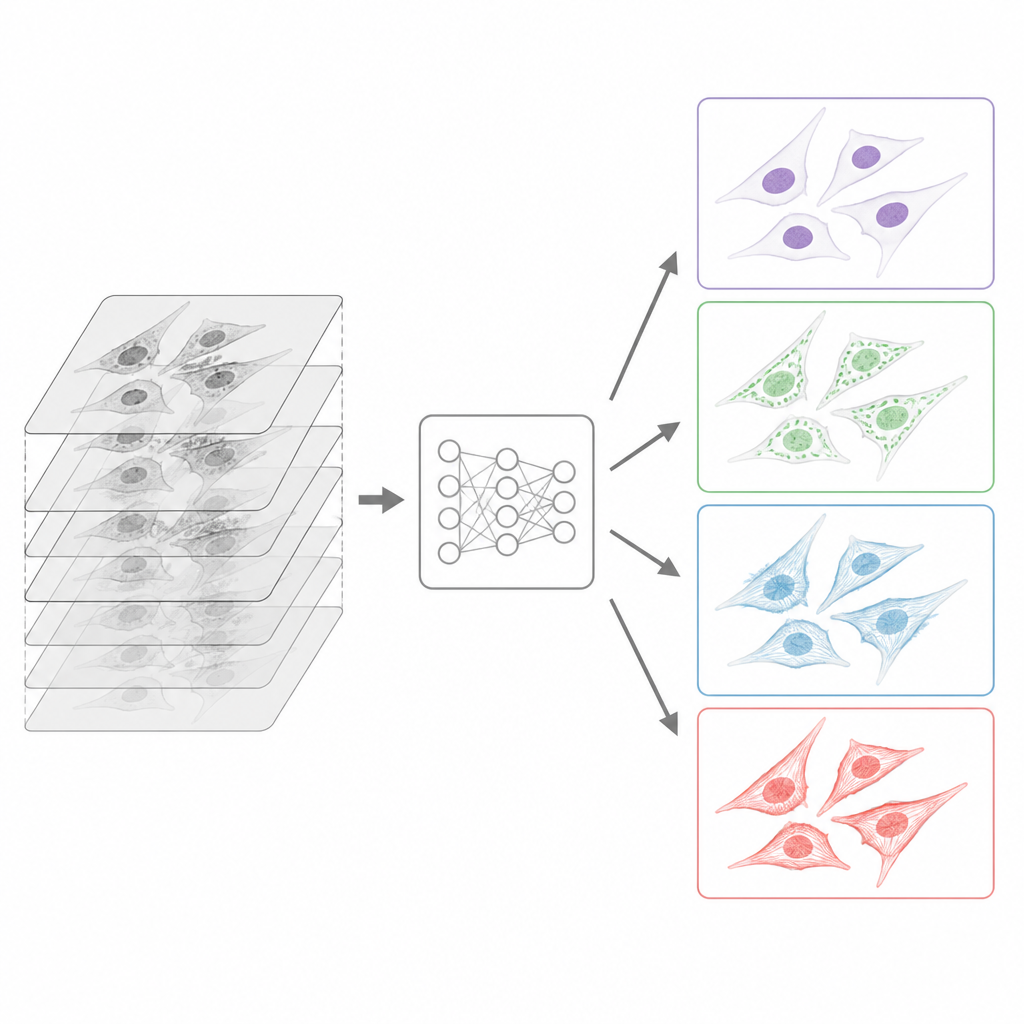
Hoe de beelden voor computers gestandaardiseerd werden
Aangezien de data uit veel locaties kwamen, bouwde het team een zorgvuldig voorbereidingsproces op voordat de collectie werd vrijgegeven. Alle originele bestanden, geproduceerd in vele propriëtaire microscoopformaten, werden geconverteerd naar een gemeenschappelijk, open formaat genaamd OME TIFF dat zowel de afbeelding als gedetailleerde informatie over de opname opslaat. Bijdragers vulden uitgebreide metadata-sjablonen in die het monster, het lichtpad, de objectieven en de labelstrategie beschrijven, volgens community-richtlijnen voor herbruikbare beelddata. Voor elke stapel beelden die op verschillende dieptes waren genomen, kozen algoritmen automatisch de best gefocuste laag, met een methode afgestemd op doorgelaten licht en een andere op fluorescentiesignaal. Terwijl alle doorgelaten-lichtlagen bewaard bleven, werd elk fluorescentiekanaal gereduceerd tot één scherpe vlakke afbeelding, passend bij de typische leertaak om één goed gefocust fluorescentiebeeld te voorspellen vanaf labelvrije input.
