Clear Sky Science · fr
Apprentissage par renforcement fédéré augmenté par la négociation pour l’ordonnancement sans conflit des flux Edge–Cloud
Pourquoi les applications intelligentes ont besoin d’un trafic plus fluide en coulisses
Des cartes de trafic en direct aux capteurs d’usine, de nombreuses applications modernes dépendent d’un flux constant de données qui doit être traité en millisecondes. Pour suivre le rythme, les entreprises répartissent les calculs entre des dispositifs edge proches et des serveurs cloud distants. Mais lorsque de nombreuses parties de ce réseau prennent leurs propres décisions simultanément, des frictions peuvent apparaître, provoquant des embouteillages numériques, une hausse des coûts et des réponses lentes. Cet article explore une nouvelle façon de coordonner ces décisions pour que les applications de streaming restent rapides, stables et efficaces même face à des demandes en forte variation. 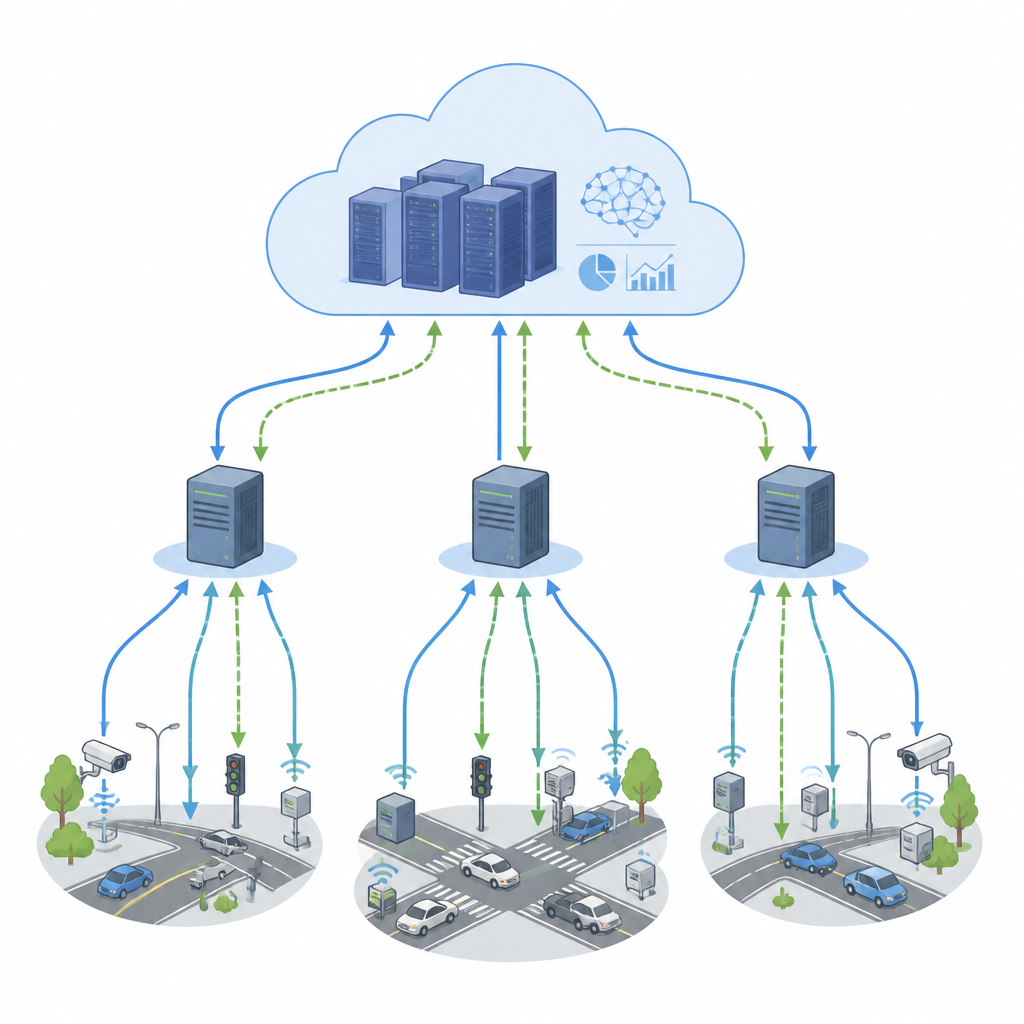
Les douleurs de croissance de la coopération edge–cloud
Les caméras intelligentes, véhicules et capteurs industriels envoient désormais des flux de données incessants qui doivent être analysés en temps réel. Les ordinateurs edge proches des utilisateurs réduisent la latence, tandis que les centres de données cloud apportent une puissance supplémentaire. Pourtant, décider où exécuter chaque travail est délicat, car les tâches dépendent les unes des autres et les charges peuvent exploser sans prévenir. Les méthodes classiques d’ordonnancement reposent sur des règles fixes ou une planification hors ligne. Elles fonctionnent dans des contextes plus calmes mais peinent lorsque des milliers de tâches et de machines doivent s’adapter chaque seconde à travers plusieurs régions. Un contrôle purement centralisé peut devenir un goulot d’étranglement, tandis que des contrôleurs locaux totalement indépendants se disputent souvent des ressources partagées.
