Clear Sky Science · pt
Aprendizado de máquina para análise quantitativa por LIBS de ligas de alumínio: comparação entre random forest, gradient boosting e extremely randomized trees
Por que isso importa para o uso cotidiano de metais
De aviões e carros a latas de bebidas e capas de telefone, ligas de alumínio estão por toda parte. Seu desempenho depende de obter a mistura de ingredientes corretamente, mas verificar essa mistura de forma rápida e precisa não é simples. Este estudo mostra como a combinação de um teste a laser rápido com aprendizado de máquina moderno pode fornecer leituras precisas do que há dentro das ligas de alumínio, o que pode ajudar a indústria a reciclar melhor, reduzir desperdício e melhorar a segurança dos produtos.
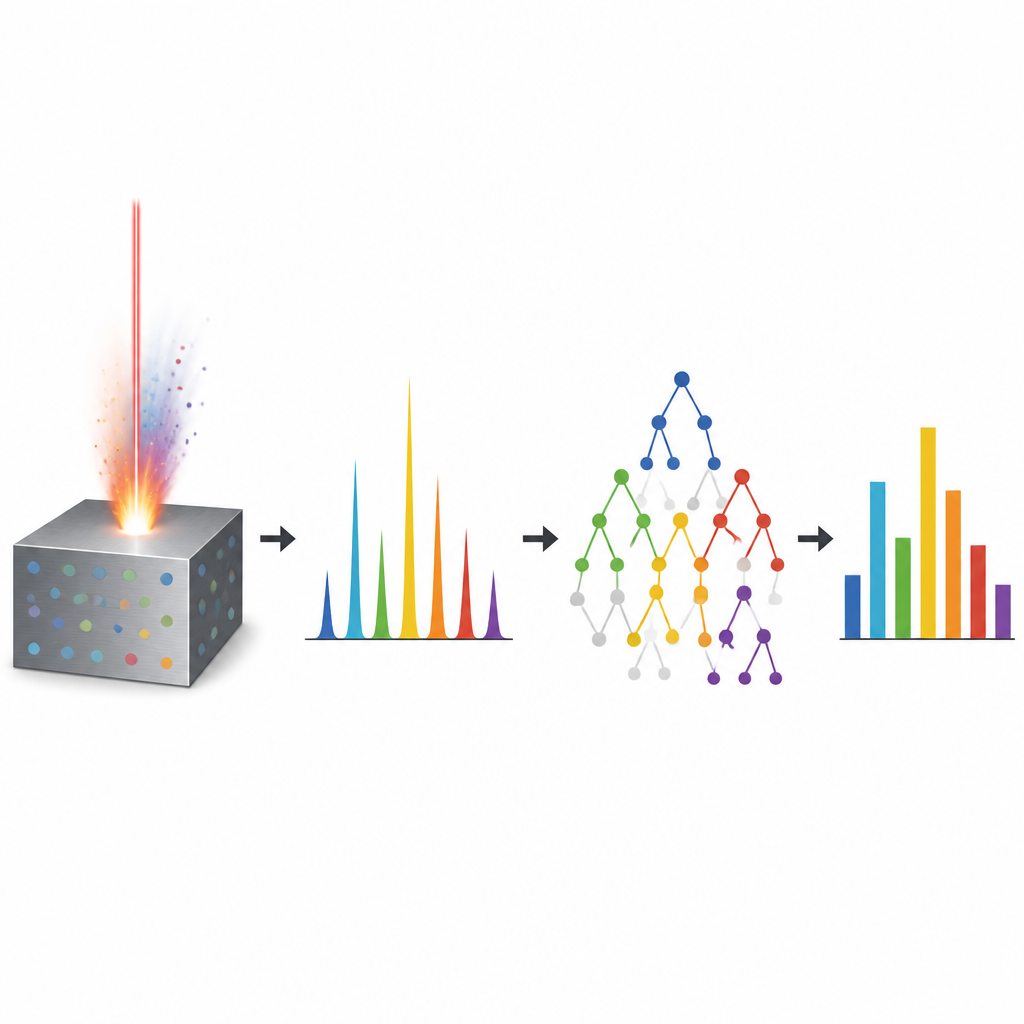
Um laser que lê do que o metal é feito
O trabalho se concentra em uma técnica chamada espectroscopia por plasma induzido por laser, ou LIBS. Em termos simples, um pulso de laser curto e intenso atinge a superfície do metal e vaporiza uma pequena quantidade de material em uma nuvem incandescente. À medida que essa nuvem esfria, ela emite cores que dependem dos elementos presentes. Um espectrômetro registra essa impressão digital colorida ao longo de muitos comprimentos de onda. A LIBS é atraente porque funciona rapidamente, exige quase nenhum preparo de amostra e pode ser usada in loco. No entanto, transformar esses padrões complexos de luz em números precisos para cada elemento — como cobre, zinco ou magnésio — é difícil. Efeitos como autoabsorção da luz, linhas sobrepostas de diferentes elementos e variações na nuvem quente de um pulso para outro tornam a relação entre cor e composição fortemente não linear.
