Perché i piccoli moti possono rivelare grandi segreti
Dai batteri in movimento alle cellule erranti nel nostro corpo, gli esseri viventi raramente si muovono esattamente allo stesso modo. Ogni individuo ha le proprie particolarità, eppure gli esperimenti spesso catturano solo frammenti brevi e rumorosi del loro moto. Questo studio mostra come trasformare tali tracce frammentarie in un quadro chiaro di quanto sia realmente variegata una popolazione, usando uno strumento statistico che funziona anche quando il moto sembra casuale e vengono registrate solo le posizioni, non le velocità.
Osservare molti piccoli viaggiatori
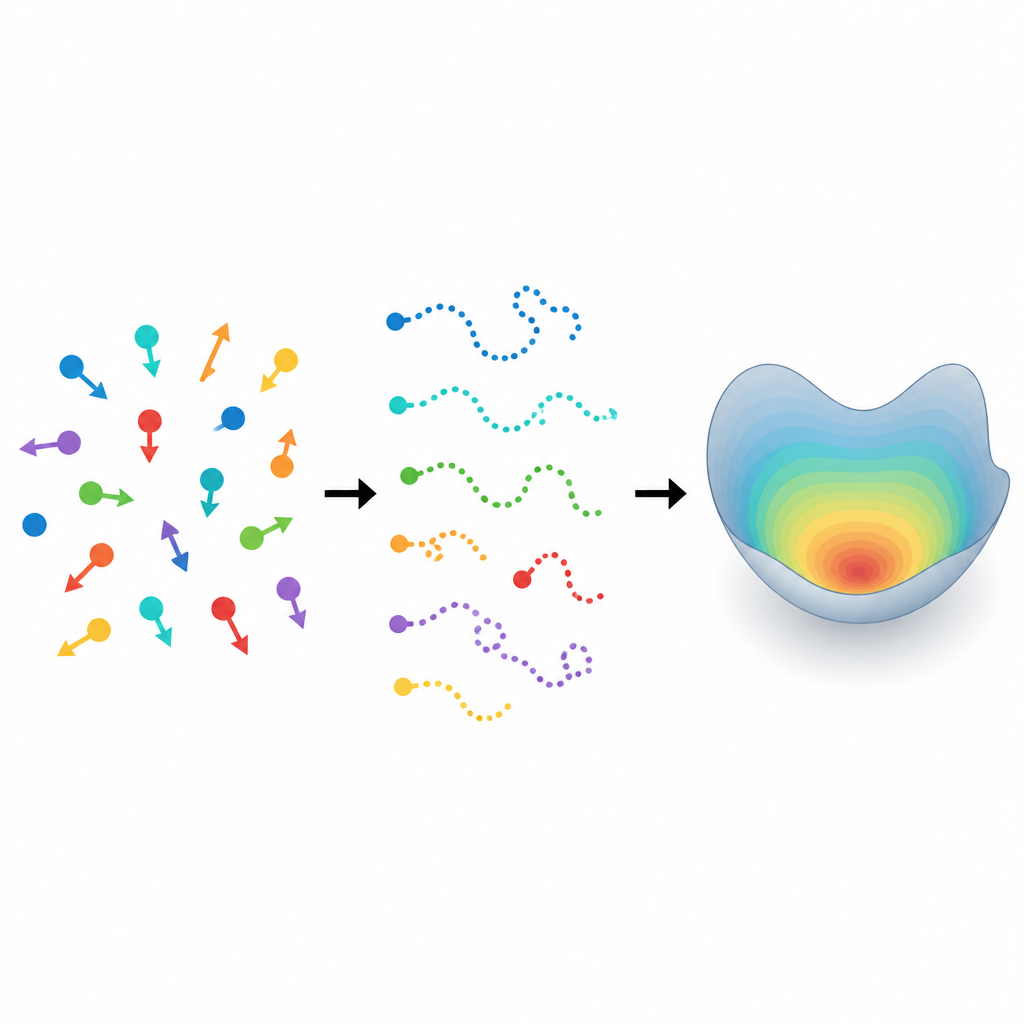
Microscopi e telecamere moderne possono seguire sciami di cellule, microrganismi o altre “particelle attive” mentre strisciano, nuotano o scivolano. Ma nella pratica, ogni cellula può scomparire dalla vista dopo poco tempo perché esce dal campo visivo o è oscurata dai vicini. Invece di pochi lunghi filmati dello stesso individuo, gli scienziati raccolgono molte tracce brevi da molte particelle diverse. Inoltre, anche microrganismi o cellule geneticamente identici non si muovono allo stesso modo: alcuni sono più persistenti, altri più irregolari e alcuni reagiscono diversamente all’ambiente. Ignorare questa individualità può portare a conclusioni fuorvianti sul comportamento dell’intero gruppo.