Apprendre à ordonnancer, mais sans marcher sur les pieds des autres
Des approches récentes laissent des agents logiciels apprendre de bonnes règles d’ordonnancement par essai‑erreur, une technique appelée apprentissage par renforcement. L’apprentissage fédéré permet à de nombreux agents de s’entraîner ensemble tout en conservant leurs données brutes localement, ce qui est important pour la confidentialité et la bande passante. Cependant, lorsque chaque grappe d’edge apprend seule et ne synchronise ses modèles qu’occasionnellement, leurs actions peuvent encore entrer en conflit. Deux grappes peuvent déléguer vers les mêmes serveurs cloud en même temps, ou renvoyer des tâches d’un côté à l’autre, créant des retards supplémentaires et un gaspillage d’énergie. Les auteurs soutiennent qu’il manque un moyen explicite pour ces agents de se parler et de négocier avant d’agir.
Une table de négociation pour les ordonnanceurs numériques
Le cadre proposé, FedNeg-RL, ajoute une couche de négociation légère au‑dessus de l’apprentissage par renforcement fédéré. Chaque grappe de dispositifs edge dispose d’un agent représentant qui surveille la charge locale, prédit le trafic à court terme et identifie les tâches les plus sensibles à la latence. Avant d’appliquer des changements susceptibles d’affecter des liens partagés ou des nœuds cloud, ces représentants échangent de brefs résumés, tels que la charge attendue et l’impact probable de leurs mouvements, plutôt que des données brutes. En utilisant des protocoles simples de type argumentatif, ils négocient un plan commun qui évite les conflits, puis chaque grappe applique localement l’action convenue. Au fil du temps, leur processus d’apprentissage est orienté pour favoriser les plans qui maintiennent une faible latence, des consommations d’énergie et des coûts raisonnables, et des conflits rares. 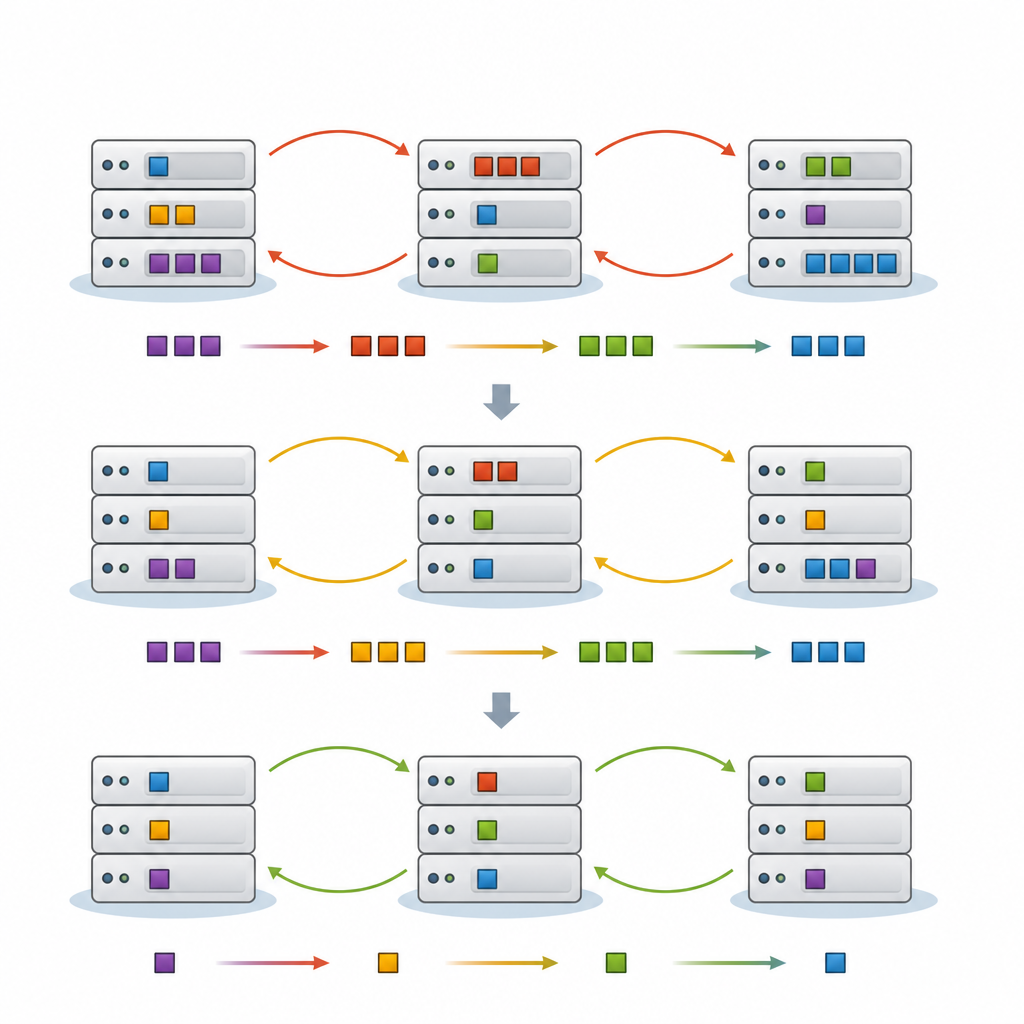
Tester l’approche dans des villes virtuelles très sollicitées
