Clear Sky Science · de
Korrelationbasierte Merkmalsbedeutungsanalyse zur Verbesserung von maschinellen Lernvorhersagen der Stabilität in hybriden PV-Systemen
Warum es immer schwerer wird, die Lichter stabil zu halten
Je mehr Haushalte und Unternehmen Solarstrom nutzen, desto anspruchsvoller wird die Aufrechterhaltung der Netzstabilität. Vorüberziehende Wolken über den Modulen oder plötzliche Nachfrageschwankungen können Spannungen in eine Richtung oder andere verschieben — Effekte, für die traditionelle Regelungskonzepte nicht ausgelegt sind. Dieser Beitrag untersucht, wie modernes maschinelles Lernen als Frühwarnsystem für solche Störungen dienen kann und sowohl Netzspannung als auch die Gesamtstabilität in hybriden Systemen vorhersagt, die Solarenergie mit konventionellen Quellen mischen.
Wie ein Digital Twin eines solarbetriebenen Netzes aufgebaut wurde
Anstatt sich auf verrauschte oder unvollständige Feldmessungen zu stützen, erstellten die Autoren zunächst einen detaillierten „Digital Twin“ eines netzgekoppelten Solar-Mikronetzes in MATLAB/Simulink. Dieses virtuelle System umfasst Solarmodule, einen elektronischen Wechselrichter, der sie mit dem Netz verbindet, und Kundenlasten, die sich mit Spannung und Frequenz ändern. Durch systematisches Variieren von Sonneneinstrahlung, Temperatur, Lastanforderung und Betriebsbedingungen des Wechselrichters erzeugten sie 500 realistische Betriebsszenarien. Für jedes Szenario zeichnet das Modell Netzstrom, -spannung und einen zusammengesetzten Stabilitätswert auf, der widerspiegelt, wie gut das System Störungen übersteht, wie eng Spannung und Frequenz gehalten werden und ob der Wechselrichter nahe an seinen Grenzen arbeitet.
Rohsignale in aussagekräftige Hinweise verwandeln
Aus diesen Simulationen wählten sie sechs Schlüsselgrößen als Eingaben für die Vorhersage: Umgebungstemperatur, Sonneneinstrahlung, Lastniveau, DC-Link-Spannung, Wechselrichterausgangsleistung und Netzstrom. Das Team normalisierte und bereinigte die Daten, entfernte Ausreißer und nutzte dann eine einfache, aber wirkungsvolle Idee, um Wichtiges hervorzuheben: korrelationsbasierte Merkmalsgewichtung. Für jede Eingangsgröße wurde gemessen, wie stark sie mit den Zielgrößen — Netzspannung und Stabilitätswert — zusammenhängt. Merkmale mit stärkeren Zusammenhängen erhielten vor dem Training höhere Gewichte. Dieser Schritt erfindet keine neuen Daten, lenkt aber den Lernprozess dahin, physikalisch bedeutende Variablen wie Netzstrom und DC-Link-Spannung stärker zu berücksichtigen.
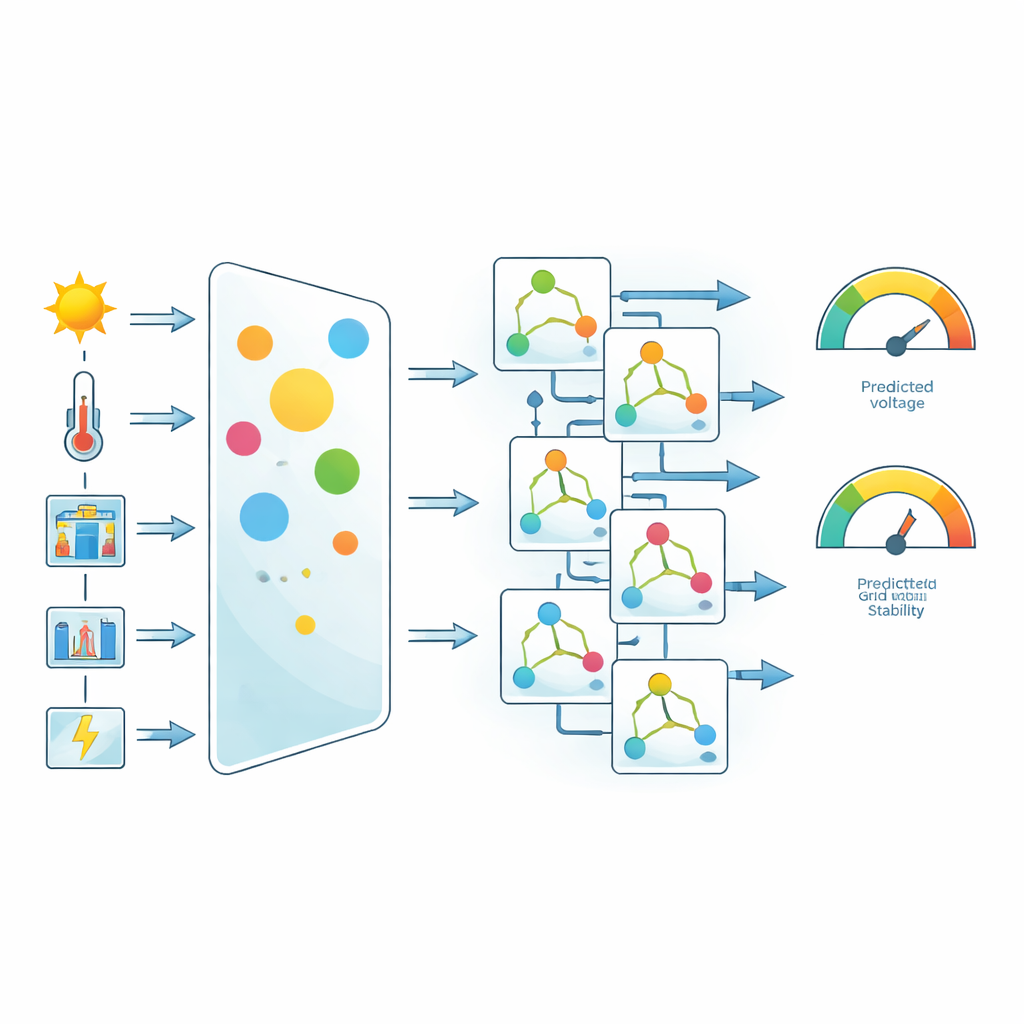
Fünf Lernverfahren im Vergleichstest
