From roaming bacteria to wandering cells in our bodies, living things rarely move in exactly the same way. Each individual has its own quirks, yet experiments often capture only short, noisy snippets of their motion. This study shows how to turn such fragmented tracks into a clear picture of how diverse a population really is, using a statistical tool that works even when the motion looks random and only positions, not speeds, are recorded.
Watching many tiny travelers
Modern microscopes and cameras can follow swarms of cells, microorganisms, or other “active particles” as they crawl, swim, or glide. But in practice, each cell may vanish from view after a short time because it leaves the field of view or is blocked by neighbors. Instead of a few long movies of the same individual, scientists end up with many short tracks from many different particles. On top of that, even genetically identical microbes or cells do not move identically: some are more persistent, some are more erratic, and some respond differently to their surroundings. Ignoring this individuality can lead to misleading conclusions about how the whole group behaves.
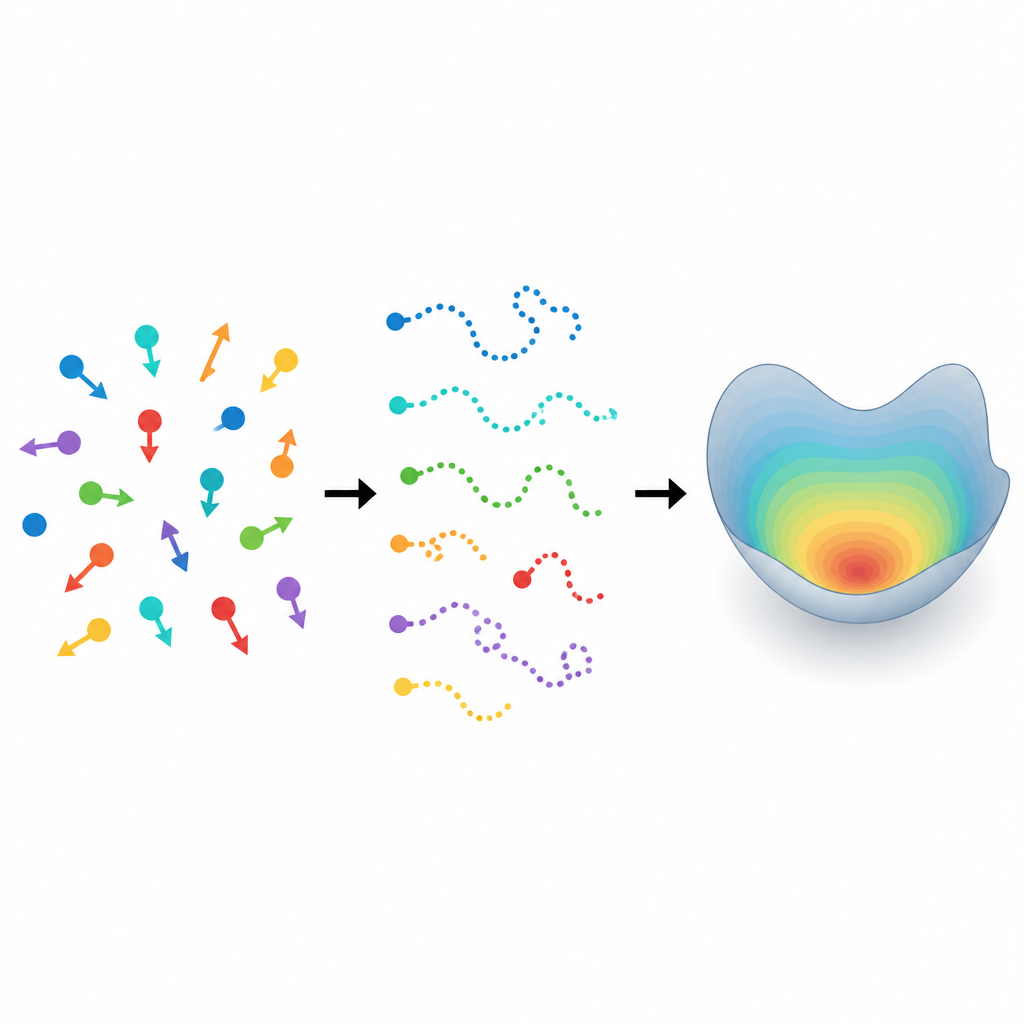
From random tracks to hidden rules Figure 1. Many different moving particles yield short tracks that reveal an underlying pattern of diversity in their motion.
To understand such motion, researchers often describe it with “Langevin” models: mathematical rules that treat movement as a combination of regular trends and random kicks. For many active systems, it is not enough to look at changes in position alone, because the underlying speeds fluctuate in time and introduce memory into the motion. This makes the observed positions non-Markovian, meaning that the next step depends on more than just the current one. Standard approaches that estimate model parameters from step-to-step changes can then become biased, especially when only positions are measured and true velocities remain hidden. The authors show that naive methods can systematically misestimate key quantities such as how quickly particles change direction or how strong the random kicks are.
A smarter way to read noisy data
The core of the paper is a new way to approximate how likely a given set of model parameters is, given a recorded trajectory. Instead of pretending that rough, finite-difference velocities behave like true instantaneous velocities, the method carefully accounts for the fact that observed motion has been smoothed over short time windows. Mathematically, this leads to a description in which these “secant velocities” are driven by colored noise with specific short-range correlations. By capturing these correlations in a compact matrix with a simple structure, the authors derive a likelihood formula that can be evaluated quickly, even for long tracks with many data points.
Zooming out from individuals to populations Figure 2. Short noisy trajectories combine into a sharper population profile by weighting all possible motion parameters by their likelihood.
Once they can write down how likely an individual track is for a given set of parameters, the authors go one step further and let those parameters vary from particle to particle. They treat the whole population as being drawn from an unknown distribution and then ask which distribution best explains all observed tracks at once. To solve this, they use an expectation–maximization scheme, which alternates between estimating how probable different parameter values are for each trajectory and updating the overall population distribution. This “full likelihood” approach outperforms simpler two-step methods that first fit each track separately and then fit a distribution to those point estimates, especially when trajectories are short and uncertainty about each individual is high.
Knowing how sure we are
Beyond providing a best-fit picture of population variability, the framework also offers a way to quantify how uncertain that picture is. By examining how sharply peaked the likelihood is around its maximum, the authors compute a Hessian matrix whose inverse estimates the expected spread of the inferred population parameters across repeated experiments. This yields confidence regions that show how much the inferred distribution could shift due to finite data. Tests on simulated data, including models of active particles with preferred speeds and rotational tendencies, show that the method reliably recovers the imposed heterogeneity as sampling becomes finer and trajectories longer.
What this means for studying living motion
In simple terms, the article presents a recipe for teasing apart two sources of randomness in motion data: the random jitters of each individual over time and the genuine differences between individuals in a population. By properly handling short, position-only tracks and the hidden velocities behind them, the method gives a clearer, more honest view of how diverse a group of moving particles or cells really is, and how confident we can be in that view. This paves the way for more detailed, data-driven models of complex motile systems, from migrating cells in tissues to self-propelled particles in engineered materials.
Citation: Albrecht, J., Opper, M. & Großmann, R. A Likelihood Approach for Inference of Population Heterogeneity in Particle Ensembles with Second-Order Langevin Dynamics.
Commun Phys9, 165 (2026). https://doi.org/10.1038/s42005-026-02670-z
Keywords: active matter, cell motility, stochastic modeling, population heterogeneity, trajectory analysis