Clear Sky Science · ru
Анализ важности признаков на основе корреляции для улучшения предсказаний устойчивости машинного обучения в гибридных фотоэлектрических системах
Почему поддерживать стабильность энергосети становится сложнее
По мере того как всё больше домов и предприятий переходят на солнечную энергию, поддерживать стабильность электрической сети становится труднее. Прохождение облаков над панелями или резкие изменения спроса могут сдвигать напряжения вверх и вниз так, как традиционные методы управления не были рассчитаны обрабатывать. В этой работе исследуется, как современные методы машинного обучения могут выступать в роли системы раннего предупреждения о таких возмущениях, прогнозируя как напряжение в сети, так и общую устойчивость в гибридных системах, где солнечная энергия сочетается с традиционными источниками.
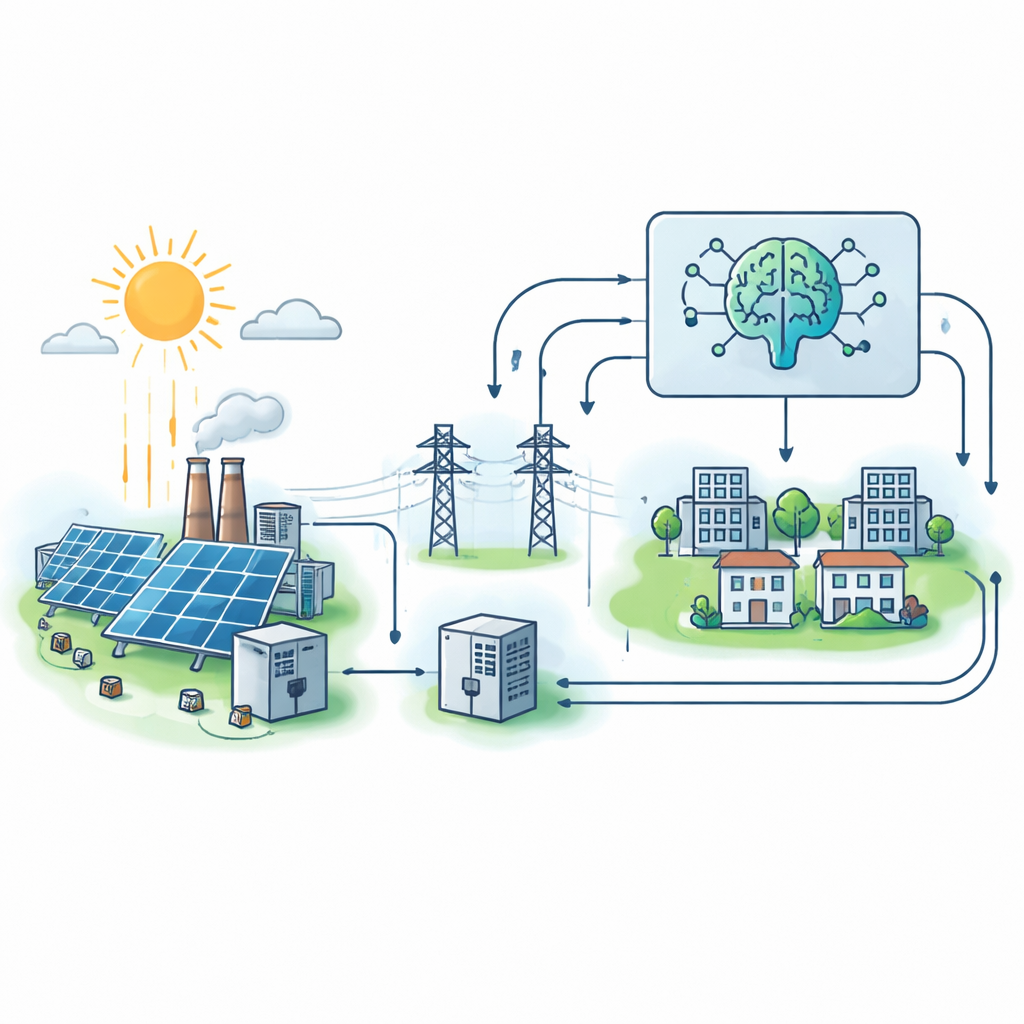
Как был создан цифровой двойник питаемой от солнца сети
Вместо того чтобы полагаться на шумные или неполные полевые измерения, авторы сначала создали подробный «цифровой двойник» подключённой к сети солнечной микросети в MATLAB/Simulink. Эта виртуальная система включает солнечные панели, электронный инвертор, связывающий их с сетью, и потребительские нагрузки, которые меняются в зависимости от напряжения и частоты. Систематически варьируя освещённость, температуру, уровень нагрузки и рабочие условия инвертора, они сгенерировали 500 реалистичных рабочих сценариев. Для каждого сценария модель фиксирует ток и напряжение сети, а также составной показатель устойчивости, отражающий способность системы переносить возмущения, насколько плотно контролируются напряжение и частота, и не приближается ли инвертор к своим пределам.
