Dlaczego drobne ruchy mogą ujawnić wielkie tajemnice
Od wędrujących bakterii po przemieszczające się komórki w naszych ciałach — organizmy rzadko poruszają się dokładnie tak samo. Każda jednostka ma swoje osobliwości, a eksperymenty często rejestrują jedynie krótkie, zaszumione wycinki ich ruchu. W pracy tej pokazano, jak zamienić takie fragmentaryczne ślady w wyraźny obraz rzeczywistej różnorodności populacji, używając narzędzia statystycznego działającego nawet wtedy, gdy ruch wygląda na przypadkowy, a mierzone są tylko pozycje, nie prędkości.
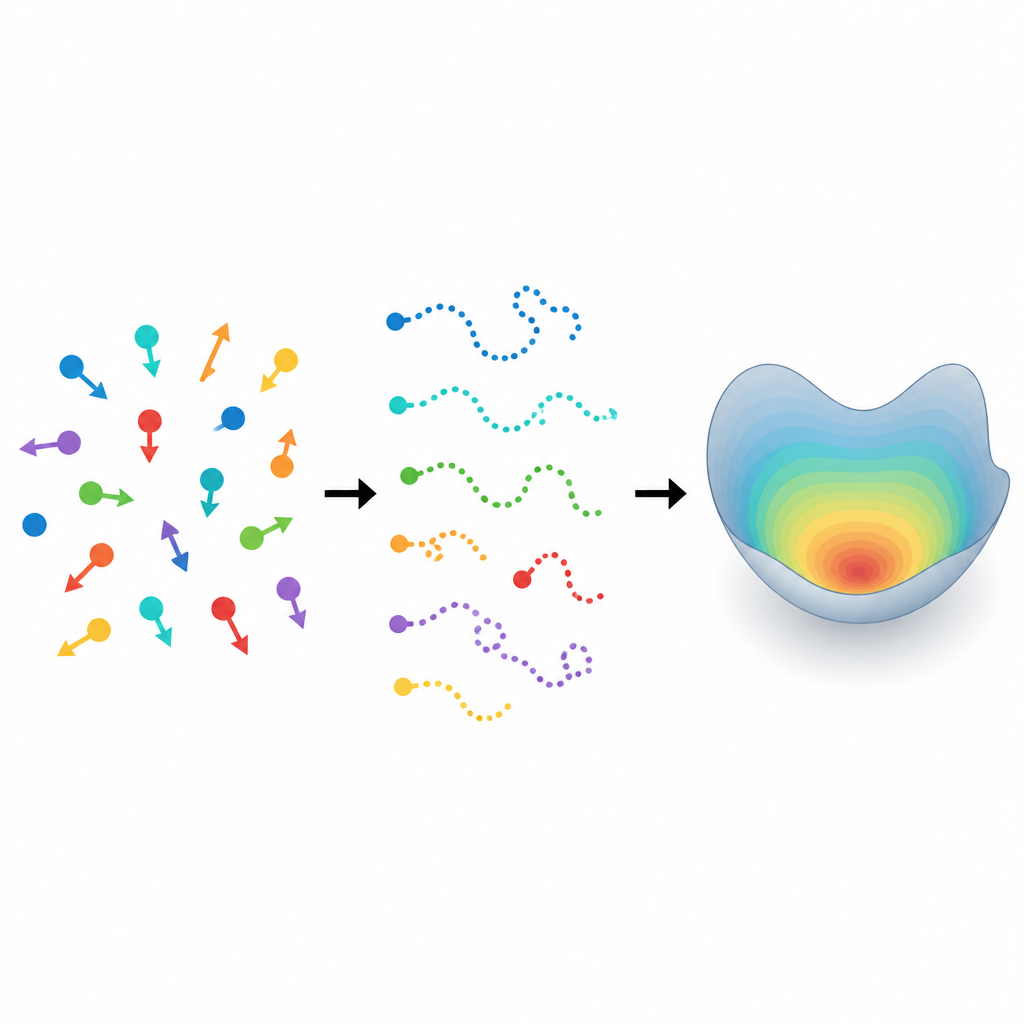
Obserwowanie wielu drobnych podróżników
Współczesne mikroskopy i kamery potrafią śledzić roje komórek, mikroorganizmów czy innych „cząstek aktywnych”, gdy pełzają, pływają lub ślizgają się. W praktyce jednak każdy obiekt może zniknąć z pola widzenia po krótkim czasie, bo opuści obszar obserwacji lub zostanie zasłonięty przez sąsiadów. Zamiast kilku długich nagrań tego samego osobnika, badacze uzyskują wiele krótkich śladów od różnych cząstek. Na to nakłada się fakt, że nawet genetycznie identyczne mikroby czy komórki nie poruszają się identycznie: jedne są bardziej uporczywe, inne bardziej chaotyczne, a jeszcze inne inaczej reagują na otoczenie. Ignorowanie tej indywidualności może prowadzić do mylących wniosków o zachowaniu całej grupy.
