Clear Sky Science · ru
Федеративное обучение с переговорами для бесконфликтного планирования потоков между периферией и облаком
Почему умным приложениям нужна более гладкая внутренняя «дорожная сеть»
От карт с пробками в реальном времени до заводских датчиков — многие современные приложения зависят от непрерывного потока данных, которые нужно обрабатывать за миллисекунды. Чтобы справляться с нагрузкой, компании распределяют вычисления между близкими устройствами периферии и удалёнными облачными серверами. Но когда множество компонентов сети принимают решения одновременно, они могут конфликтовать, вызывая цифровые пробки, рост затрат и замедление откликов. В этой работе рассматривается новый способ координации таких решений, чтобы потоковые приложения оставались быстрыми, стабильными и эффективными даже при резко меняющемся спросе. 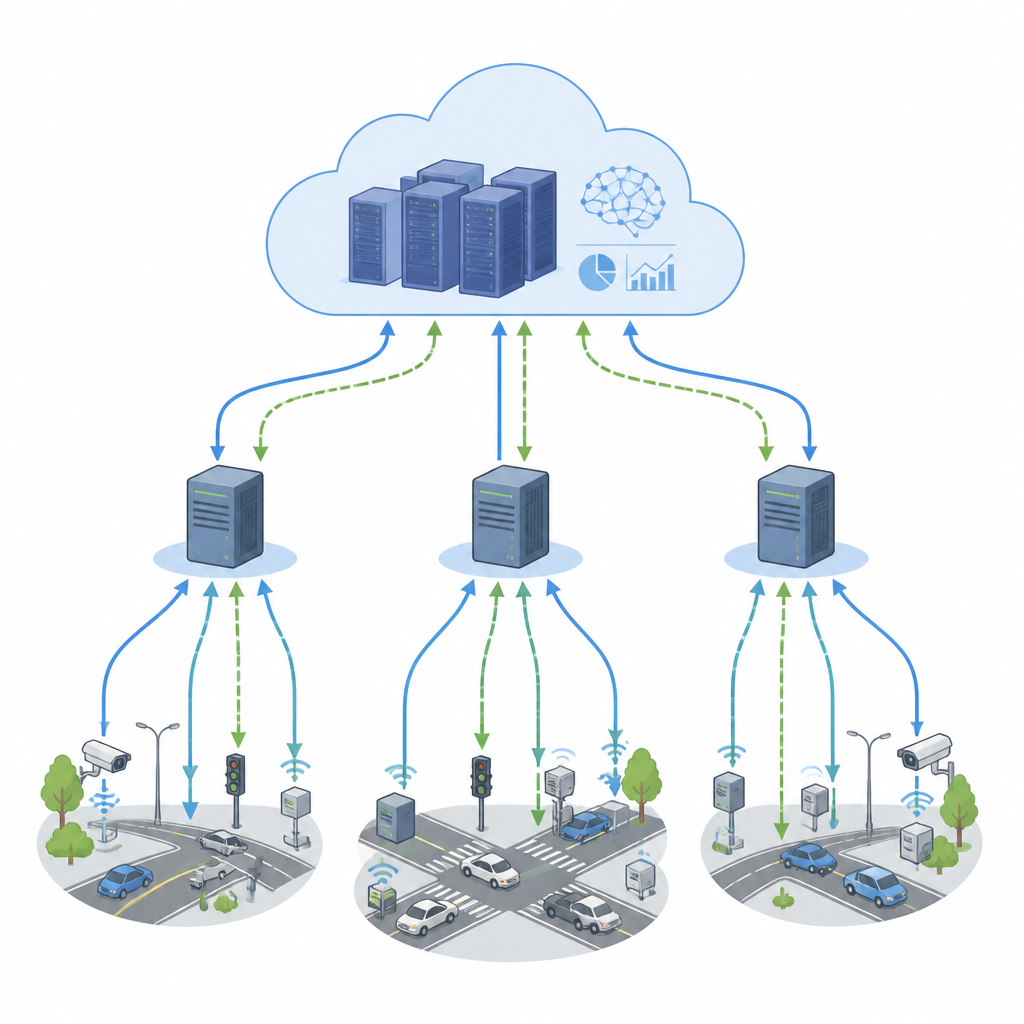
Трудности совместной работы периферии и облака
Умные камеры, автомобили и промышленные датчики теперь генерируют непрекращающиеся потоки данных, требующие анализа в реальном времени. Компьютеры на периферии, расположенные близко к пользователям, сокращают задержку, а облачные центры придают дополнительную мощность. Тем не менее решение о том, где выполнять каждую задачу, сложно, поскольку задачи взаимозависимы, а нагрузка может резко возрастать без предупреждения. Классические методы планирования опираются на фиксированные правила или офлайн‑планы. Они работают в более спокойных условиях, но испытывают трудности, когда тысячи задач и машин должны адаптироваться каждую секунду в разных регионах. Централизованный контроль может стать узким местом, тогда как полностью независимые локальные контроллеры часто конфликтуют из‑за общих ресурсов.
