Clear Sky Science · nl
Onderhandelingsversterkte gefedereerde reinforcement learning voor conflictvrije edge–cloud streamplanning
Waarom slimme apps vloeiendere verkeersafhandeling achter de schermen nodig hebben
Van live verkeerskaarten tot fabriekssensoren: veel moderne apps vertrouwen op een constante stroom data die binnen milliseconden verwerkt moet worden. Om bij te blijven verspreiden bedrijven berekeningen over nabijgelegen edge-apparaten en verre cloudservers. Maar wanneer veel onderdelen van dit netwerk tegelijk hun eigen keuzes maken, kunnen ze in conflict komen, wat digitale files, stijgende kosten en trage reacties veroorzaakt. Dit artikel onderzoekt een nieuwe manier om die beslissingen te coördineren, zodat streaming-apps snel, stabiel en efficiënt blijven, zelfs bij sterk veranderende vraag. 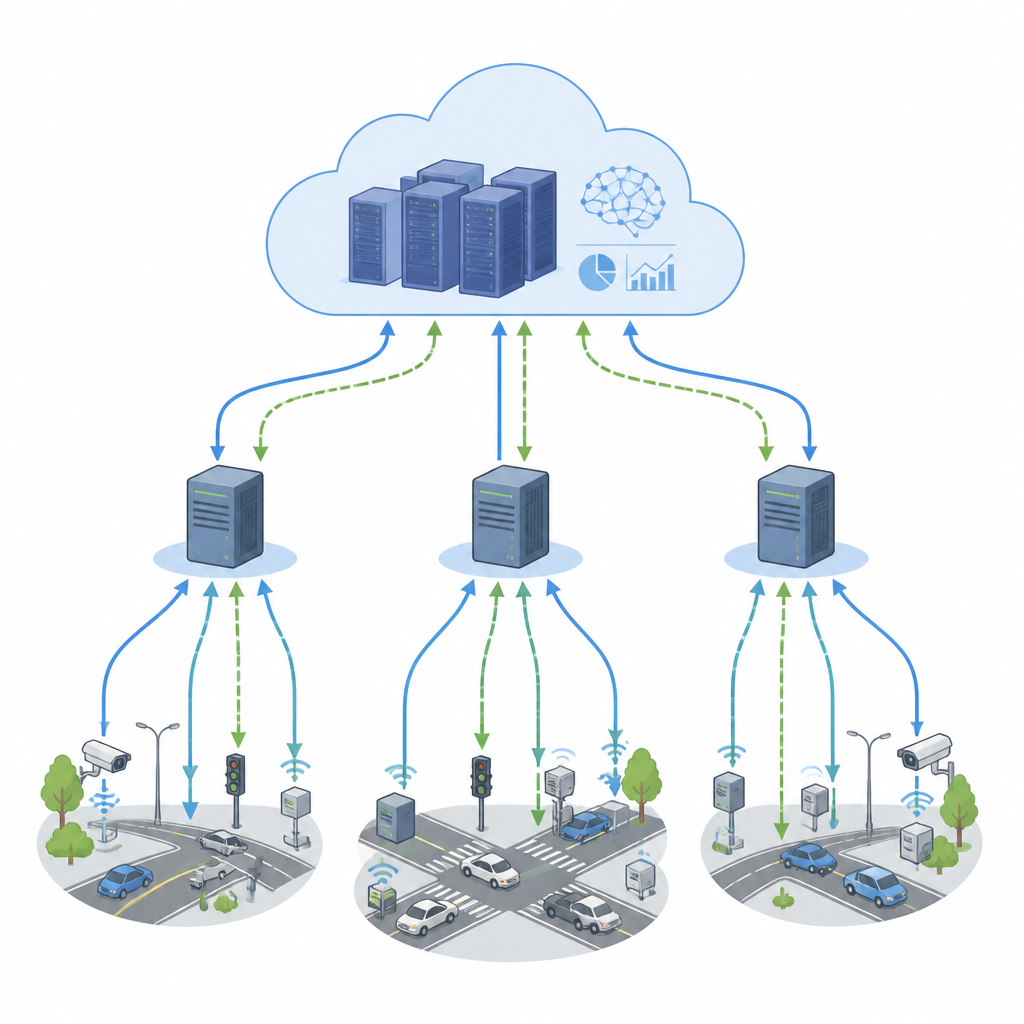
De groeipijnen van samenwerking tussen edge en cloud
Slimme camera’s, voertuigen en industriële sensoren sturen nu eindeloze datastromen die in real time geanalyseerd moeten worden. Edge-servers dicht bij gebruikers verminderen vertraging, terwijl clouddatacenters extra rekenkracht leveren. Toch is het moeilijk te bepalen waar elk stuk werk moet draaien, omdat taken van elkaar afhangen en werklasten onverwacht pieken. Klassieke planningsmethoden leunen op vaste regels of offline planning. Ze functioneren in rustigere omgevingen, maar hebben moeite wanneer duizenden taken en machines zich elke seconde moeten aanpassen over meerdere regio’s. Volledig gecentraliseerde sturing kan een knelpunt worden, terwijl volledig onafhankelijke lokale controllers vaak over gedeelde middelen met elkaar concurreren.