Mit dem gewichteten Datensatz verglichen die Autoren fünf verbreitete Ansätze des maschinellen Lernens: Random Forests, Extra Trees, Support Vector Regression, CatBoost und Gradient Boosting. Alle Modelle wurden unter denselben Bedingungen trainiert und getestet, mit einer 80:20-Datenaufteilung und derselben Auswahl an Genauigkeitsmaßen. Zu diesen Maßen gehörten der bekannte Bestimmtheitskoeffizient (wie viel der Variation erklärt wird) und mehrere Fehlermetriken, die sowohl durchschnittliche Fehler als auch deren Streuung betrachten. Die Studie ging über diese Kennzahlen hinaus und untersuchte, wie Fehler über die Zeit verteilt sind und wie häufig Vorhersagen innerhalb enger Toleranzbänder bleiben.
Warum Gradient Boosting herausstach
Gradient Boosting, das eine Folge einfacher Modelle aufbaut, bei denen jedes die Fehler der vorherigen korrigiert, lieferte durchgehend die genauesten und verlässlichsten Vorhersagen. Bei der Netzspannung traf es die gemessenen Werte extrem gut: Ein Test-R² von etwa 0,98 und typische Prozentfehler um ein Viertel Prozent; rund 95 % der Spannungsfehler lagen innerhalb von einem halben Volt. Beim Stabilitätswert lag es ebenfalls vorn und erfasste über 93 % der Variation bei mittleren Fehlern unter einer Einheit. Mit Anwendung der korrelationsbasierten Merkmalsgewichte verbesserte sich die Genauigkeit weiter, insbesondere bei der Stabilitätsvorhersage, und die Fehlerverteilungen wurden schmaler und gleichmäßiger als bei den Konkurrenzmodellen. Das deutet nicht nur auf eine hohe mittlere Leistung hin, sondern auf verlässliches Verhalten sowohl bei ruhigem als auch bei schnell wechselndem Betrieb.
Was das für zukünftig solarreiche Netze bedeutet
Für Nicht-Spezialisten lautet die zentrale Botschaft, dass sorgfältig entworfene maschinelle Lernwerkzeuge Netzbetreibern eine vertrauenswürdige Vorschau darauf geben können, wie sich ein solarlastiges System in den nächsten Momenten bis Minuten verhält. Durch die Kombination eines physikbasierten Digital Twin, einfacher Korrelationsanalyse und einer starken Ensemble-Methode wie Gradient Boosting kann das Framework anzeigen, wann Spannungen voraussichtlich driftig werden oder wann die Stabilitätsreserve schrumpft. Das unterstützt sinnvollere Wechselrichtereinstellungen, besseren Einsatz von Blindleistung und gezieltere Wartung, was Ausfälle und unnötige Einschnitte bei sauberer Energie reduziert. Im Kern zeigt die Studie, dass eine interpretierbare, datengetriebene Intelligenzschicht oberhalb vorhandener Steuerungshardware erneuerbare-reiche Netze widerstandsfähiger, effizienter und einfacher zu betreiben machen kann.
Zitation: Swarnkar, V., Ralhan, S., Singh, M. et al. Correlation based feature importance analysis for improving machine learning stability predictions in hybrid PV systems. Sci Rep 16, 10041 (2026). https://doi.org/10.1038/s41598-026-37270-y
Schlüsselwörter: hybride photovoltaische Systeme, Netzspannungsvorhersage, Maschinelles Lernen für Stromnetze, Gradient Boosting, Stabilität erneuerbarer Energien im Netz