Deixando os algoritmos aprenderem com muitos espectros
Para enfrentar esse problema, os autores recorreram ao aprendizado de máquina, onde computadores aprendem padrões a partir de dados em vez de seguir fórmulas fixas. Eles coletaram 500 espectros LIBS de amostras certificadas de alumínio, incluindo alumínio comercialmente puro e ligas com cobre e zinco em diferentes concentrações. Cada espectro foi cuidadosamente suavizado, interpolado ao longo de uma ampla faixa de cores e normalizado para que o padrão completo, e não apenas alguns picos, pudesse ser fornecido aos algoritmos. Em vez de selecionar manualmente características, os modelos receberam cerca de seis mil valores de intensidade por espectro, permitindo que descobrissem pistas sutis de elementos minoritários ocultos no brilho.
Três modelos baseados em árvores em confronto
A equipe comparou três métodos relacionados de aprendizado de máquina que constroem grandes conjuntos de árvores de decisão: Random Forest, Gradient Boosting e Extremely Randomized Trees. Esses métodos dividem os dados repetidamente em ramos que, eventualmente, levam a uma composição prevista. Ao combinar muitas dessas árvores, eles conseguem lidar com relações complexas e ruidosas. Os pesquisadores treinaram os modelos com a maior parte dos espectros e reservaram alguns para teste. Em seguida, verificaram quão bem cada método conseguia prever as quantidades conhecidas de alumínio, cobre, zinco, magnésio, ferro e silício. Todos os três alcançaram alta precisão, com erros médios bem abaixo de um quarto de porcento em massa. Entre eles, o modelo Extremely Randomized Trees teve o melhor desempenho geral, apresentando os menores erros e maior concordância com os valores de referência, especialmente para ligas binárias e ternárias onde vários elementos interagem.
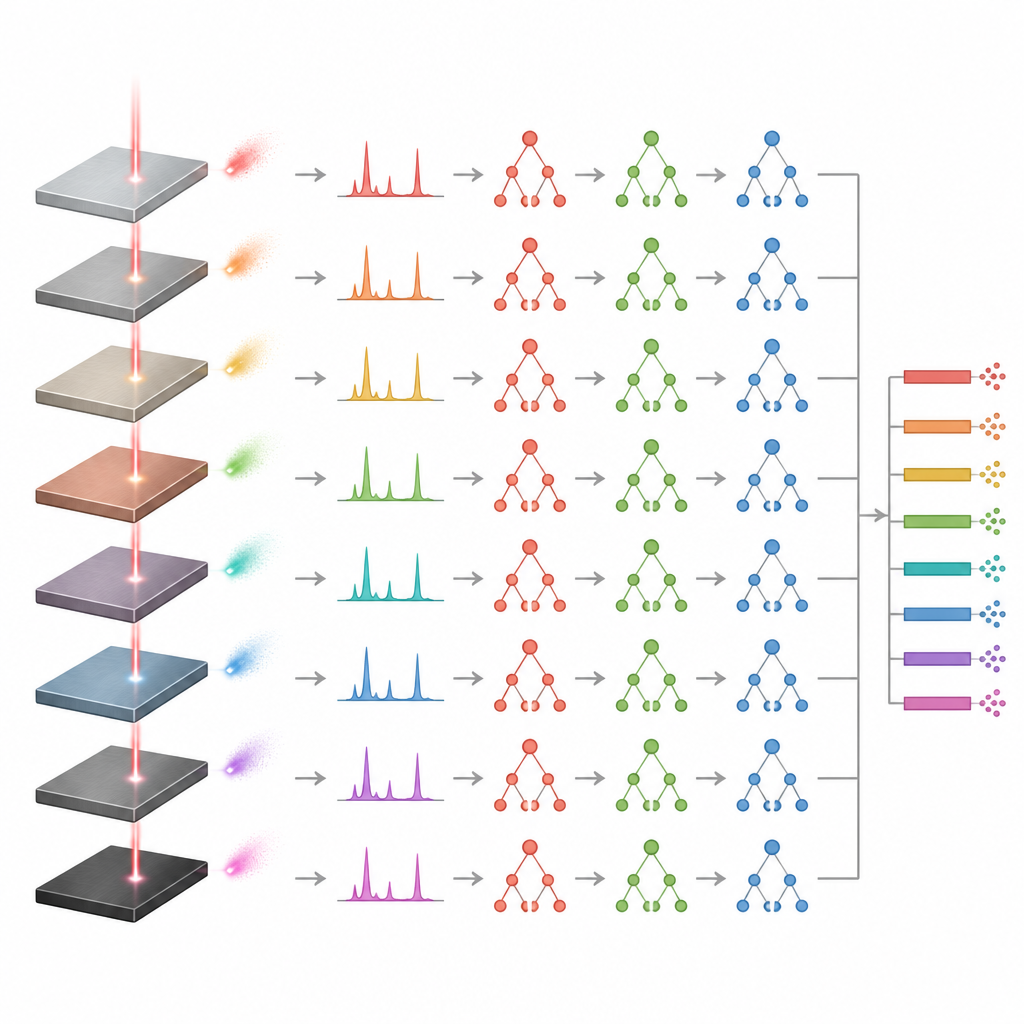
Testando amostras reais e limites
