Clear Sky Science · pl
Sen2GF3Floods: Wzorcowy wieloźródłowy zbiór danych o powodzi z adnotacjami dwu‑czasowymi i uczeniem aktywnym
Dlaczego ważne są inteligentniejsze mapy powodzi
Powodzie należą do najbardziej niszczycielskich katastrof naturalnych, a gdy rzeki wylewają lub miasta zostają zalane przez gwałtowne ulewy, służby ratownicze wciąż mają trudności z dokładnym określeniem zasięgu wody. W artykule przedstawiono Sen2GF3Floods — nowy, obszerne zbiory obrazów satelitarnych i przygotowanych do obróbki map powodzi, zaprojektowany tak, aby pomóc sztucznej inteligencji szybko i niezawodnie wskazywać rozlewiska. Poprzez połączenie różnych typów zdjęć satelitarnych wykonanych przed i po zdarzeniach oraz zastosowanie sprytnej, oszczędnej metody etykietowania obszarów zalanych, praca ta ma na celu upowszechnienie dostępu do szybkich i wysokiej jakości map powodzi.
Nowe sposoby obserwacji wody z kosmosu
Mapowanie powodzi z kosmosu od dawna opiera się na dwóch głównych rodzajach danych satelitarnych. Obrazy optyczne, przypominające bardzo szczegółowe zdjęcia fotograficzne, wyraźnie pokazują rzeki, pola i zabudowania — ale chmury i ulewy mogą zasłonić widok właśnie wtedy, gdy dochodzi do powodzi. Obrazy radarowe, powstające przez odbicie sygnałów mikrofalowych od powierzchni, prześwietlają chmury i działają w dzień i w nocy, lecz są zaszumione i trudniejsze do interpretacji dla ludzi. Autorzy Sen2GF3Floods łączą zalety obu: wyraźne obrazy optyczne sprzed powodzi oraz obrazy radarowe wykonane w trakcie zdarzenia. Obrazy optyczne dostarczają szczegółowej informacji o normalnym wyglądzie krajobrazu, a radar ujawnia, gdzie woda rozprzestrzenia się podczas katastrofy.

Budowanie obszernej biblioteki zdarzeń powodziowych
Aby zbiór danych był użyteczny dla współczesnych technik AI, musi być duży, zróżnicowany i starannie oznaczony — i właśnie to oferuje Sen2GF3Floods. Zawiera on fragmenty obrazów satelitarnych z dziewięciu dużych zdarzeń powodziowych w Chinach, obejmujących rzeki, tereny rolnicze, miasta i góry. Dla każdego miejsca zespół zebrał cztery pasma kolorystyczne z optycznych satelitów Sentinel‑2 oraz dwa pasma radarowe z misji Gaofen‑3, wszystko w rozdzielczości 10 metrów. Obrazy zostały pocięte na ponad 21 000 małych kafelków, które modele uczenia maszynowego mogą przetwarzać. Każdy kafelek zawiera prostą mapę wskazującą, które piksele były zalane, a które nie, dzięki czemu algorytmy mogą uczyć się subtelnych różnic między normalną wodą, przejściowymi zalaniami, cieniami i suchym lądem.
Pozwalanie komputerowi decydować, co powinni oznaczać eksperci
Główną barierą w tworzeniu takich zbiorów jest ręczne rysowanie dokładnych obrysów zalania. Aby zmniejszyć to obciążenie, autorzy opracowali trzyetapowe, dwu‑czasowe podejście do adnotacji. Najpierw automatycznie wygenerowali szacunkową mapę wód stałych z obrazu optycznego przed powodzią oraz kolejną z obrazu radarowego po powodzi, a następnie porównali je, by oszacować, gdzie pojawiła się nowa woda. Następnie eksperci ludzie dopracowali te przybliżone mapy, korzystając z obrazów tła o wysokiej rozdzielczości, korygując trudne obszary, takie jak pola ryżowe i wąskie koryta. Na końcu wytrenowali sieć segmentacyjną — zaawansowany model rozpoznawania wzorców — aby przewidywała powodzie na nieoznaczonych kafelkach i zmierzyli, gdzie model był najbardziej niepewny. Tylko te „trudne” kafelki, w których model miał problemy, trafiały z powrotem do ekspertów do starannego oznaczenia. Ten cykl trenowania, pomiaru niepewności i ukierunkowanej korekty pozwolił zespołowi rozszerzać zbiór danych przy jednoczesnym ograniczeniu pracy ręcznej.