Учиться планировать, но не наступать друг другу на ноги
Недавние подходы позволяют программным агентам методом проб и ошибок вырабатывать хорошие правила планирования — это называется обучением с подкреплением. Федеративное обучение даёт возможность множеству агентов тренироваться совместно, сохраняя при этом исходные данные локально, что важно для приватности и пропускной способности. Однако когда каждый кластер периферийных машин учится сам по себе и лишь изредка синхронизирует модели, их действия всё ещё могут конфликтовать. Два кластера могут одновременно выгружать задачи в одни и те же облачные серверы или перекладывать задачи туда‑обратно, создавая дополнительные задержки и трату энергии. Авторы утверждают, что не хватает явного механизма, позволяющего этим агентам общаться и договариваться прежде, чем действовать.
Стол переговоров для цифровых планировщиков
Предложенная архитектура FedNeg-RL добавляет лёгкий слой переговоров поверх федеративного обучения с подкреплением. Каждый кластер периферийных устройств представлен агентом, который следит за локальной загрузкой, прогнозирует ближайший трафик и отмечает, какие задачи особенно чувствительны к задержкам. Перед внесением изменений, которые могут повлиять на общие каналы связи или облачные узлы, эти представители обмениваются краткими сводками — например, ожидаемой нагрузкой и вероятной оценкой воздействия их действий — вместо передачи сырых данных. С помощью простых протоколов в стиле аргументации они согласовывают совместный план, избегающий конфликтов, после чего каждый кластер применяет согласованное действие локально. Со временем процесс обучения формируется так, чтобы отдавать предпочтение планам, сохраняющим низкую задержку, разумный расход энергии и затрат, а также минимизирующим конфликты. 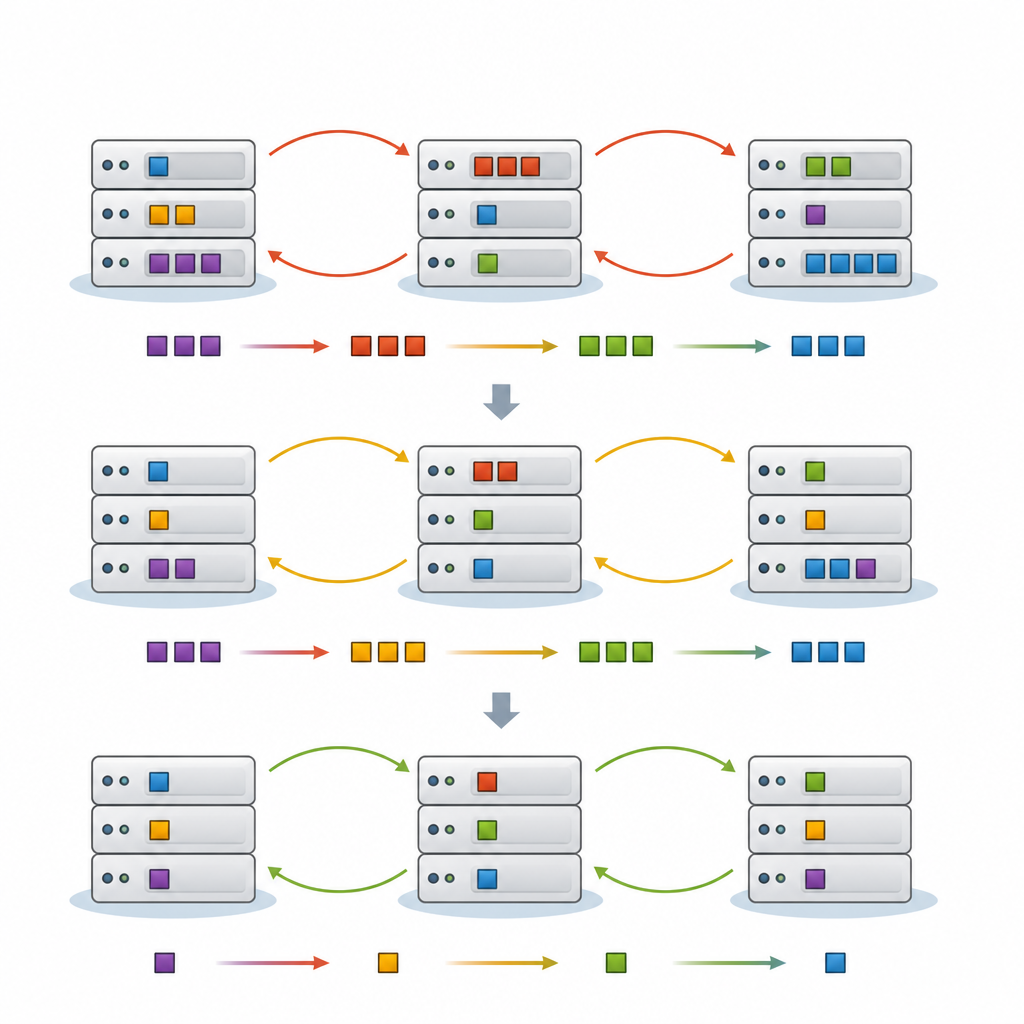
Тестирование метода в загруженных виртуальных городах
