Clear Sky Science · de
Verhandlungs-unterstütztes föderiertes Reinforcement Learning für konfliktfreie Edge–Cloud-Stream-Planung
Warum smarte Apps eine reibungslosere Vernetzung im Hintergrund brauchen
Von Live-Verkehrskarten bis zu Fabriksensoren: Viele moderne Anwendungen hängen von einem ständigen Datenstrom ab, der in Millisekunden verarbeitet werden muss. Um Schritt zu halten, verteilen Unternehmen Rechenaufgaben auf nahe Edge-Geräte und entfernte Cloud-Server. Wenn jedoch viele Teile dieses Netzwerks gleichzeitig eigene Entscheidungen treffen, können sie miteinander kollidieren, digitale Staus verursachen, Kosten in die Höhe treiben und Reaktionszeiten verlängern. Dieses Paper untersucht einen neuen Weg, diese Entscheidungen zu koordinieren, damit Streaming-Apps auch bei stark schwankender Nachfrage schnell, stabil und effizient bleiben. 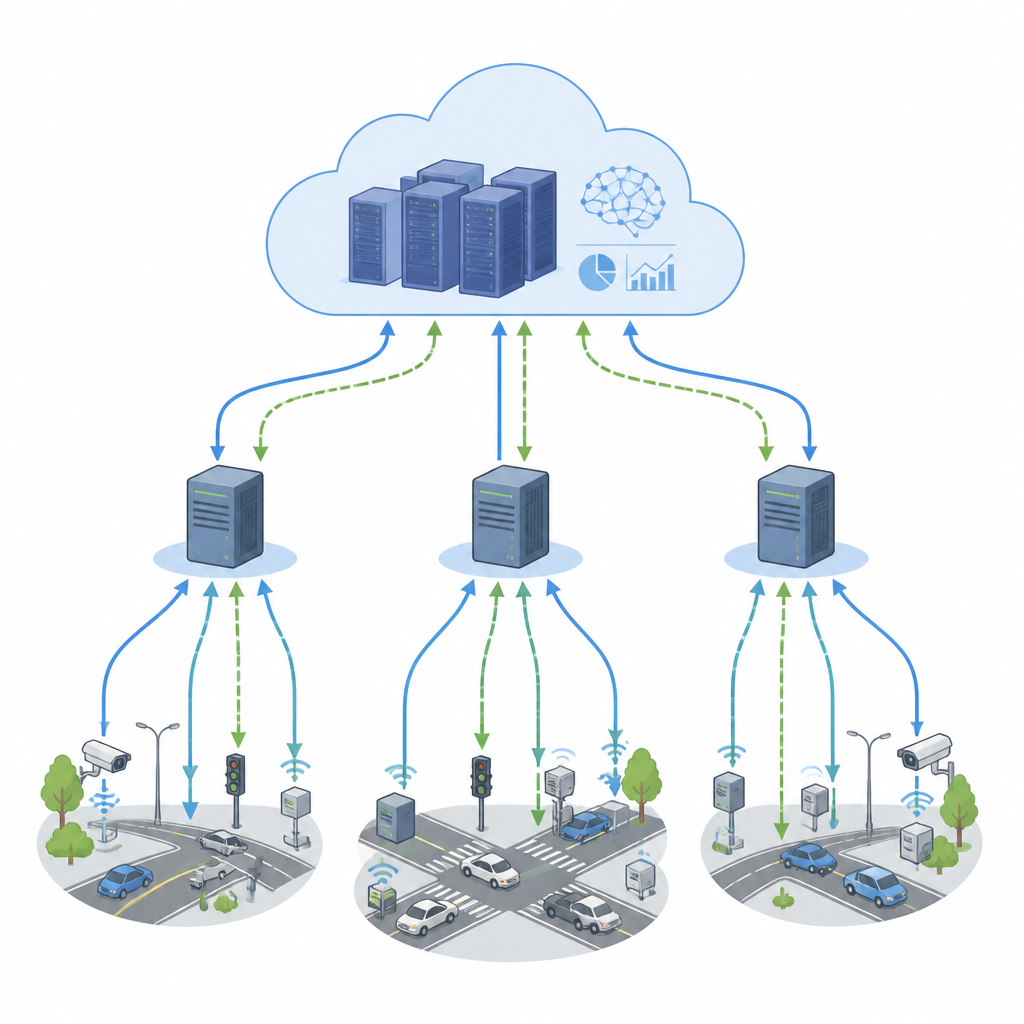
Wachstumsschmerzen bei der Zusammenarbeit von Edge und Cloud
Smarte Kameras, Fahrzeuge und Industriesensoren liefern heute endlose Datenströme, die in Echtzeit analysiert werden müssen. Edge-Computer in der Nähe der Nutzer reduzieren Verzögerungen, während Cloud-Rechenzentren zusätzliche Kapazität bereitstellen. Die Entscheidung, wo einzelne Arbeitsaufgaben ausgeführt werden sollen, ist jedoch knifflig, weil Aufgaben voneinander abhängen und Lastspitzen unvermittelt auftreten. Klassische Planungsmethoden basieren auf festen Regeln oder Offline-Planung. Sie funktionieren in ruhigeren Umgebungen, haben aber Schwierigkeiten, wenn tausende Aufgaben und Rechner sich jede Sekunde über mehrere Regionen hinweg anpassen müssen. Vollständig zentralisierte Steuerung kann zum Engpass werden, während völlig unabhängige lokale Controller oft um gemeinsame Ressourcen konkurrieren.