Wat de database bevat en hoe de kwaliteit werd gecontroleerd
De uiteindelijke bron bevat meer dan vijftigduizend doorgelaten-lichtbeelden, voornamelijk bright-field maar ook fasecontrast en differentiële interferentiecontrast, plus meer dan vierduizend gekoppelde fluorescentiebeelden. De kern en mitochondriën zijn goed vertegenwoordigd, terwijl tubuline en actine minder vaak voorkomen, wat een natuurlijke klasse-ongelijkheid oplevert die gebruikers in overweging moeten nemen bij het trainen van modellen. Elke studie in het archief is gedocumenteerd met gestructureerde beschrijvingen van het biologische model, de beeldvormingshardware en de acquisitie-instellingen, zodat gebruikers kunnen filteren op context of condities kunnen vergelijken. De auteurs voerden ook technische controles uit om corrupte bestanden te verwijderen, te verifiëren dat metadata-velden compleet waren en te bevestigen dat de gekozen focusvlakken overeenkwamen met deskundig oordeel. Testscripts zorgden ervoor dat gangbare tools zoals ImageJ, Napari en standaard Python-bibliotheken de beelden eenvoudig kunnen openen en verwerken.
Hoe onderzoekers deze open bron kunnen gebruiken
Naast het oorspronkelijke gebruik in een deep learning-wedstrijd is de Light My Cells-database bedoeld als een algemeen testplatform voor methoden die labelvrije beelden vertalen of analyseren. Het gepaarde karakter van de data maakt het geschikt voor taken zoals het voorspellen van fluorescentie vanuit doorgelaten licht, het segmenteren van celstructuren of het profileren van celtoestanden zonder extra kleurstoffen. Omdat de doorgelaten-lichtstapels bewaard blijven, kunnen onderzoekers ook modellen verkennen die gebruikmaken van diepte-informatie of focusschatting. Alle data en voorbereidingscode zijn openlijk beschikbaar onder permissieve licenties, en nodigen anderen uit om op de pijplijn voort te bouwen, de dataset uit te breiden of nieuwe algoritmen te benchmarken.
Wat dit betekent voor toekomstige celbeeldvorming
Voor niet-specialisten is de kernboodschap dat Light My Cells het ruwe materiaal levert dat nodig is om computers te leren in cellen te kijken met behulp van zachtere vormen van microscopie. In plaats van voortdurend gloeiende labels toe te voegen en risico op schade te lopen, kunnen wetenschappers steeds meer vertrouwen op slimme software die is getraind op collecties als deze om te onthullen waar belangrijke structuren liggen. De database lost fluorescentievrije beeldvorming niet op zichzelf op, maar maakt hoogwaardige, goed gedocumenteerde voorbeelden voor iedereen beschikbaar, wat de vooruitgang versnelt naar minder invasieve en beter schaalbare manieren om levende cellen in actie te bekijken.
Bronvermelding: Kauffmann, D., Gay, G., Mateos-Langerak, J. et al. 2D Multimodal Image Collection for Fluorescence Prediction from Transmitted Light Microscopy. Sci Data 13, 743 (2026). https://doi.org/10.1038/s41597-026-07004-w
Trefwoorden: fluorescentiemicroscopie, doorgelaten-lichtbeeldvorming, deep learning, bio-beelddatabase, in silico labeling