Clear Sky Science · sv
Sen2GF3Floods: Ett referensdataset om översvämningar från flera källor med dubbel-tids- och aktiv inlärningsannotering
Varför smartare översvämningskartor spelar roll
Översvämningar hör till de mest förödande naturkatastroferna, men när floder svämmar över eller städer dränks av kraftigt regn har insatsgrupper fortfarande svårt att exakt avgöra hur långt vattnet har spritt sig. Denna artikel presenterar Sen2GF3Floods, en ny, storskalig samling satellitbilder och datorvänliga översvämningskartor avsedd att hjälpa artificiell intelligens (AI) att snabbt och pålitligt spåra översvämningsvatten. Genom att kombinera olika typer av satellitobservationer tagna före och efter katastrofer, och genom att använda en smart, kostnadsbesparande metod för att märka översvämmade områden, syftar arbetet till att göra realtidskvalitativa översvämningskartor mycket mer tillgängliga.
Att se vatten från rymden på nya sätt
För att kartlägga översvämningar från rymden har man länge förlitat sig på två huvudtyper av satellitdata. Optiska bilder, liknande mycket detaljerade fotografier, kan tydligt visa floder, åkrar och kvarter—men moln och kraftigt regn kan blockera sikten just när översvämningar inträffar. Radarbilder, skapade genom att studsa mikrovågssignaler mot marken, kan se genom moln och fungerar både dag och natt, men de är brusigare och svårare för människor att tolka. Forskarna bakom Sen2GF3Floods kombinerar styrkorna hos båda: tydliga optiska bilder tagna före en översvämning och radarobservationer fångade under översvämningen. De optiska bilderna ger en detaljerad ögonblicksbild av hur landskapet normalt ser ut, medan radarbildarna avslöjar var vatten faktiskt sprider sig när katastrofen inträffar.

Bygga ett rikt bibliotek av översvämningshändelser
För att vara användbart för moderna AI-tekniker måste ett översvämningsdataset vara stort, varierat och noggrant märkt—och det är precis vad Sen2GF3Floods erbjuder. Det samlar satellitpatchar från nio stora översvämningshändelser i Kina, med områden som omfattar floder, jordbruksmarker, städer och berg. För varje plats samlade teamet fyra färgband från Europas Sentinel-2 optiska satelliter och två radarbands från Kinas Gaofen-3-uppdrag, alla med 10-metersupplösning. Dessa bilder delades upp i över 21 000 små brickor som maskininlärningsmodeller kan bearbeta. Varje bricka levereras med en enkel karta som markerar vilka pixlar som var översvämmade och vilka som inte var det, så att algoritmer kan lära sig de subtila skillnaderna mellan normalt vatten, tillfällig översvämning, skuggor och torr mark.
Låta datorn hjälpa bestämma vad experter bör märka
Ett stort hinder vid skapandet av sådana dataset är att rita exakta översvämningskonturer för hand. För att minska denna arbetsbörda utformade författarna en tredelad, dubbel-tids annoteringsmetod. Först genererade de automatiskt en grov karta över permanent vatten från den optiska bilden före översvämningen och en annan från radarbilden efter översvämningen, och jämförde sedan de två för att uppskatta var nytt vatten hade uppkommit. Därefter förfinade människliga experter dessa grova kartor med hjälp av högupplösta bakgrundsbilder och korrigerade svåra områden som risfält och smala kanaler. Slutligen tränade de ett segmenteringsnätverk—en sofistikerad mönsterigenkänningsmodell—för att förutsäga översvämningar över de omärkta brickorna och mätte var modellen var mest osäker. Endast de "svåra" brickorna, där modellen hade problem, skickades tillbaka till experter för noggrann märkning. Denna cykel av träning, osäkerhetsmätning och målinriktad korrigering gjorde det möjligt för teamet att växa datasetet samtidigt som manuellt arbete hölls i schack.