Lernen zu planen, aber ohne anderen auf die Füße zu treten
Jüngste Ansätze erlauben es Softwareagenten, durch Versuch und Irrtum gute Planungsstrategien zu erlernen – eine Technik namens Reinforcement Learning. Föderiertes Lernen ermöglicht vielen Agenten gemeinsames Training bei gleichzeitiger Lokalverarbeitung ihrer Rohdaten, was für Datenschutz und Bandbreite wichtig ist. Wenn jedoch jeder Cluster von Edge-Geräten separat lernt und Modelle nur gelegentlich synchronisiert werden, können ihre Aktionen weiterhin in Konflikt geraten. Zwei Cluster könnten gleichzeitig an dieselben Cloud-Server auslagern oder Aufgaben hin- und herschieben, was zusätzliche Verzögerung und Energieverschwendung verursacht. Die Autorinnen und Autoren argumentieren, dass eine explizite Möglichkeit für diese Agenten, miteinander zu kommunizieren und vor Aktionen zu verhandeln, fehlt.
Ein Verhandlungstisch für digitale Scheduler
Das vorgeschlagene Framework FedNeg-RL ergänzt föderiertes Reinforcement Learning um eine leichte Verhandlungsschicht. Jeder Edge-Cluster hat einen repräsentativen Agenten, der die lokale Last überwacht, den kurzzeitigen Datenverkehr vorhersagt und verfolgt, welche Aufgaben besonders empfindlich gegenüber Verzögerungen sind. Bevor Änderungen vorgenommen werden, die gemeinsame Leitungen oder Cloud-Knoten betreffen könnten, tauschen diese Vertreter kurze Zusammenfassungen aus, etwa erwartete Lasten und die wahrscheinlichen Auswirkungen ihrer Maßnahmen, statt Rohdaten zu teilen. Mit einfachen argumentbasierten Protokollen verhandeln sie einen gemeinsamen Plan, der Kollisionen vermeidet, und jeder Cluster führt die vereinbarte Aktion lokal aus. Im Laufe der Zeit wird ihr Lernprozess so geprägt, dass Pläne bevorzugt werden, die Latenz niedrig, Energie- und Kostenaufwand angemessen und Konflikte selten halten. 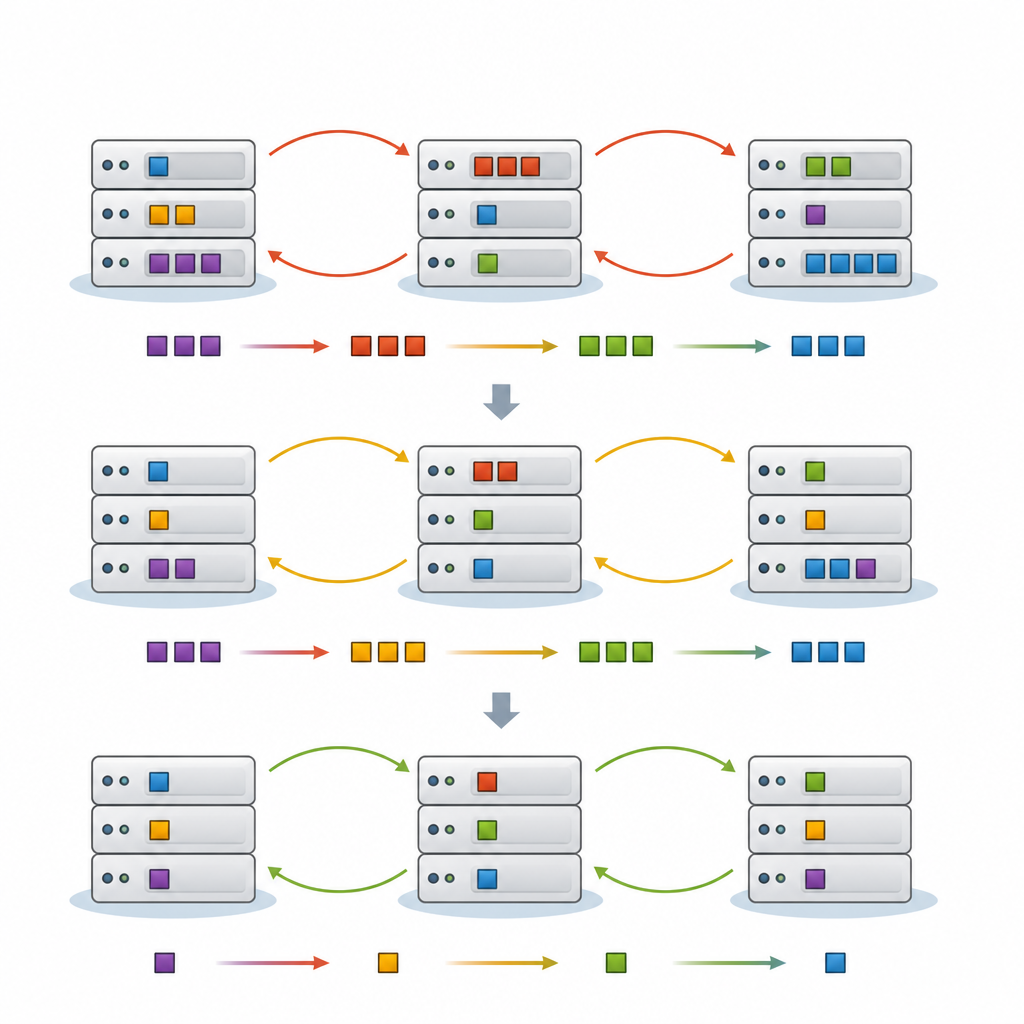
Test des Ansatzes in belebten virtuellen Städten
