Clear Sky Science · it
Analisi dell’importanza delle caratteristiche basata sulla correlazione per migliorare le previsioni di stabilità mediante apprendimento automatico in sistemi PV ibridi
Perché mantenere la luce costante sta diventando più difficile
Con un numero crescente di abitazioni e attività alimentate dal sole, mantenere stabile la rete elettrica diventa più complesso. Le nuvole che passano sui pannelli o i cambiamenti improvvisi nella domanda possono spostare le tensioni su e giù in modi che i metodi di controllo tradizionali non erano progettati per gestire. Questo articolo esplora come l’apprendimento automatico moderno possa funzionare come un sistema di allerta precoce per tali disturbi, prevedendo sia la tensione di rete sia la stabilità complessiva in sistemi ibridi che mescolano energia solare e sorgenti convenzionali.
Come è stato costruito un gemello digitale di una rete alimentata a energie solari
Invece di affidarsi a misure di campo rumorose o incomplete, gli autori hanno prima creato un dettagliato “gemello digitale” di un microgrid fotovoltaico connesso alla rete in MATLAB/Simulink. Questo sistema virtuale include pannelli solari, un inverter elettronico che li collega alla rete e carichi dei clienti che variano con tensione e frequenza. Variando in modo sistematico irraggiamento solare, temperatura, richiesta di carico e condizioni operative dell’inverter, hanno generato 500 scenari operativi realistici. Per ciascuno, il modello registra corrente di rete, tensione e un punteggio composito di stabilità che riflette quanto bene il sistema supera i disturbi, quanto strettamente sono controllati tensione e frequenza e se l’inverter si avvicina ai suoi limiti.
Trasformare segnali grezzi in indizi significativi
Dalle simulazioni sono stati scelti sei segnali chiave come input per la previsione: temperatura ambiente, irraggiamento solare, livello di carico, tensione del collegamento DC, potenza in uscita dell’inverter e corrente di rete. Il team ha normalizzato e pulito i dati, rimosso gli outlier e poi ha usato un’idea semplice ma efficace per evidenziare ciò che conta di più: pesatura delle caratteristiche basata sulla correlazione. Per ciascun input hanno misurato quanto si muove in modo coerente con gli output target, tensione di rete e punteggio di stabilità. Le caratteristiche con legami più forti hanno ricevuto pesi maggiori prima dell’addestramento dei modelli. Questo passaggio non inventa nuovi dati, ma spinge il processo di apprendimento a prestare maggiore attenzione a variabili fisicamente importanti come la corrente di rete e la tensione del link DC.
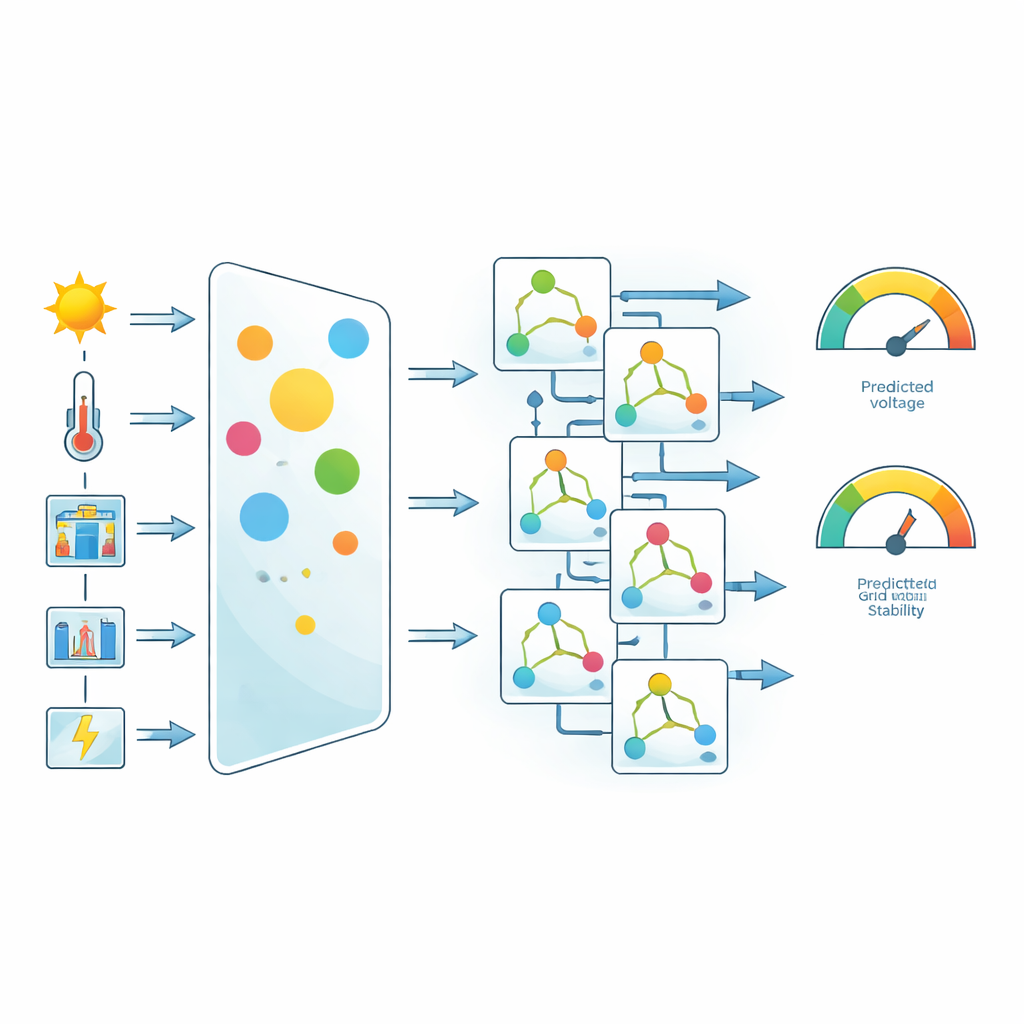
Mettere alla prova cinque macchine di apprendimento