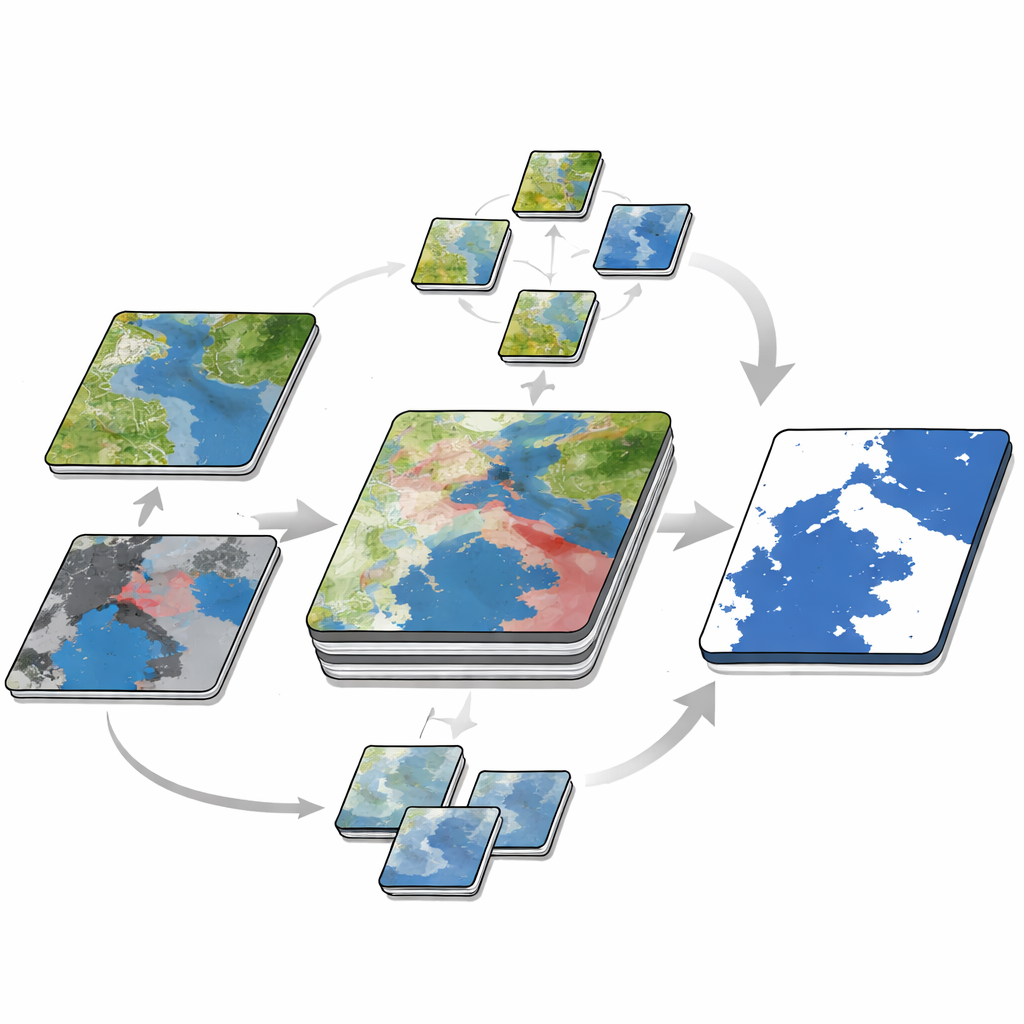
Testowanie, jak dobrze maszyny uczą się z danych
Po złożeniu zbioru danych badacze ocenili kilka wiodących modeli segmentacji obrazów, w tym U‑Net, U‑Net++, DeepLabV3+, DANet i SegFormer. We wszystkich przypadkach modele radziły sobie bardzo dobrze, poprawnie klasyfikując zdecydowaną większość pikseli i wychwytując zarówno rozległe obszary zalane, jak i drobne odgałęzienia rzeczne. U‑Net++ zapewnił najlepsze ogólne wyważenie dokładności i kompletności. Eksperymenty zgłębiały też inne pytania: Ile naprawdę oznaczonych kafelków jest potrzebnych, zanim dokładność przestanie znacząco rosnąć? Które kombinacje pasm optycznych i radarowych działają najlepiej? I czy model wytrenowany na radarze Gaofen‑3 można zastosować do innego radaru, Sentinel‑1, bez ponownego treningu od zera? Wyniki pokazują, że użycie zarówno pasm kolorowych i bliskiej podczerwieni z optyki wraz z dwiema kanalami radarowymi daje najsilniejsze mapy powodzi, że wydajność osiąga plateau przy około tysiącu oznaczonych kafelków, oraz że modele wytrenowane na Gaofen‑3 można obiecująco zastosować do Sentinel‑1.
Co to oznacza dla przyszłej reakcji na powodzie
Mówiąc prosto, projekt Sen2GF3Floods dostarcza wysokiej jakości „sali treningowej” dla systemów AI wykrywających powodzie. Poprzez łączenie wyraźnych widoków krajobrazu sprzed powodzi z radarowymi migawkami wykonanymi w trakcie zdarzenia oraz stosowanie schematu uczenia aktywnego, który koncentruje wysiłek ekspertów tam, gdzie ma to największe znaczenie, autorzy zbudowali zbiór danych, który pozwala komputerom szybko i niezawodnie rozpoznawać powodzie w różnych typach terenu. Ta podstawa powinna pomóc zarządcom kryzysowym i naukowcom w generowaniu szybkich, dużych map powodzi przy mniejszym nakładzie pracy ręcznej, nawet gdy niebo zasłonią chmury lub gdy dane pochodzą z różnych satelitów. Z czasem rozszerzenie tego podejścia na kolejne miasta i tereny rolnicze mogłoby przekształcić strumienie danych satelitarnych w praktyczne, niemal w czasie rzeczywistym narzędzie chroniące ludzi i infrastrukturę przed wzrastającą wodą.
Cytowanie: Chen, W., Zhu, Y., Han, W. et al. Sen2GF3Floods: A Benchmark Multi-Source Flood Dataset with Dual-Temporal and Active Learning Annotation. Sci Data 13, 540 (2026). https://doi.org/10.1038/s41597-026-06929-6
Słowa kluczowe: mapowanie powodzi, teledetekcja, obrazy satelitarne, uczenie głębokie, reakcja na katastrofy