Waarom kleine bewegingen grote geheimen kunnen onthullen
Van rondzwervende bacteriën tot trekkende cellen in ons lichaam: levende organismen bewegen zelden exact hetzelfde. Elk individu heeft zijn eigen eigenaardigheden, maar experimenten leggen vaak slechts korte, lawaaierige fragmenten van hun beweging vast. Deze studie laat zien hoe zulke gefragmenteerde sporen kunnen worden omgezet in een duidelijk beeld van hoe divers een populatie werkelijk is, met een statistisch hulpmiddel dat werkt zelfs wanneer de beweging willekeurig lijkt en alleen posities, niet snelheden, worden gemeten.
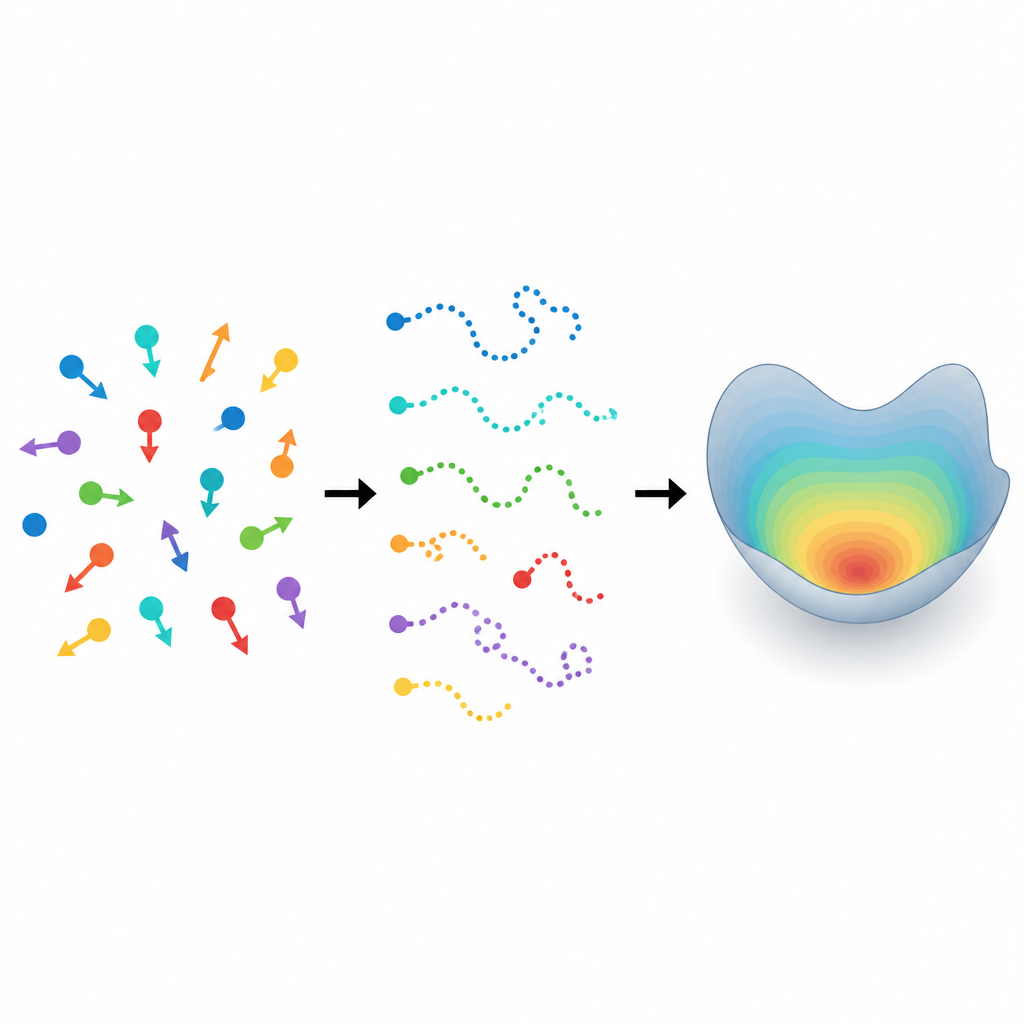
Vele kleine reizigers bekijken
Moderne microscopen en camera’s kunnen zwermen cellen, micro-organismen of andere “actieve deeltjes” volgen terwijl ze kruipen, zwemmen of glijden. In de praktijk verdwijnt elk deeltje echter vaak na korte tijd uit beeld omdat het het gezichtsveld verlaat of door buren wordt geblokkeerd. In plaats van een paar lange films van hetzelfde individu krijgen onderzoekers veel korte sporen van veel verschillende deeltjes. Bovendien bewegen zelfs genetisch identieke microben of cellen niet identiek: sommige zijn volhardender, sommige zijn grilliger en sommige reageren anders op hun omgeving. Het negeren van deze individualiteit kan leiden tot misleidende conclusies over het gedrag van de hele groep.