Преобразование сырых сигналов в содержательные подсказки
Из этих симуляций были выбраны шесть ключевых сигналов в качестве входов для прогнозирования: температура окружающей среды, солнечная радиация, уровень нагрузки, напряжение постоянного звена (DC-link), выходная мощность инвертора и ток в сети. Команда нормализовала и очистила данные, удалив выбросы, а затем применила простую, но эффективную идею, чтобы выделить наиболее значимые параметры: взвешивание признаков на основе корреляции. Для каждого входа они измерили, насколько сильно он связан с целевыми выходами — напряжением в сети и показателем устойчивости. Признаки с более сильными связями получали более высокие веса перед обучением моделей. Этот шаг не создаёт новых данных, но заставляет процесс обучения уделять больше внимания физически важным величинам, таким как ток в сети и напряжение постоянного звена.
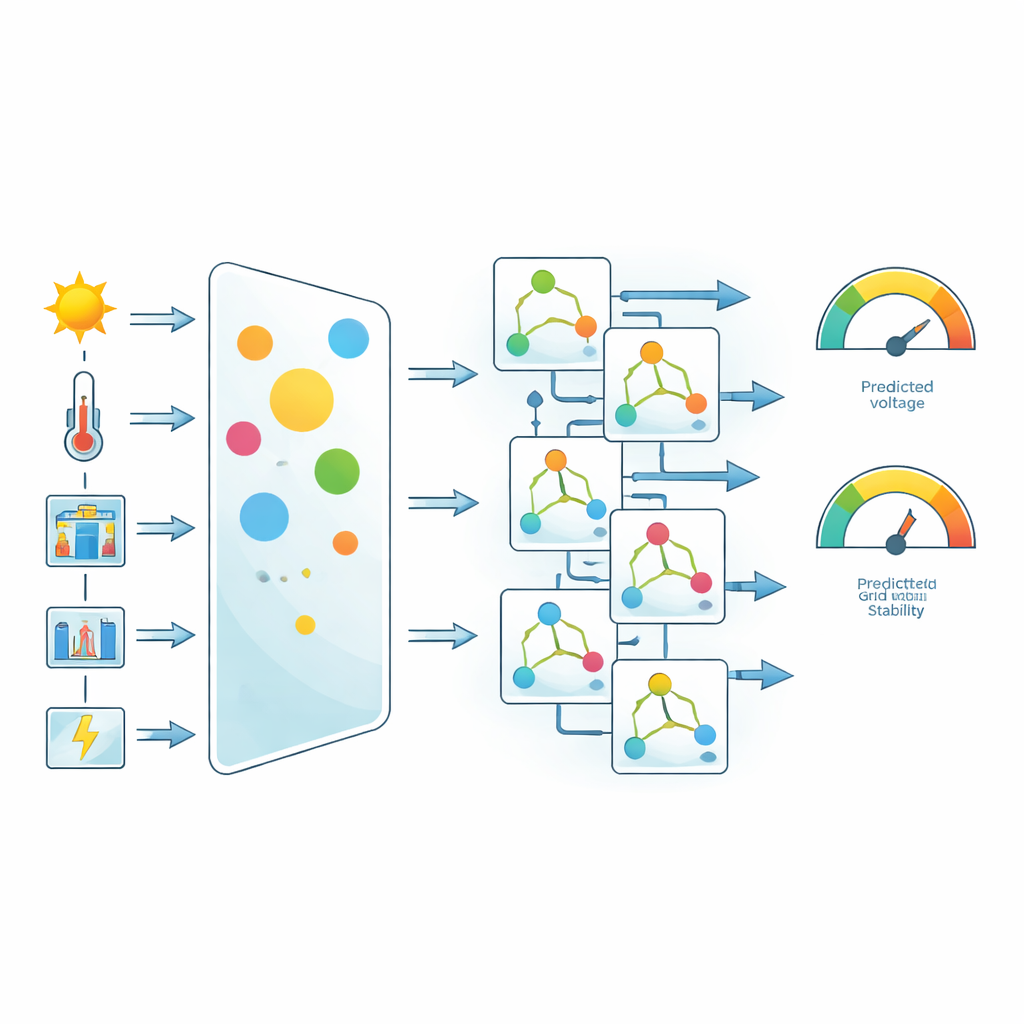
Пять алгоритмов машинного обучения на испытании
Имея во владении взвешенный набор данных, авторы сравнили пять популярных подходов машинного обучения: случайные леса (Random Forests), Extra Trees, регрессию опорных векторов (Support Vector Regression), CatBoost и градиентный бустинг. Все модели обучались и тестировались в одинаковых условиях, с разбиением данных 80:20 и общим набором мер точности. Эти метрики включали привычный коэффициент детерминации (насколько объясняется разброс) и несколько показателей ошибок, которые оценивают как средние отклонения, так и распределение этих ошибок. Исследование также выходило за рамки заголовочных чисел, анализируя, как ошибки распределяются во времени и как часто прогнозы остаются в пределах жёстких допустимых полос.
Почему выделился градиентный бустинг
Градиентный бустинг, который строит последовательность простых моделей, каждая из которых исправляет ошибки предыдущих, последовательно давал самые точные и надёжные предсказания. Для напряжения в сети он очень точно соответствовал измеренным значениям: тестовый R² около 0,98 и типичные процентные ошибки порядка четверти