Con il dataset pesato a disposizione, gli autori hanno confrontato cinque popolari approcci di machine learning: Random Forests, Extra Trees, Support Vector Regression, CatBoost e Gradient Boosting. Tutti i modelli sono stati addestrati e testati nelle stesse condizioni, usando una suddivisione 80:20 dei dati e un insieme comune di misure di accuratezza. Queste misure includevano il familiare coefficiente di determinazione (quanto della variazione è spiegato) e diversi punteggi di errore che considerano sia gli errori medi sia la dispersione di quegli errori. Lo studio è andato oltre i numeri principali, esaminando come gli errori si distribuiscono nel tempo e quanto spesso le previsioni restano entro bande di tolleranza ristrette.
Perché il gradient boosting si è distinto
Il Gradient Boosting, che costruisce una sequenza di modelli semplici che correggono ciascuno gli errori dei precedenti, ha fornito costantemente le previsioni più accurate e affidabili. Per la tensione di rete ha riprodotto i valori misurati in modo estremamente fedele, con un R² di test di circa 0,98 e errori percentuali tipici intorno a un quarto di punto percentuale; circa il 95% degli errori di tensione è rimasto entro mezzo volt. Per il punteggio di stabilità è risultato nuovamente il migliore, catturando oltre il 93% della variazione con errori medi inferiori a un’unità. Quando sono stati applicati i pesi delle caratteristiche basati sulla correlazione, la sua accuratezza è ulteriormente migliorata, specialmente nella previsione della stabilità, e le sue distribuzioni di errore sono diventate più strette e uniformi rispetto a quelle dei modelli concorrenti. Ciò indica non solo alte prestazioni medie, ma un comportamento affidabile sia in condizioni calme sia in condizioni operative rapidamente variabili.
Cosa significa questo per le reti future ricche di solare
Per i non specialisti, il messaggio chiave è che strumenti di machine learning progettati con cura possono fornire agli operatori di rete un’anteprima attendibile di come si comporterà un sistema fortemente solare nei momenti o nei minuti successivi. Combinando un gemello digitale basato sulla fisica, un’analisi di correlazione semplice e un solido metodo ensemble come il Gradient Boosting, il quadro può segnalare quando le tensioni sono destinate a oscillare o quando il margine di stabilità del sistema si sta riducendo. Questo, a sua volta, supporta impostazioni di inverter più intelligenti, un migliore uso della potenza reattiva e manutenzioni più mirate, riducendo sia i blackout sia gli inutili tagli all’energia pulita. In sostanza, lo studio mostra che aggiungere uno strato interpretabile di intelligenza basata sui dati sopra l’hardware di controllo esistente può rendere le reti ricche di rinnovabili più resilienti, efficienti e facili da gestire.
Citazione: Swarnkar, V., Ralhan, S., Singh, M. et al. Correlation based feature importance analysis for improving machine learning stability predictions in hybrid PV systems. Sci Rep 16, 10041 (2026). https://doi.org/10.1038/s41598-026-37270-y
Parole chiave: sistemi fotovoltaici ibridi, predizione della tensione di rete, apprendimento automatico per reti elettriche, gradient boosting, stabilità della rete rinnovabile