Clear Sky Science · nl
Correlatiegebaseerde feature-importance-analyse voor het verbeteren van machinaal-leren-voorspellingen van stabiliteit in hybride PV-systemen
Waarom het lastiger wordt om de lichten stabiel te houden
Naarmate meer woningen en bedrijven op zonne-energie draaien, wordt het handhaven van een stabiel elektriciteitsnet ingewikkelder. Voorbijtrekkende wolken of plotselinge veranderingen in vraag kunnen de spanningen op manieren op- en neerduwen waar traditionele regelmethoden niet op waren ingericht. Dit artikel onderzoekt hoe modern machinaal leren kan functioneren als een vroegwaarschuwingssysteem voor dergelijke verstoringen, door zowel netspanning als de algehele stabiliteit te voorspellen in hybride systemen die zonne-energie combineren met conventionele bronnen.
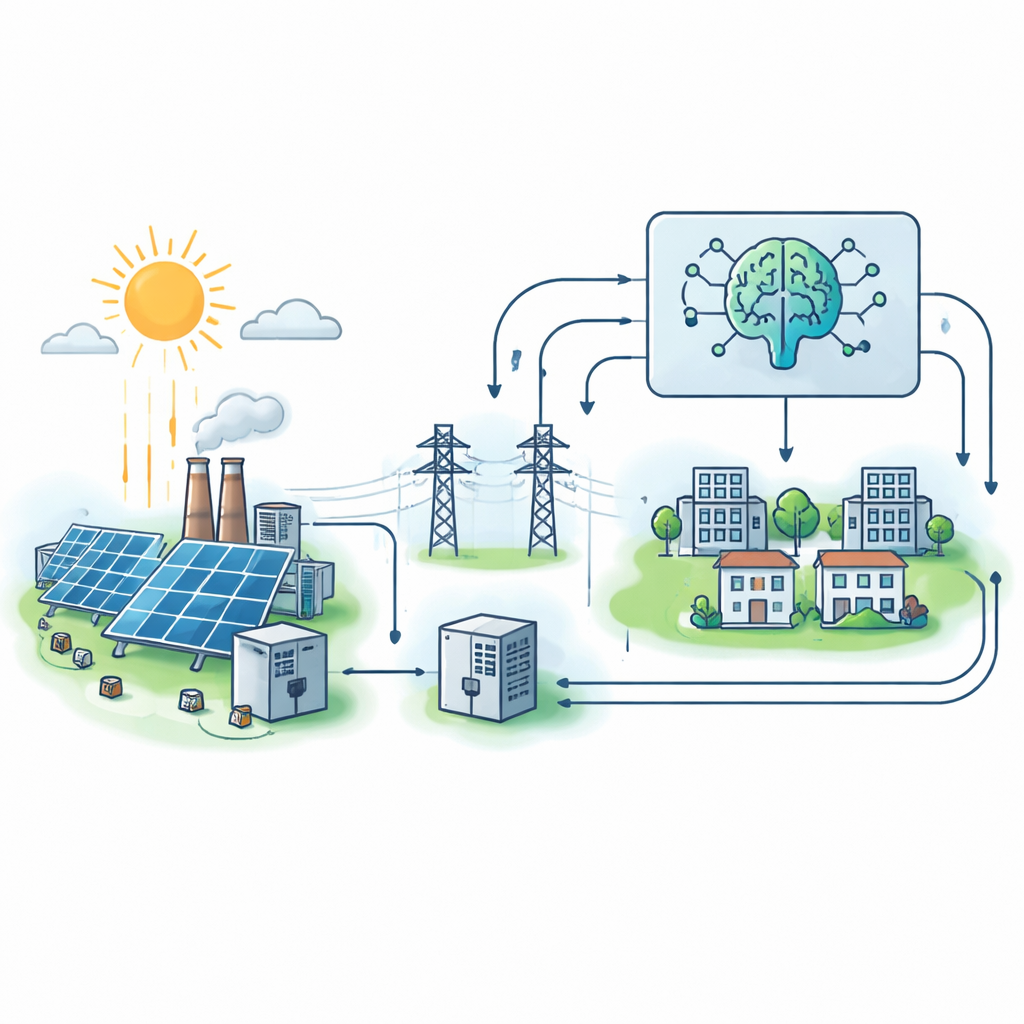
Hoe een digitale tweeling van een zonne-gevoed net werd gebouwd
In plaats van te vertrouwen op lawaaierige of onvolledige veldmetingen, creëerden de auteurs eerst een gedetailleerde “digitale tweeling” van een aan het net gekoppeld zonne-microgrid in MATLAB/Simulink. Dit virtuele systeem omvat zonnepanelen, een elektronische omvormer die ze met het net verbindt, en klantbelastingen die veranderen met spanning en frequentie. Door systematisch zonlicht, temperatuur, belastingsvraag en omvormerbedrijfsomstandigheden te variëren, genereerden ze 500 realistische bedrijfsscenario’s. Voor elk scenario registreert het model netstroom, spanning en een samengestelde stabiliteitsscore die reflecteert hoe goed het systeem verstoringen doorstaat, hoe strak spanning en frequentie worden geregeld en of de omvormer dicht bij zijn limieten komt.