Dalle tracce casuali a regole nascoste Figure 1. Molte particelle in movimento generano tracce brevi che rivelano un sottostante schema di diversità nel loro moto.
Per comprendere tali moti, i ricercatori li descrivono spesso con modelli di Langevin: regole matematiche che trattano il movimento come la somma di tendenze deterministiche e colpi casuali. Per molti sistemi attivi non basta considerare le sole variazioni di posizione, perché le velocità sottostanti fluttuano nel tempo e introducono memoria nel moto. Ciò rende le posizioni osservate non markoviane, nel senso che il passo successivo dipende da più del solo stato corrente. Gli approcci standard che stimano i parametri del modello dai cambiamenti passo per passo possono quindi risultare distorti, soprattutto quando si misurano solo le posizioni e le velocità reali restano nascoste. Gli autori mostrano che metodi ingenuamente semplici possono stimare in modo sistematico in modo errato grandezze chiave come la rapidità con cui le particelle cambiano direzione o l’intensità dei colpi casuali.
Un modo più intelligente per leggere dati rumorosi
Il cuore dell’articolo è un nuovo modo per approssimare quanto sia probabile un certo insieme di parametri del modello, dato una traiettoria registrata. Invece di fingere che le velocità approssimate tramite differenze finite si comportino come velocità istantanee vere, il metodo tiene conto con cura del fatto che il moto osservato è stato mediato su finestre temporali brevi. Matematicamente, ciò porta a una descrizione in cui queste “velocità secanti” sono guidate da rumore colorato con specifiche correlazioni a breve raggio. Catturando queste correlazioni in una matrice compatta con struttura semplice, gli autori ricavano una formula di verosimiglianza che può essere valutata rapidamente, anche per tracce lunghe con molti punti dati.
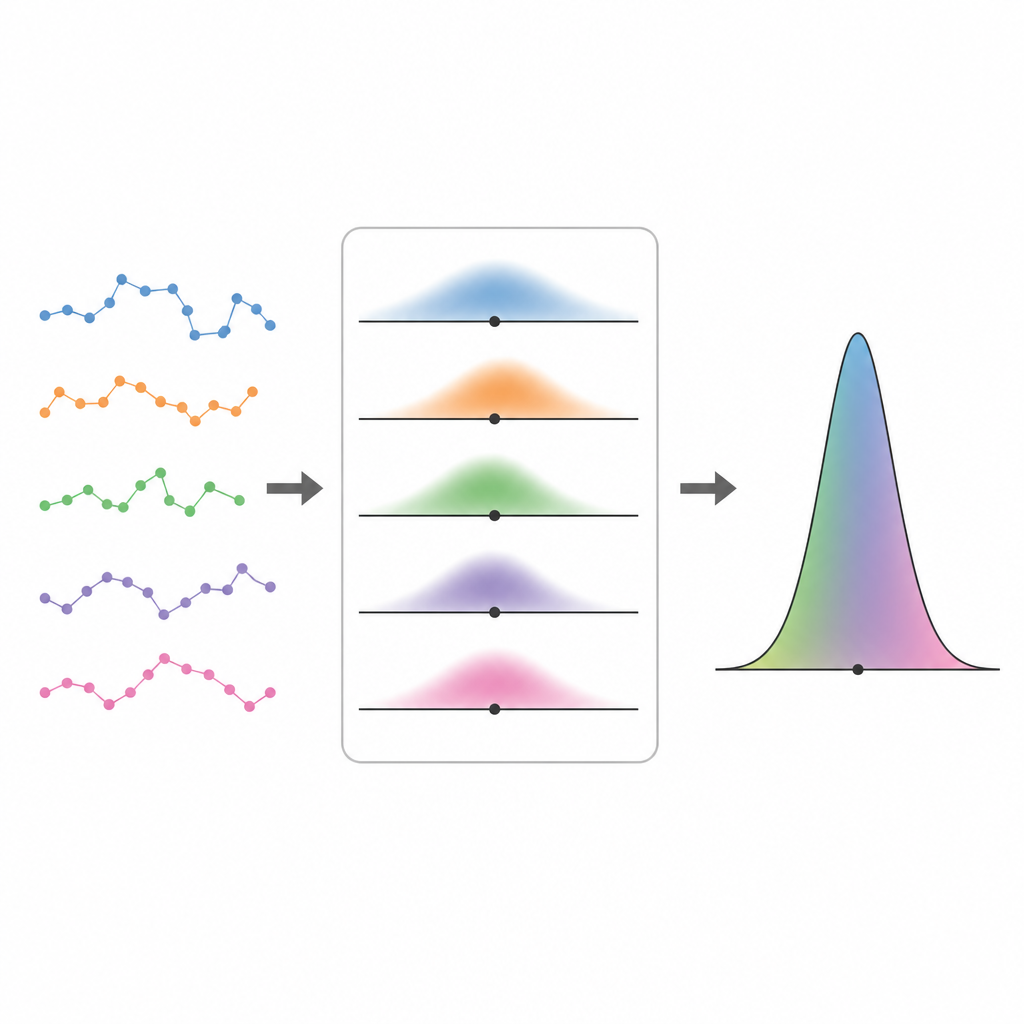
Allargare lo sguardo dagli individui alle popolazioni Figure 2. Traiettorie brevi e rumorose si combinano in un profilo di popolazione più nitido pesando tutti i possibili parametri di moto in base alla loro verosimiglianza.