Для оценки FedNeg-RL авторы создали подробные симуляции нагрузок в стиле Интернета вещей, включающие сотни взаимосвязанных задач и взрывоподобные, трудно прогнозируемые потоки данных, похожие на те, что встречаются в системах мониторинга городского трафика. Они сравнили свой метод с планировщиками на основе правил, эволюционными алгоритмами, стандартным локальным обучением с подкреплением, чистым федеративным обучением и единым централизованным агентом обучения. В различных сценариях FedNeg-RL сократила число разрушительных реконфигураций, вызванных конфликтами, до 41%, уменьшила верхние значения задержки (самые медленные 10% откликов) примерно на 20–28% и снизила накладные расходы на адаптацию примерно на 35%. Кроме того, модель использовала энергию более равномерно и хорошо масштабировалась при увеличении числа задач и машин.
Что это значит для будущих связанных систем
Проще говоря, FedNeg-RL демонстрирует, что обучение программных контроллеров не только на собственном опыте, но и с возможностью переговоров с коллегами может сделать совместную инфраструктуру периферии и облака более плавной в работе. Вместо разрозненных конкурирующих решений кластеры координируются в меру необходимости, чтобы потоковые приложения оставались отзывчивыми, стабильными и эффективными, не раскрывая приватных данных и не полагаясь на единый центральный мозг. По мере того как реальные развертывания становятся больше и сложнее, такое обучение с учётом переговоров может помочь обеспечить тихую, надёжную работу невидимой вычислительной инфраструктуры умных городов, заводов и сервисов, даже при постоянно меняющемся спросе.
Цитирование: Kang, X., Hua, C. Negotiation-augmented federated reinforcement learning for conflict-free edge–cloud stream scheduling. Sci Rep 16, 15158 (2026). https://doi.org/10.1038/s41598-026-45004-3
Ключевые слова: планирование edge–cloud, федеративное обучение с подкреплением, потоковые IoT, многоагентные переговоры, снижение задержки