Ruwe signalen omzetten in betekenisvolle aanwijzingen
Uit deze simulaties werden zes sleutel-signalen gekozen als invoer voor de voorspellingen: omgevings-temperatuur, zoninstraling, belastingsniveau, DC-koppelspanning, omvormeruitgangsvermogen en netstroom. Het team normaliseerde en schonk de data, verwijderde uitbijters en gebruikte vervolgens een eenvoudig maar krachtig idee om te benadrukken wat het meest telt: correlatiegebaseerde feature-weging. Voor elke invoer maten ze hoe sterk deze meet met de doeloutputs, netspanning en de stabiliteitsscore. Features met sterkere verbanden kregen hogere gewichten voordat de modellen werden getraind. Deze stap verzint geen nieuwe data, maar stuurt het leerproces om meer aandacht te besteden aan fysiek belangrijke variabelen zoals netstroom en DC-koppelspanning.
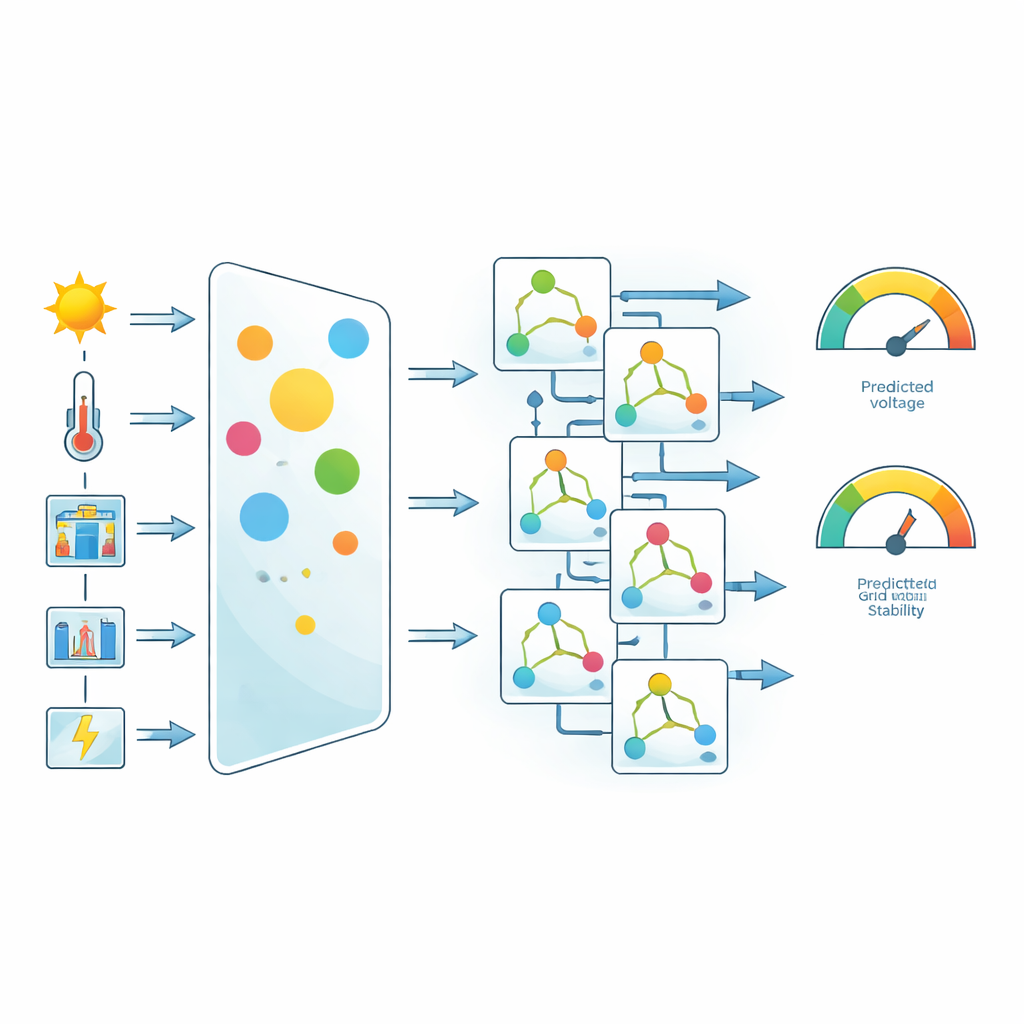
Vijf leeralgoritmen op de proef gesteld
Met de gewogen dataset vergeleken de auteurs vijf populaire machinaal-leren-benaderingen: Random Forests, Extra Trees, Support Vector Regression, CatBoost en Gradient Boosting. Alle modellen werden onder dezelfde condities getraind en getest, met een 80:20-splitsing van de data en een gemeenschappelijke set nauwkeurigheidsmaatstaven. Deze maten includeerden de vertrouwde determinatiecoëfficiënt (hoeveel van de variatie wordt verklaard) en verschillende foutscores die zowel naar gemiddelde fouten als naar de spreiding van die fouten kijken. De studie ging ook verder dan kopcijfers, door te onderzoeken hoe fouten in de tijd verdeeld waren en hoe vaak voorspellingen binnen strakke tolerantiebanden bleven.
Waarom gradient boosting er uitsprong
Gradient Boosting, dat een opeenvolging van eenvoudige modellen opbouwt waarbij elk model de fouten van de vorige corrigeert, leverde consequent de meest accurate en betrouwbare voorspellingen. Voor netspanning kwam het zeer nauwkeurig overeen met gemeten waarden, met een test-R² van ongeveer 0,98 en typische procentuele fouten rond een kwart procent; ruwweg 