Leren plannen, maar zonder op elkaars tenen te trappen
Recente benaderingen laten softwareagenten door trial-and-error goede planningsregels leren, een techniek genaamd reinforcement learning. Gefedereerd leren maakt het mogelijk dat veel agenten samen trainen terwijl ze ruwe data lokaal houden, wat belangrijk is voor privacy en bandbreedte. Echter, wanneer elke cluster van edge-machines zelfstandig leert en slechts af en toe modellen synchroniseert, kunnen hun acties nog steeds conflicteren. Twee clusters kunnen tegelijk naar dezelfde cloudservers offloaden, of taken heen en weer schuiven, wat extra vertraging en verspilde energie veroorzaakt. De auteurs stellen dat wat ontbreekt een expliciete manier is voor deze agenten om met elkaar te communiceren en te onderhandelen voordat ze handelen.
Een onderhandelingstafel voor digitale planners
Het voorgestelde kader, FedNeg-RL, voegt een lichtgewicht onderhandelingslaag toe bovenop gefedereerd reinforcement learning. Elke cluster van edge-apparaten heeft een representatieve agent die de lokale belasting bewaakt, het verkeer op korte termijn voorspelt en bijhoudt welke taken het meest gevoelig zijn voor vertraging. Voordat ze wijzigingen doorvoeren die gedeelde links of cloudnodes kunnen beïnvloeden, wisselen deze vertegenwoordigers korte samenvattingen uit, zoals verwachte belasting en de waarschijnlijke impact van hun acties, in plaats van ruwe data. Met eenvoudige argumentatiestukken onderhandelen ze over een gezamenlijk plan dat botsingen voorkomt, waarna elke cluster de afgesproken actie lokaal uitvoert. Na verloop van tijd wordt hun leerproces zo gevormd dat het plannen bevordert die latentie laag houden, energie en kosten redelijk houden en conflicten zeldzaam maken. 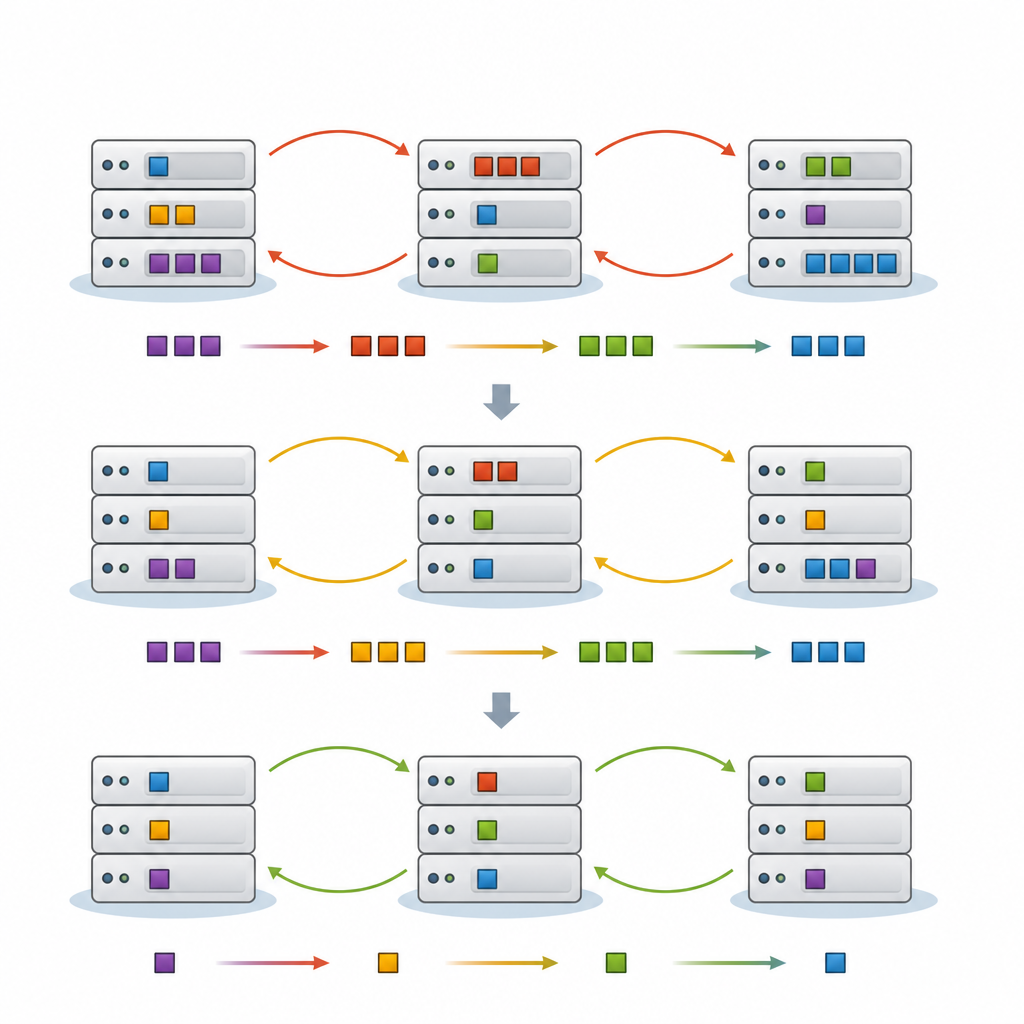
Het testen van de aanpak in drukke virtuele steden