Una volta che possono esprimere quanto è probabile una singola traccia per un dato insieme di parametri, gli autori fanno un passo avanti e lasciano che quei parametri varino da particella a particella. Trattano l’intera popolazione come estratta da una distribuzione sconosciuta e poi si chiedono quale distribuzione spiega meglio tutte le tracce osservate insieme. Per risolvere questo problema usano uno schema di expectation–maximization, che alterna la stima di quanto siano probabili diversi valori di parametro per ciascuna traiettoria e l’aggiornamento della distribuzione di popolazione complessiva. Questo approccio di “verosimiglianza completa” supera metodi più semplici in due passaggi che prima adattano ogni traccia separatamente e poi stimano una distribuzione da quei valori puntuali, in particolare quando le traiettorie sono corte e l’incertezza su ciascun individuo è elevata.
Sapere quanto siamo sicuri
Oltre a fornire un’immagine di miglior adattamento della variabilità di popolazione, il quadro offre anche un modo per quantificare l’incertezza di quella immagine. Esaminando quanto la verosimiglianza è concentrata attorno al suo massimo, gli autori calcolano una matrice hessiana la cui inversa stima la dispersione attesa dei parametri di popolazione inferiti in esperimenti ripetuti. Questo produce regioni di confidenza che mostrano quanto la distribuzione stimata potrebbe spostarsi a causa dei dati finiti. Test su dati simulati, inclusi modelli di particelle attive con velocità preferite e tendenze rotazionali, mostrano che il metodo recupera in modo affidabile l’eterogeneità imposta al crescere della risoluzione del campionamento e della lunghezza delle traiettorie.
Cosa significa per lo studio del moto vivente
In termini semplici, l’articolo presenta una ricetta per separare due fonti di casualità nei dati di moto: le fluttuazioni casuali di ciascun individuo nel tempo e le differenze reali tra individui in una popolazione. Gestendo correttamente traiettorie brevi e basate solo su posizioni e le velocità nascoste che le generano, il metodo offre una visione più chiara e onesta di quanto sia variegato un gruppo di particelle o cellule in movimento e di quanto possiamo essere sicuri di quella visione. Questo apre la strada a modelli più dettagliati e guidati dai dati di sistemi motili complessi, dalle cellule migranti nei tessuti alle particelle auto-propulsive nei materiali ingegnerizzati.
Citazione: Albrecht, J., Opper, M. & Großmann, R. A Likelihood Approach for Inference of Population Heterogeneity in Particle Ensembles with Second-Order Langevin Dynamics.
Commun Phys9, 165 (2026). https://doi.org/10.1038/s42005-026-02670-z
Parole chiave: materia attiva, motilità cellulare, modellizzazione stocastica, eterogeneità di popolazione, analisi delle traiettorie