Pour évaluer FedNeg-RL, les auteurs ont construit des simulations détaillées de charges de travail de type Internet des objets, incluant des centaines de tâches interconnectées et des flux de données rafales difficiles à prévoir, similaires à ceux observés dans la surveillance du trafic des villes intelligentes. Ils ont comparé leur méthode à des ordonnanceurs basés sur des règles, des algorithmes évolutifs, l’apprentissage par renforcement local standard, l’apprentissage fédéré pur, et un agent d’apprentissage centralisé unique. Dans de nombreux scénarios, FedNeg-RL a réduit le nombre de reconfigurations perturbatrices déclenchées par des conflits jusqu’à 41 %, diminué la latence des pires réponses (les 10 % les plus lentes) d’environ 20 à 28 %, et abaissé le surcoût d’adaptation d’environ 35 %. Il a également utilisé l’énergie de manière plus homogène et a bien monté en charge au fur et à mesure de l’augmentation du nombre de tâches et de machines.
Ce que cela signifie pour les systèmes connectés de demain
En termes simples, FedNeg-RL montre que former des contrôleurs logiciels non seulement à apprendre de l’expérience mais aussi à négocier avec leurs pairs peut rendre l’infrastructure partagée edge–cloud plus fluide. Plutôt que des décisions éparpillées et concurrentes, les grappes se coordonnent juste ce qu’il faut pour maintenir les applications de streaming réactives, stables et efficaces, sans révéler de données privées ni dépendre d’un cerveau central unique. À mesure que les déploiements réels deviennent plus vastes et complexes, un apprentissage conscient de la négociation pourrait aider à garantir que le tissu informatique invisible derrière les villes, usines et services intelligents continue de fonctionner discrètement en arrière‑plan, même lorsque les demandes évoluent constamment.
Citation: Kang, X., Hua, C. Negotiation-augmented federated reinforcement learning for conflict-free edge–cloud stream scheduling. Sci Rep 16, 15158 (2026). https://doi.org/10.1038/s41598-026-45004-3
Mots-clés: ordonnancement edge cloud, apprentissage par renforcement fédéré, streaming IoT, négociation multi‑agents, réduction de la latence