Zur Bewertung von FedNeg-RL bauten die Autorinnen und Autoren detaillierte Simulationen von IoT-ähnlichen Workloads auf, inklusive hunderter vernetzter Aufgaben und sprunghafter, schwer vorhersagbarer Datenströme, wie sie etwa in der Verkehrsüberwachung intelligenter Städte vorkommen. Sie verglichen ihre Methode mit regelbasierten Scheduler, evolutionären Algorithmen, standardmäßigem lokalem Reinforcement Learning, reinem föderierten Lernen und einem einzigen zentralen Lernagenten. In vielen Szenarien verringerte FedNeg-RL die Anzahl störender Neukonfigurationen durch Konflikte um bis zu 41 Prozent, reduzierte die hohe Latenz (die langsamsten 10 Prozent der Antworten) um etwa 20 bis 28 Prozent und senkte den Anpassungsaufwand um ungefähr 35 Prozent. Außerdem nutzte es Energie gleichmäßiger und skalierte gut mit steigender Zahl an Aufgaben und Rechnern.
Was das für zukünftige vernetzte Systeme bedeutet
Einfach gesagt zeigt FedNeg-RL, dass Softwaresteuerungen, die nicht nur aus Erfahrung lernen, sondern auch mit ihren Peers verhandeln, die gemeinsam genutzte Edge- und Cloud-Infrastruktur reibungsloser betreiben können. Statt verstreuter, konkurrierender Entscheidungen koordinieren sich Cluster gerade genug, um Streaming-Anwendungen reaktiv, stabil und effizient zu halten, ohne private Daten offenzulegen oder auf ein einzelnes zentrales System angewiesen zu sein. Mit wachsender Größe und Komplexität realer Deployments könnte solch verhandlungsbewusstes Lernen dazu beitragen, dass der unsichtbare Rechenstoff hinter Smart Cities, Fabriken und Diensten auch bei ständig wechselnden Anforderungen leise und zuverlässig weiterarbeitet.
Zitation: Kang, X., Hua, C. Negotiation-augmented federated reinforcement learning for conflict-free edge–cloud stream scheduling. Sci Rep 16, 15158 (2026). https://doi.org/10.1038/s41598-026-45004-3
Schlüsselwörter: Edge-Cloud-Planung, föderiertes Reinforcement Learning, IoT-Streaming, Multiagenten-Verhandlung, Latenzreduzierung