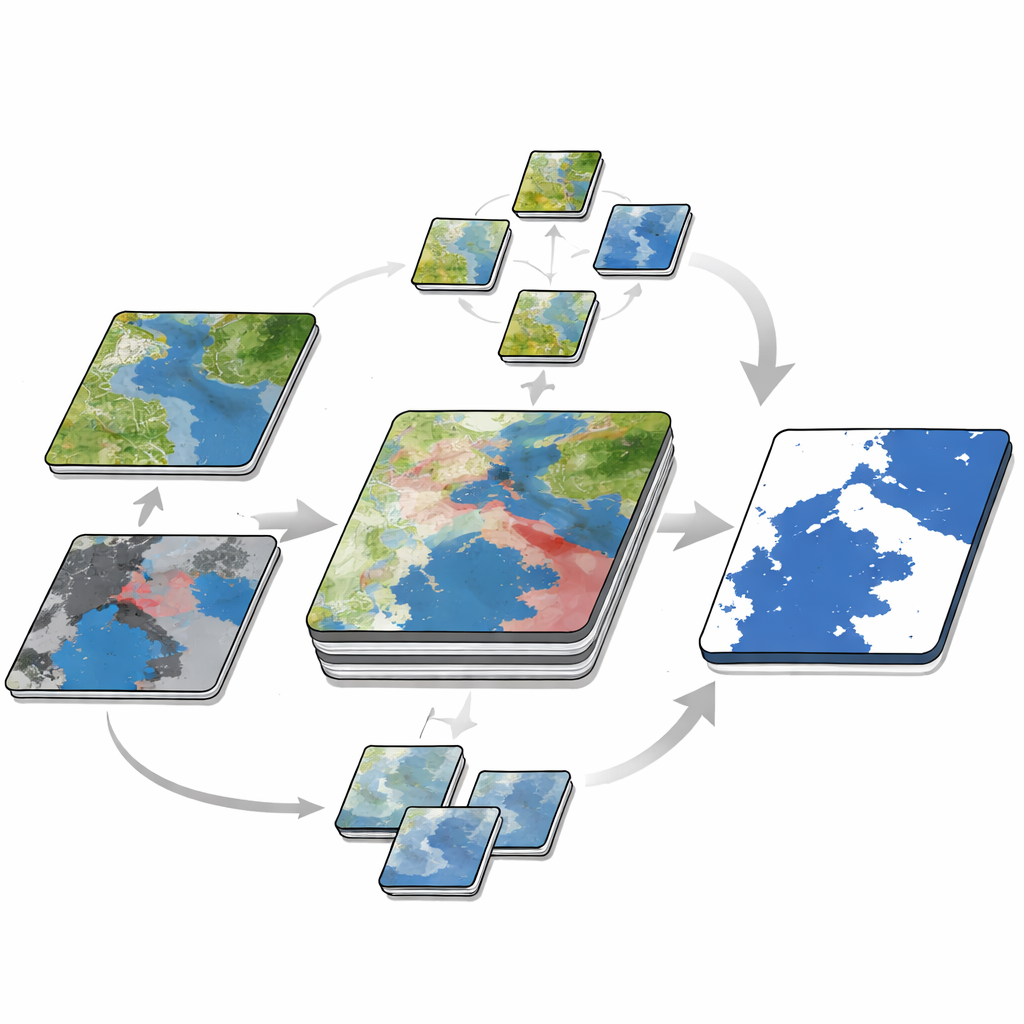
Testa hur väl maskiner lär sig av datan
När datasetet var sammanställt utvärderade forskarna flera ledande bildsegmenteringsmodeller, inklusive U-Net, U-Net++, DeepLabV3+, DANet och SegFormer. Överlag presterade modellerna mycket bra, klassificerade majoriteten av pixlarna korrekt och fångade både vidsträckta översvämningsslätter och fina flodgrenar. U-Net++ gav den bästa totala balansen mellan noggrannhet och fullständighet. Experimenten undersökte också djupare frågor: Hur många märkta brickor behövs egentligen innan noggrannheten slutar förbättras märkbart? Vilka kombinationer av optiska och radarband fungerar bäst? Och kan en modell tränad på Gaofen-3-radar överföras till en annan radarsatellit, Sentinel-1, utan omträning från grunden? Resultaten visar att användning av både färg- och närinfraröda optiska band tillsammans med dubbla radarkanaler ger de starkaste översvämningskartorna, att prestandan planar ut när omkring tusen märkta brickor finns tillgängliga, och att modeller tränade på Gaofen-3 faktiskt kan tillämpas på Sentinel-1 med lovande resultat.
Vad detta betyder för framtida översvämningsinsatser
Enkelt uttryckt levererar Sen2GF3Floods-projektet ett högkvalitativt "träningsgym" för AI som upptäcker översvämningar. Genom att förena klara vyer av landskapet före en översvämning med radarögonblicksbilder tagna under händelsen, och genom att använda ett aktivt inlärningsschema som fokuserar expertinsatser där de gör mest nytta, har författarna byggt ett dataset som gör det möjligt för datorer att känna igen översvämningar snabbt och pålitligt över många terränger. Denna grund bör hjälpa räddningsledare och forskare att skapa snabba, storskaliga översvämningskartor med mindre manuellt arbete, även när moln blockerar himlen eller när data måste komma från olika satelliter. Med tiden kan en utvidgning av denna metod till fler städer och jordbruksregioner förvandla satellitströmmar till praktiska, nästintill realtidsverktyg för att skydda människor och infrastruktur mot stigande vatten.
Citering: Chen, W., Zhu, Y., Han, W. et al. Sen2GF3Floods: A Benchmark Multi-Source Flood Dataset with Dual-Temporal and Active Learning Annotation. Sci Data 13, 540 (2026). https://doi.org/10.1038/s41597-026-06929-6
Nyckelord: översvämningskartläggning, fjärranalys, satellitbilder, deep learning, katastrofinsats