Почему маленькие движения могут раскрывать большие тайны
От бродячих бактерий до блуждающих клеток в нашем организме — живые существа редко движутся ровно одинаково. У каждого есть свои особенности, но эксперименты часто фиксируют лишь короткие, зашумлённые фрагменты их движения. В этой работе показано, как превратить такие фрагментированные треки в ясную картину реального разнообразия популяции, используя статистический инструмент, который работает даже когда движение выглядит случайным и измеряются только позиции, а не скорости.
Наблюдая многих маленьких путешественников
Современные микроскопы и камеры могут отслеживать рои клеток, микроорганизмов или других «активных частиц», когда они ползают, плавают или скользят. Но на практике каждая клетка может исчезать из поля зрения спустя короткое время — она уходит за границы кадра или заслоняется соседями. Вместо нескольких длинных фильмов одной и той же особи учёные получают много коротких треков от множества разных частиц. К тому же даже генетически идентичные микробы или клетки не движутся одинаково: одни более настойчивы в направлении, другие более хаотичны, а некоторые по-разному реагируют на окружающую среду. Игнорирование этой индивидуальности может привести к вводящим в заблуждение выводам о поведении всей группы.
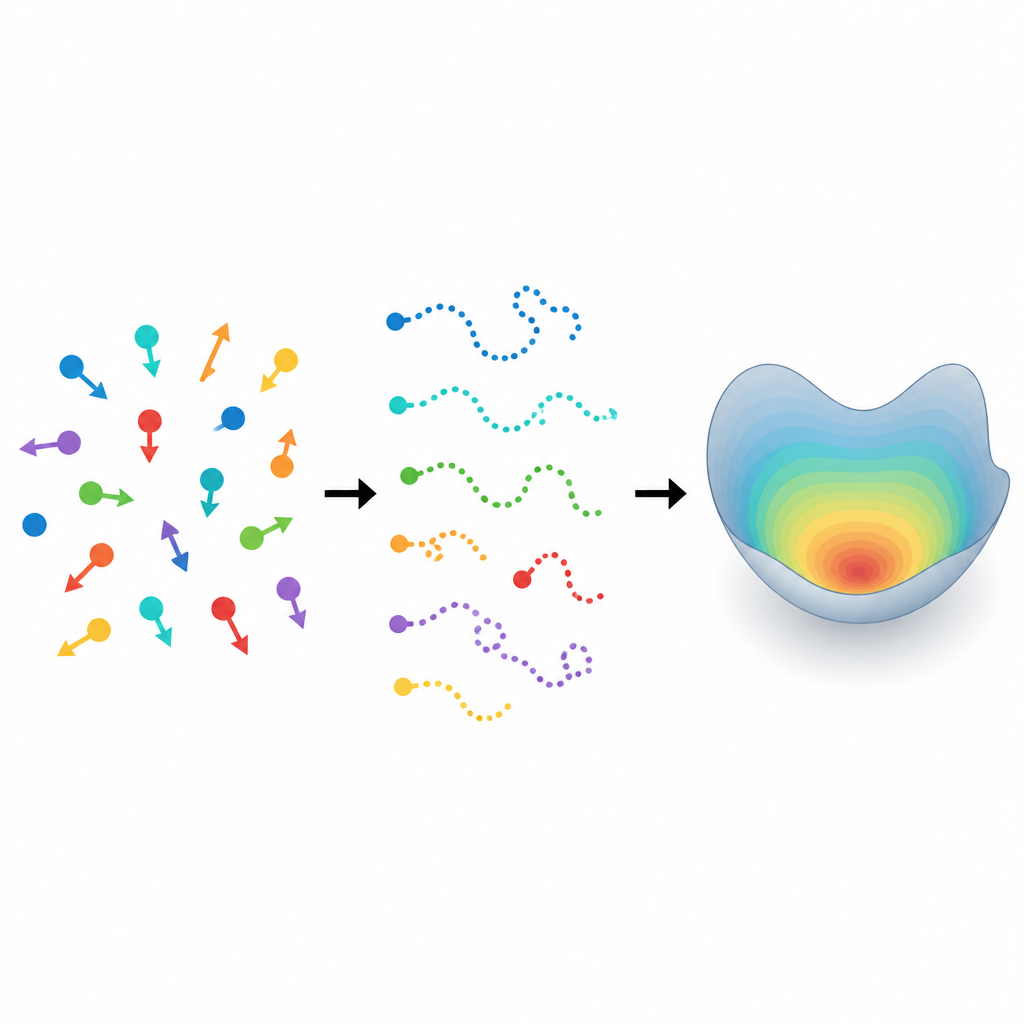
От случайных треков к скрытым законам Figure 1. Множество различных движущихся частиц даёт короткие треки, которые раскрывают скрытую картину разнообразия их движения.