Od losowych śladów do ukrytych reguł Figure 1. Wiele różnych poruszających się cząstek daje krótkie ślady, które ujawniają ukryty wzorzec różnorodności ich ruchu.
Aby zrozumieć taki ruch, badacze często opisują go modelami „Langevina”: regułami matematycznymi traktującymi ruch jako kombinację regularnych tendencji i losowych impulsów. W wielu aktywnych układach nie wystarcza jedynie analiza zmian pozycji, ponieważ prędkości bazowe fluktuują w czasie i wprowadzają pamięć do ruchu. To sprawia, że obserwowane pozycje są niemarkowskie, co oznacza, że następny krok zależy od więcej niż tylko kroku bieżącego. Standardowe podejścia szacujące parametry modelu na podstawie zmian między kolejnymi krokami mogą wówczas być obciążone, zwłaszcza gdy mierzone są tylko pozycje, a prawdziwe prędkości pozostają ukryte. Autorzy pokazują, że naiwne metody mogą systematycznie błędnie oszacowywać kluczowe wielkości, takie jak tempo zmiany kierunku ruchu czy intensywność losowych impulsów.
Mądrzejszy sposób czytania zaszumionych danych
Rdzeniem artykułu jest nowe podejście do przybliżania, jak prawdopodobne są dane parametry modelu, biorąc pod uwagę zarejestrowaną trajektorię. Zamiast zakładać, że surowe prędkości obliczone jako skończone różnice zachowują się jak prawdziwe prędkości chwilowe, metoda uwzględnia fakt, że obserwowana wielkość ruchu została wygładzona na krótkich oknach czasowych. W języku matematyki prowadzi to do opisu, w którym te „prędkości siecznych” są napędzane przez barwiony szum o określonych krótkozasięgowych korelacjach. Przechwytując te korelacje w zwartej macierzy o prostej strukturze, autorzy wyprowadzają formułę wiarygodności, którą można szybko ewaluować, nawet dla długich śladów z wieloma punktami danych.
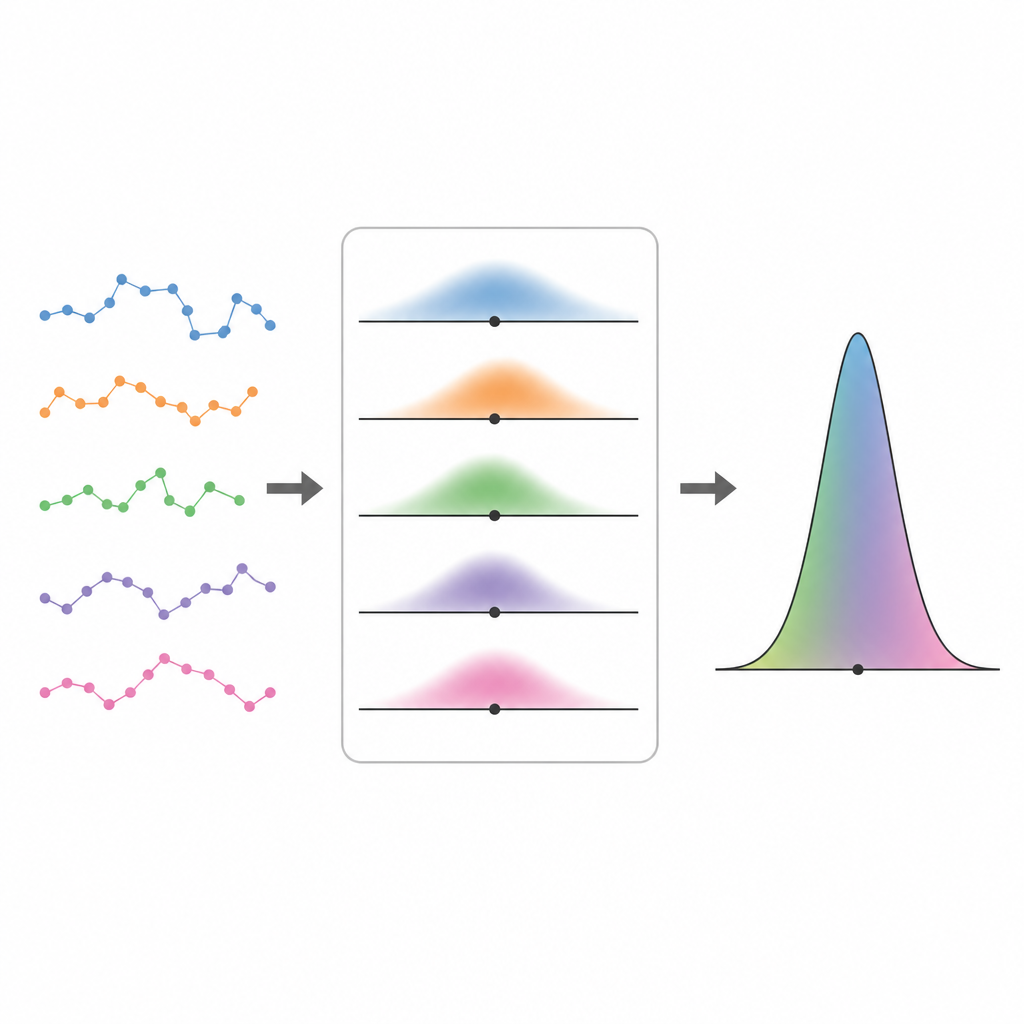
Perspektywa z indywidualnych na populacyjną Figure 2. Krótkie zaszumione trajektorie łączą się w ostrzejszy profil populacji przez ważenie wszystkich możliwych parametrów ruchu ich wiarygodnością.