Para avaliar se os modelos realmente generalizavam em vez de memorizar, os autores os testaram em amostras independentes que não foram usadas no treinamento. As previsões para essas novas ligas permaneceram próximas das composições certificadas, confirmando que os modelos podiam lidar com casos não vistos. A abordagem Extremely Randomized Trees novamente apresentou comportamento mais estável, enquanto o Gradient Boosting produziu resultados mais variáveis, que às vezes pareciam aceitáveis estatisticamente apenas por causa dessa maior dispersão. O estudo também encontrou um limite prático importante: quando os dados de treinamento continham apenas uma amostra de uma dada família de ligas, as previsões tornavam-se pouco confiáveis. Foram necessárias pelo menos três amostras representativas por família para que os modelos aprendessem a faixa de composições possíveis.
O que o estudo significa em termos simples
Essencialmente, este artigo mostra que um teste rápido baseado em laser, quando combinado com ferramentas de aprendizado de máquina bem escolhidas, pode ler a “receita” das ligas de alumínio com alta precisão. O melhor método, baseado em árvores altamente randomizadas, mantém os erros baixos mesmo quando os espectros são ruidosos e a química é complexa. O trabalho também enfatiza que bons resultados dependem não apenas de algoritmos inteligentes, mas também de um conjunto de treinamento variado. Com bibliotecas mais ricas de amostras conhecidas, essa abordagem combinada pode se tornar uma forma prática e escalável para fábricas e recicladores verificarem a qualidade do metal em tempo real.
Citação: Capella, A.G., López, M.M., de Damborenea González, J.J. et al. Machine learning for quantitative LIBS analysis of aluminum alloys: a comparison of random forest, gradient boosting, and extremely randomized trees. Sci Rep 16, 14758 (2026). https://doi.org/10.1038/s41598-026-46449-2
Palavras-chave: espectroscopia por plasma induzido por laser, aprendizado de máquina, ligas de alumínio, random forest, análise espectral