Clear Sky Science · es
Análisis de importancia de características basado en correlación para mejorar las predicciones de estabilidad mediante aprendizaje automático en sistemas fotovoltaicos híbridos
Por qué mantener las luces estables se está volviendo más difícil
A medida que más hogares y empresas funcionan con energía solar, mantener la estabilidad de la red eléctrica se complica. Las nubes que pasan sobre los paneles o cambios bruscos en la demanda pueden empujar los voltajes arriba y abajo de formas que los métodos de control tradicionales no estaban diseñados para afrontar. Este artículo explora cómo el aprendizaje automático moderno puede actuar como un sistema de alerta temprana para esas perturbaciones, prediciendo tanto el voltaje de la red como la estabilidad general en sistemas híbridos que combinan energía solar con fuentes convencionales.
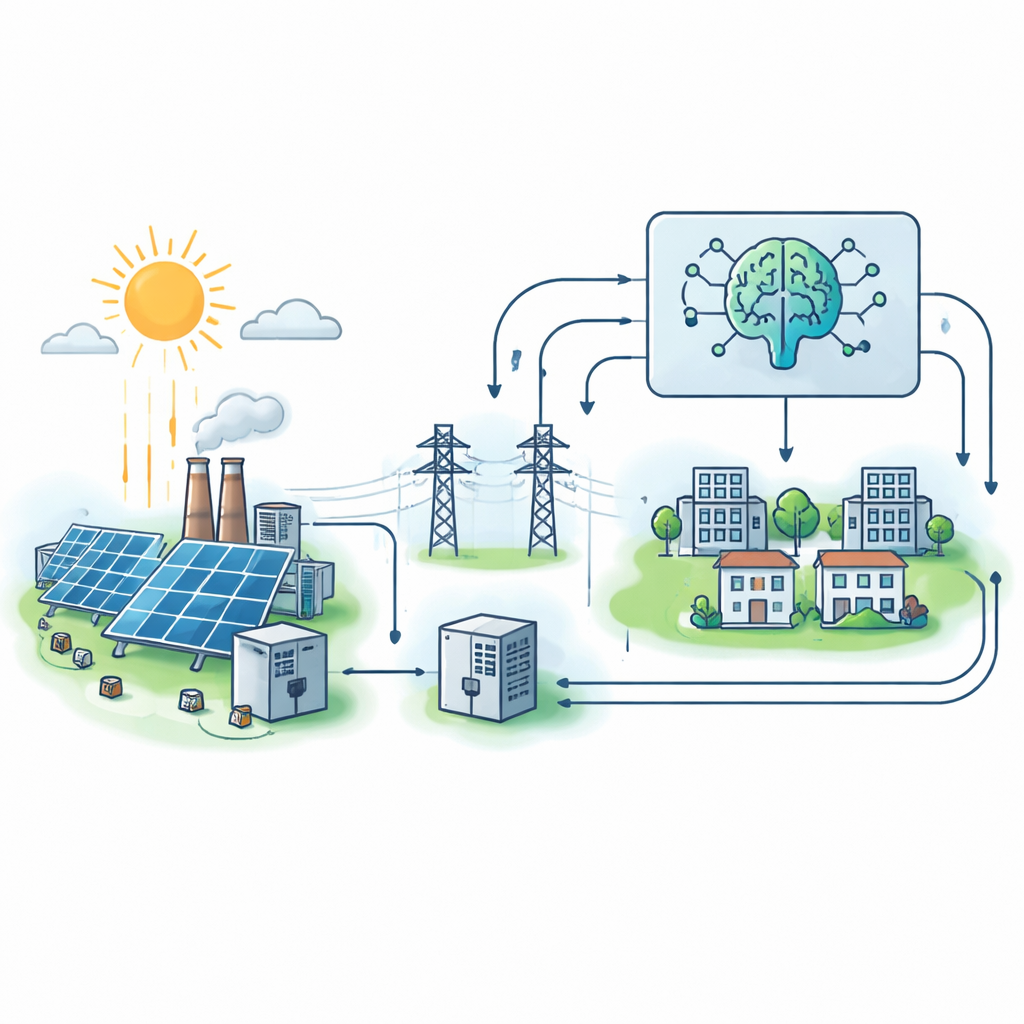
Cómo se construyó un gemelo digital de una red alimentada por solar
En lugar de depender de mediciones de campo ruidosas o incompletas, los autores primero crearon un detallado “gemelo digital” de una microrred conectada a la red en MATLAB/Simulink. Este sistema virtual incluye paneles solares, un inversor electrónico que los enlaza a la red y cargas de clientes que cambian con el voltaje y la frecuencia. Variando sistemáticamente la irradiación solar, la temperatura, la demanda de carga y las condiciones de operación del inversor, generaron 500 escenarios operativos realistas. Para cada uno, el modelo registra la corriente de la red, el voltaje y una puntuación compuesta de estabilidad que refleja cómo responde el sistema ante perturbaciones, qué tan bien se controlan el voltaje y la frecuencia y si el inversor está cerca de sus límites.