процента; примерно 95% ошибок напряжения оставались в пределах половины вольта. Для показателя устойчивости он вновь оказался лучшим, объясняя более 93% вариации со средними ошибками менее одной единицы. При применении корреляционно-взвешенных признаков его точность ещё больше улучшалась, особенно для прогноза устойчивости, а распределения ошибок стали уже и более однородными по сравнению с конкурентами. Это указывает не только на высокую среднюю производительность, но и на предсказуемое поведение в спокойных и быстро меняющихся режимах работы.
Что это означает для будущих сетей с высокой долей солнечной энергии
Для неспециалистов ключевой вывод таков: тщательно спроектированные инструменты машинного обучения могут дать операторам сети надёжный предварительный прогноз того, как система с большим числом солнечных источников поведёт себя в ближайшие моменты и минуты. Сочетая физически обоснованный цифровой двойник, простую корреляционную аналитику и мощный ансамблевый метод вроде градиентного бустинга, такая структура может сигнализировать о вероятных сдвигах напряжения или сокращении запаса устойчивости системы. Это, в свою очередь, поддерживает более умные настройки инверторов, лучшее использование реактивной мощности и более целевое обслуживание, уменьшая как отключения, так и необоснованное ограничение выработки чистой энергии. По сути, исследование показывает, что добавление интерпретируемого слоя данных и выводов поверх существующего аппаратного управления может сделать энергосети с большой долей возобновляемых источников более устойчивыми, эффективными и простыми в управлении.
Цитирование: Swarnkar, V., Ralhan, S., Singh, M. et al. Correlation based feature importance analysis for improving machine learning stability predictions in hybrid PV systems. Sci Rep 16, 10041 (2026). https://doi.org/10.1038/s41598-026-37270-y
Ключевые слова: гибридные фотоэлектрические системы, прогнозирование напряжения в сети, машинное обучение для энергосетей, градиентный бустинг, устойчивость сетей с возобновляемыми источниками