Для описания такого движения исследователи часто используют модели Ланжевена: математические правила, которые трактуют движение как сочетание упорядоченных трендов и случайных толчков. Для многих активных систем недостаточно смотреть только на изменения положения, потому что истинные скорости флуктуируют во времени и вносят память в движение. Это делает наблюдаемые позиции немарковскими, то есть следующий шаг зависит не только от текущего состояния. Стандартные подходы, оценивающие параметры модели по покадровым изменениям, могут тогда оказаться смещёнными, особенно когда измеряются только позиции, а истинные скорости скрыты. Авторы показывают, что наивные методы систематически ошибаются в оценках таких ключевых величин, как скорость смены направления частиц или сила случайных толчков.
Более умный способ прочитать зашумлённые данные
Суть статьи — новый способ аппроксимировать, насколько правдоподобны данные при заданном наборе параметров модели. Вместо того чтобы притворяться, что грубые скорости, получаемые разностями позиций, ведут себя как истинные мгновенные скорости, метод аккуратно учитывает, что наблюдаемое движение сглажено по коротким временным окнам. Математически это приводит к описанию, в котором эти «секантные скорости» возбуждаются «цветным» шумом с определёнными короткодействующими корреляциями. Улавливая эти корреляции в компактной матрице с простой структурой, авторы выводят формулу правдоподобия, которую можно быстро вычислять, даже для длинных треков с большим числом точек данных.
От отдельных особей к популяции Figure 2. Короткие зашумлённые траектории объединяются в более чёткий профиль популяции путём взвешивания всех возможных параметров движения по их правдоподобию.
Записав, насколько вероятен отдельный трек при заданных параметрах, авторы делают следующий шаг и позволяют этим параметрам варьироваться от частицы к частице. Они рассматривают всю популяцию как выборку из неизвестного распределения и спрашивают, какое распределение лучше всего объясняет все наблюдаемые треки одновременно. Для решения они используют схему ожидание–максимизация (expectation–maximization), которая чередует оценку того, насколько вероятны разные значения параметров для каждой траектории, и обновление общего распределения по популяции. Этот подход «полного правдоподобия» превосходит более простые двухшаговые методы, которые сначала аппроксимируют каждый трек по отдельности, а затем подгоняют распределение по полученным точечным оценкам, особенно когда траектории коротки и неопределённость по каждому индивидууму велика.
Понимание степени нашей уверенности
Помимо предоставления наилучшей оценки популяционной изменчивости, рамки метода также дают способ количественно оценить неопределённость этой картины. Исследуя, насколько остро правдоподобие сосредоточено вокруг своего максимума, авторы вычисляют матрицу Гессе, обратная которой даёт оценку ожидаемого разброса выведённых параметров популяции при повторных экспериментах. Это даёт области доверия, показывающие, насколько может сдвинуться оценённое распределение из‑за ограниченности данных. Тесты на смоделированных данных, включая модели активных частиц с предпочитаемыми скоростями и вращательной склонностью, показывают, что метод надёжно восстанавливает заданную неоднородность по мере увеличения плотности выборки и длины траекторий.
Что это значит для изучения живого движения
Проще говоря, статья предлагает рецепт разделения двух источников случайности в данных о движении: случайных дрожаний каждой отдельной особи во времени и реальных различий между особями в популяции. Правильно обрабатывая короткие треки с измерениями только позиций и скрытые скорости за ними, метод даёт более ясное и честное представление о том, насколько разнообразна группа движущихся частиц или клеток, и насколько высока наша уверенность в этом представлении. Это прокладывает путь к более детализированным, основанным на данных моделям сложных подвижных систем — от мигрирующих клеток в тканях до самоприводимых частиц в инженерных материалах.
Цитирование: Albrecht, J., Opper, M. & Großmann, R. A Likelihood Approach for Inference of Population Heterogeneity in Particle Ensembles with Second-Order Langevin Dynamics.
Commun Phys9, 165 (2026). https://doi.org/10.1038/s42005-026-02670-z