Convertir señales crudas en pistas significativas
A partir de estas simulaciones se seleccionaron seis señales clave como entradas para la predicción: temperatura ambiente, irradiancia solar, nivel de carga, voltaje del enlace de CC, potencia de salida del inversor y corriente de la red. El equipo normalizó y limpió los datos, eliminó valores atípicos y luego empleó una idea simple pero poderosa para resaltar lo que importa: ponderación de características basada en correlación. Para cada entrada midieron qué tan fuertemente se desplaza con las salidas objetivo, el voltaje de la red y la puntuación de estabilidad. A las características con vínculos más fuertes se les asignaron pesos mayores antes de entrenar los modelos. Este paso no inventa nuevos datos, pero orienta el proceso de aprendizaje para prestar más atención a variables físicamente importantes, como la corriente de la red y el voltaje del enlace de CC.
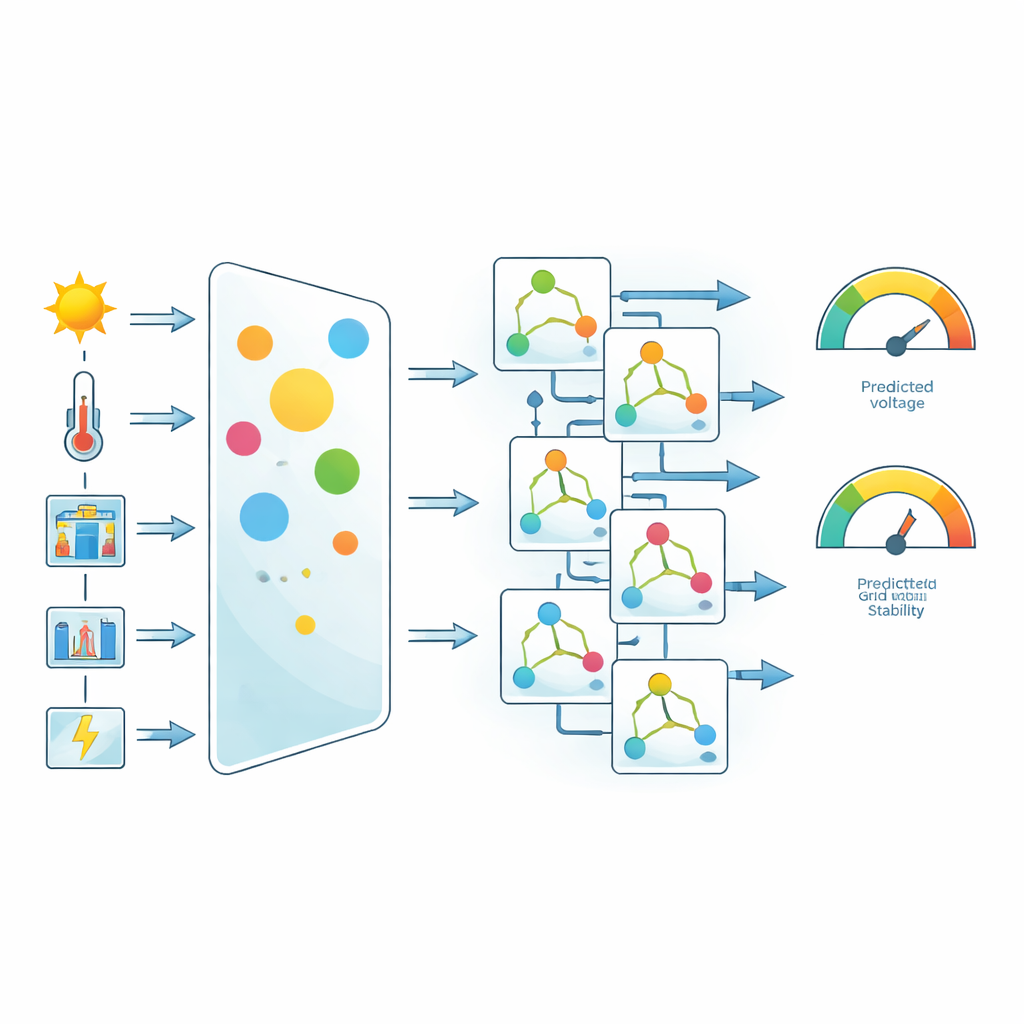
Poner a prueba cinco máquinas de aprendizaje
Con el conjunto de datos ponderado en mano, los autores compararon cinco enfoques populares de aprendizaje automático: Random Forests, Extra Trees, Support Vector Regression, CatBoost y Gradient Boosting. Todos los modelos se entrenaron y evaluaron en las mismas condiciones, usando una división 80:20 de los datos y un conjunto común de medidas de precisión. Estas medidas incluyeron el conocido coeficiente de determinación (cuánta variación se explica) y varias métricas de error que analizan tanto los errores medios como la dispersión de esos errores. El estudio además fue más allá de los números principales, examinando cómo se distribuían los errores en el tiempo y con qué frecuencia las predicciones permanecían dentro de bandas de tolerancia estrechas.
Por qué destacó gradient boosting
Gradient Boosting, que construye una secuencia de modelos simples que corrigen cada uno los errores del anterior, ofreció de forma consistente las predicciones más precisas y fiables. Para el voltaje de la red, coincidió extremadamente bien con los valores medidos, con un R² de prueba de alrededor de 0,98 y errores porcentuales típicos en torno a una