Om FedNeg-RL te evalueren bouwden de auteurs gedetailleerde simulaties van Internet-of-Things-achtige werklasten, inclusief honderden onderling verbonden taken en bursty, moeilijk voorspelbare datastromen vergelijkbaar met die in verkeersmonitoring voor slimme steden. Ze vergeleken hun methode met regelgebaseerde planners, evolutionaire algoritmen, standaard lokaal reinforcement learning, puur gefedereerd leren en een enkele gecentraliseerde leeragent. In veel scenario’s verminderde FedNeg-RL het aantal verstoorde reconfiguraties door conflicten met maximaal 41 procent, verlaagde het de hoge latentie (de traagste 10 procent van de reacties) met ongeveer 20 tot 28 procent, en verminderde het adaptatie-overhead met ongeveer 35 procent. Het gebruikte ook energie gelijkmatiger en schaalt goed naarmate het aantal taken en machines toenam.
Wat dit betekent voor toekomstige verbonden systemen
Simpel gezegd laat FedNeg-RL zien dat het softwarecontrollers niet alleen leren van ervaring, maar ook onderhandelen met hun peers, kan zorgen dat gedeelde edge- en cloudinfrastructuur soepeler draait. In plaats van versnipperde, concurrerende beslissingen coördineren clusters net genoeg om streamingapplicaties responsief, stabiel en efficiënt te houden, zonder private data prijs te geven of te vertrouwen op één centraal brein. Naarmate implementaties in de echte wereld groter en complexer worden, kan dergelijke onderhandelingsbewuste learning helpen waarborgen dat het onzichtbare rekencentrum achter slimme steden, fabrieken en diensten stilletjes blijft werken, zelfs als de vraag continu verandert.
Bronvermelding: Kang, X., Hua, C. Negotiation-augmented federated reinforcement learning for conflict-free edge–cloud stream scheduling. Sci Rep 16, 15158 (2026). https://doi.org/10.1038/s41598-026-45004-3
Trefwoorden: edge cloud planning, gefedereerd reinforcement learning, IoT streaming, meerdere agenten onderhandeling, latentiereductie