Van willekeurige sporen naar verborgen regels Figure 1. Veel verschillende bewegende deeltjes leveren korte sporen die een onderliggend patroon van diversiteit in hun beweging onthullen.
Om zulke bewegingen te begrijpen beschrijven onderzoekers ze vaak met “Langevin”-modellen: wiskundige regels die beweging behandelen als een combinatie van regelmatige trends en willekeurige stoten. Voor veel actieve systemen is het niet voldoende alleen naar positievariaties te kijken, omdat de onderliggende snelheden in de tijd fluctueren en geheugen in de beweging brengen. Dit maakt de waargenomen posities niet-Markoviaans, wat betekent dat de volgende stap afhangt van meer dan alleen de huidige. Standaardbenaderingen die modelparameters schatten uit stap-voor-stap veranderingen kunnen daardoor bevooroordeeld raken, vooral wanneer alleen posities worden gemeten en ware snelheden verborgen blijven. De auteurs tonen aan dat naïeve methoden systematisch belangrijke grootheden kunnen onderschatten of overschatten, zoals hoe snel deeltjes van richting veranderen of hoe sterk de willekeurige stoten zijn.
Een slimmer manier om lawaaierige data te lezen
De kern van het artikel is een nieuwe manier om te benaderen hoe waarschijnlijk een gegeven set modelparameters is, gegeven een opgenomen traject. In plaats van te doen alsof ruwe, eindige-differentie-snelheden zich gedragen als echte instantane snelheden, houdt de methode zorgvuldig rekening met het feit dat waargenomen beweging over korte tijdsvensters is gladgestreken. Wiskundig leidt dit tot een beschrijving waarin deze “secant-snelheden” worden aangedreven door gekleurd ruis met specifieke kortbereik-correlationes. Door deze correlaties vast te leggen in een compacte matrix met een eenvoudige structuur, leiden de auteurs een likelihood-formule af die snel geëvalueerd kan worden, zelfs voor lange sporen met veel datapunten.
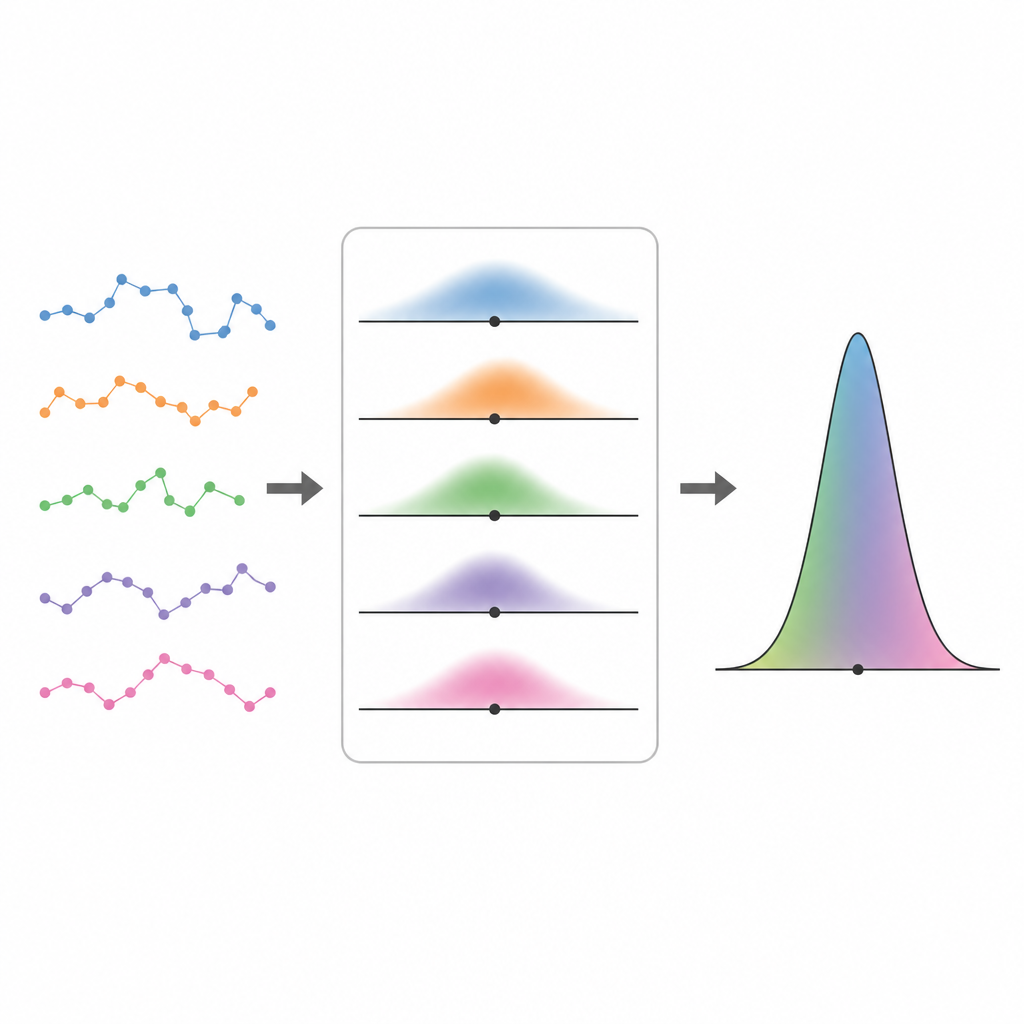
Uitzoomen van individuen naar populaties Figure 2. Korte, lawaaierige trajecten combineren tot een scherper populatieprofiel door alle mogelijke bewegingsparameters te wegen met hun likelihood.