cuarta parte de punto porcentual; aproximadamente el 95% de los errores de voltaje se mantuvo dentro de medio voltio. Para la puntuación de estabilidad, también resultó vencedor, capturando más del 93% de la variación con errores medios por debajo de una unidad. Cuando se aplicaron los pesos de características basados en correlación, su precisión mejoró aún más, especialmente en la predicción de estabilidad, y sus distribuciones de error se volvieron más estrechas y uniformes que las de los modelos competidores. Esto indica no solo un alto rendimiento medio, sino un comportamiento fiable tanto en condiciones calmadas como en cambios operativos rápidos.
Qué significa esto para futuras redes con alta presencia solar
Para el público no especialista, el mensaje clave es que herramientas de aprendizaje automático bien diseñadas pueden ofrecer a los operadores de red una vista previa de confianza sobre cómo se comportará un sistema con mucha energía solar en los próximos instantes o minutos. Al combinar un gemelo digital basado en física, un análisis de correlación sencillo y un método ensemblista potente como Gradient Boosting, el marco puede señalar cuándo es probable que los voltajes deriven o cuándo está disminuyendo el margen de estabilidad del sistema. Esto, a su vez, facilita ajustes más inteligentes del inversor, un uso más eficaz de la potencia reactiva y un mantenimiento más dirigido, reduciendo tanto las interrupciones como las curtailments innecesarios de energía limpia. En esencia, el estudio muestra que añadir una capa interpretable de inteligencia basada en datos sobre el hardware de control existente puede hacer que las redes ricas en renovables sean más resilientes, eficientes y fáciles de gestionar.
Cita: Swarnkar, V., Ralhan, S., Singh, M. et al. Correlation based feature importance analysis for improving machine learning stability predictions in hybrid PV systems. Sci Rep 16, 10041 (2026). https://doi.org/10.1038/s41598-026-37270-y
Palabras clave: sistemas fotovoltaicos híbridos, predicción de voltaje de la red, aprendizaje automático para redes eléctricas, gradient boosting, estabilidad de la red con renovables