95% van de spanningsfouten bleef binnen een halve volt. Voor de stabiliteitsscore kwam het opnieuw als beste uit de bus, met meer dan 93% van de verklaarde variantie en gemiddelde fouten onder één eenheid. Toen de correlatiegebaseerde feature-gewichten werden toegepast, verbeterde de nauwkeurigheid verder, vooral voor de stabiliteitsvoorspelling, en werden de foutverdelingen smaller en homogener dan die van concurrerende modellen. Dit wijst niet alleen op hoge gemiddelde prestaties, maar op betrouwbaar gedrag zowel bij rustige als bij snel wisselende bedrijfsomstandigheden.
Wat dit betekent voor toekomstige zonne-rijke netten
Voor niet-specialisten is de kernboodschap dat zorgvuldig ontworpen machinaal-leren-instrumenten netbeheerders een betrouwbare voorspelblik kunnen geven op hoe een zonne-intensief systeem zich in de komende momenten tot minuten zal gedragen. Door een fysisch gebaseerde digitale tweeling, eenvoudige correlatieanalyse en een sterke ensemblemethode zoals Gradient Boosting te combineren, kan het kader signaleren wanneer spanningen waarschijnlijk zullen afdrijven of wanneer de stabiliteitsmarge van het systeem krimpt. Dit ondersteunt op zijn beurt slimmere omvormerinstellingen, beter gebruik van reactief vermogen en meer gerichte onderhoudsacties, waardoor zowel storingen als onnodige beperking van schone energie verminderen. In essentie toont de studie aan dat het toevoegen van een interpreteerbare laag van data-gedreven intelligentie bovenop bestaande regelhardware hernieuwbare-rijke netten veerkrachtiger, efficiënter en gemakkelijker te beheren kan maken.
Bronvermelding: Swarnkar, V., Ralhan, S., Singh, M. et al. Correlation based feature importance analysis for improving machine learning stability predictions in hybrid PV systems. Sci Rep 16, 10041 (2026). https://doi.org/10.1038/s41598-026-37270-y
Trefwoorden: hybride fotovoltaïsche systemen, netspanningvoorspelling, machinaal leren voor elektriciteitsnetten, gradient boosting, hernieuwbare netstabiliteit