Zodra ze kunnen opschrijven hoe waarschijnlijk een individueel spoor is voor een gegeven set parameters, gaan de auteurs een stap verder en laten die parameters variëren van deeltje tot deeltje. Ze behandelen de hele populatie als getrokken uit een onbekende verdeling en vragen vervolgens welke verdeling het beste alle waargenomen sporen tegelijk verklaart. Om dit op te lossen gebruiken ze een expectation–maximization-schema, dat afwisselt tussen het inschatten hoe waarschijnlijk verschillende parametervarianten zijn voor elk traject en het bijwerken van de algemene populatieverdeling. Deze “volledige likelihood”-aanpak overtreft eenvoudigere twee-staps methoden die eerst elk spoor afzonderlijk fitten en daarna een verdeling op die punt-schattingen passen, vooral wanneer trajecten kort zijn en de onzekerheid per individu groot is.
Buiten het leveren van een best-fit beeld van populatievariabiliteit biedt het raamwerk ook een manier om te kwantificeren hoe onzeker dat beeld is. Door te onderzoeken hoe scherp de likelihood rond haar maximum piekt, berekenen de auteurs een Hessiaanse matrix waarvan de inverse de verwachte spreiding van de afgeleide populatieparameters over herhaalde experimenten schat. Dit levert betrouwbaarheidsregio’s op die laten zien hoeveel de afgeleide verdeling kan verschuiven door beperkte data. Tests op gesimuleerde gegevens, inclusief modellen van actieve deeltjes met voorkeursnelheden en rotatietendensen, tonen dat de methode de opgelegde heterogeniteit betrouwbaar terugwint naarmate de bemonstering fijner wordt en de trajecten langer.
Wat dit betekent voor het bestuderen van levende beweging
Eenvoudig gezegd presenteert het artikel een recept om twee bronnen van willekeur in bewegingsdata uit elkaar te halen: de willekeurige trilling van elk individu in de tijd en de echte verschillen tussen individuen in een populatie. Door correct om te gaan met korte, alleen-positie sporen en de verborgen snelheden daarachter, geeft de methode een helderder, eerlijker beeld van hoe divers een groep bewegende deeltjes of cellen werkelijk is, en hoe zeker we kunnen zijn over dat beeld. Dit effent de weg voor meer gedetailleerde, datagedreven modellen van complexe motiele systemen, van migrerende cellen in weefsels tot zelfaangedreven deeltjes in ontworpen materialen.
Bronvermelding: Albrecht, J., Opper, M. & Großmann, R. A Likelihood Approach for Inference of Population Heterogeneity in Particle Ensembles with Second-Order Langevin Dynamics.
Commun Phys9, 165 (2026). https://doi.org/10.1038/s42005-026-02670-z