Gdy można już zapisać, jak prawdopodobny jest pojedynczy ślad dla danego zestawu parametrów, autorzy idą krok dalej i dopuszczają, by te parametry różniły się między cząstkami. Traktują całą populację jako próbę pobraną z nieznanego rozkładu i pytają, który rozkład najlepiej wyjaśnia wszystkie zaobserwowane ślady jednocześnie. Do rozwiązania tego problemu stosują schemat oczekiwanie–maksymalizacja, który naprzemiennie estymuje, jak prawdopodobne są różne wartości parametrów dla każdej trajektorii, i aktualizuje ogólny rozkład populacji. To podejście „pełnej wiarygodności” przewyższa prostsze metody dwuetapowe, które najpierw dopasowują każdy ślad oddzielnie, a potem dopasowują rozkład do tych punktowych oszacowań, zwłaszcza gdy trajektorie są krótkie i niepewność co do każdego osobnika jest duża.
Wiedza o pewności oszacowań
Poza dostarczeniem najlepszego dopasowania zmienności populacji, ramy te oferują również sposób kwantyfikacji niepewności tego obrazu. Badając, jak ostro skoncentrowana jest funkcja wiarygodności wokół maksimum, autorzy obliczają macierz Hessiana, której odwrotność szacuje oczekiwane rozproszenie wywnioskowanych parametrów populacji w powtarzanych eksperymentach. To daje regiony ufności pokazujące, jak bardzo wywnioskowany rozkład mógłby się przesunąć z powodu skończonej ilości danych. Testy na danych symulowanych, w tym na modelach cząstek aktywnych z preferowanymi prędkościami i tendencjami rotacyjnymi, pokazują, że metoda wiarygodnie odzyskuje narzuconą heterogeniczność w miarę dokładniejszego próbkowania i wydłużania trajektorii.
Co to oznacza dla badania ruchu żywych układów
Mówiąc prościej, artykuł przedstawia przepis na rozdzielenie dwóch źródeł losowości w danych ruchu: losowych drgań każdego osobnika w czasie oraz rzeczywistych różnic między osobnikami w populacji. Poprzez właściwe traktowanie krótkich śladów zawierających tylko pozycje i ukrytych za nimi prędkości, metoda daje wyraźniejszy, bardziej uczciwy obraz tego, jak zróżnicowana jest grupa poruszających się cząstek lub komórek i jak pewni możemy być tego obrazu. Toruje to drogę do bardziej szczegółowych, opartych na danych modeli złożonych systemów motylnych, od migrujących komórek w tkankach po samoporuszające się cząstki w materiałach inżynierskich.
Cytowanie: Albrecht, J., Opper, M. & Großmann, R. A Likelihood Approach for Inference of Population Heterogeneity in Particle Ensembles with Second-Order Langevin Dynamics.
Commun Phys9, 165 (2026). https://doi.org/10.1038/s42005-026-02670-z