Clear Sky Science · en
Machine learning for quantitative LIBS analysis of aluminum alloys: a comparison of random forest, gradient boosting, and extremely randomized trees
Why this matters for everyday metal use
From airplanes and cars to beverage cans and phone cases, aluminum alloys are everywhere. Their performance depends on getting the mix of ingredients just right, but checking that mix quickly and accurately is not easy. This study shows how combining a fast laser test with modern machine learning can give precise readings of what is inside aluminum alloys, which could help industry recycle better, cut waste, and improve product safety.
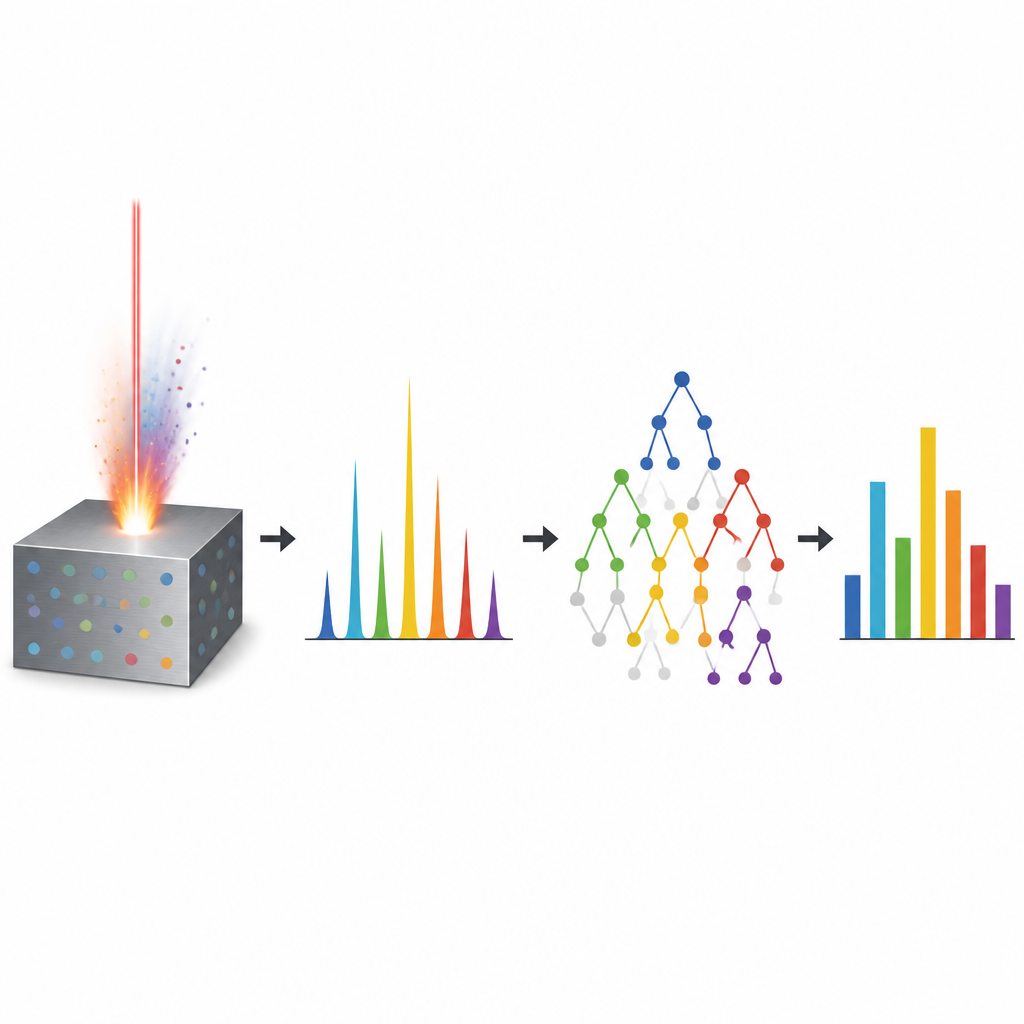
A laser that reads what metal is made of
The work centers on a technique called laser induced breakdown spectroscopy, or LIBS. In simple terms, a short, intense laser pulse hits a metal surface and blasts a tiny amount of material into a glowing cloud. As this cloud cools, it shines with colors that depend on which elements are present. A spectrometer records this colorful fingerprint across many wavelengths. LIBS is attractive because it works quickly, needs almost no sample preparation, and can be used on site. However, turning those complex light patterns into accurate numbers for each element, such as copper, zinc, or magnesium, is difficult. Effects like self absorption of light, overlapping lines from different elements, and changes in the hot cloud from shot to shot all make the relationship between color and composition strongly non linear.
Letting algorithms learn from many spectra
To tackle this problem, the authors turned to machine learning, where computers learn patterns from data rather than following fixed formulas. They collected 500 LIBS spectra from certified aluminum samples, including commercially pure aluminum and alloys with copper and zinc in various amounts. Each spectrum was carefully smoothed, interpolated over a wide color range, and normalized so that the full pattern, not just a few peaks, could be fed into the algorithms. Instead of handpicking features, the models received about six thousand intensity values per spectrum, allowing them to discover subtle hints of minor elements hidden in the glow.
Three tree based models face off
The team compared three related machine learning methods that all build large groups of decision trees: Random Forest, Gradient Boosting, and Extremely Randomized Trees. These methods split the data again and again into branches that eventually lead to a predicted composition. By combining many such trees, they can handle complex and noisy relationships. The researchers trained the models on most of the spectra and kept some aside for testing. They then checked how well each method could predict the known amounts of aluminum, copper, zinc, magnesium, iron, and silicon. All three reached high accuracy, with average errors well below a quarter of a percent by weight. Among them, the Extremely Randomized Trees model performed best overall, giving the lowest errors and highest agreement with reference values, especially for binary and ternary alloys where several elements interact.
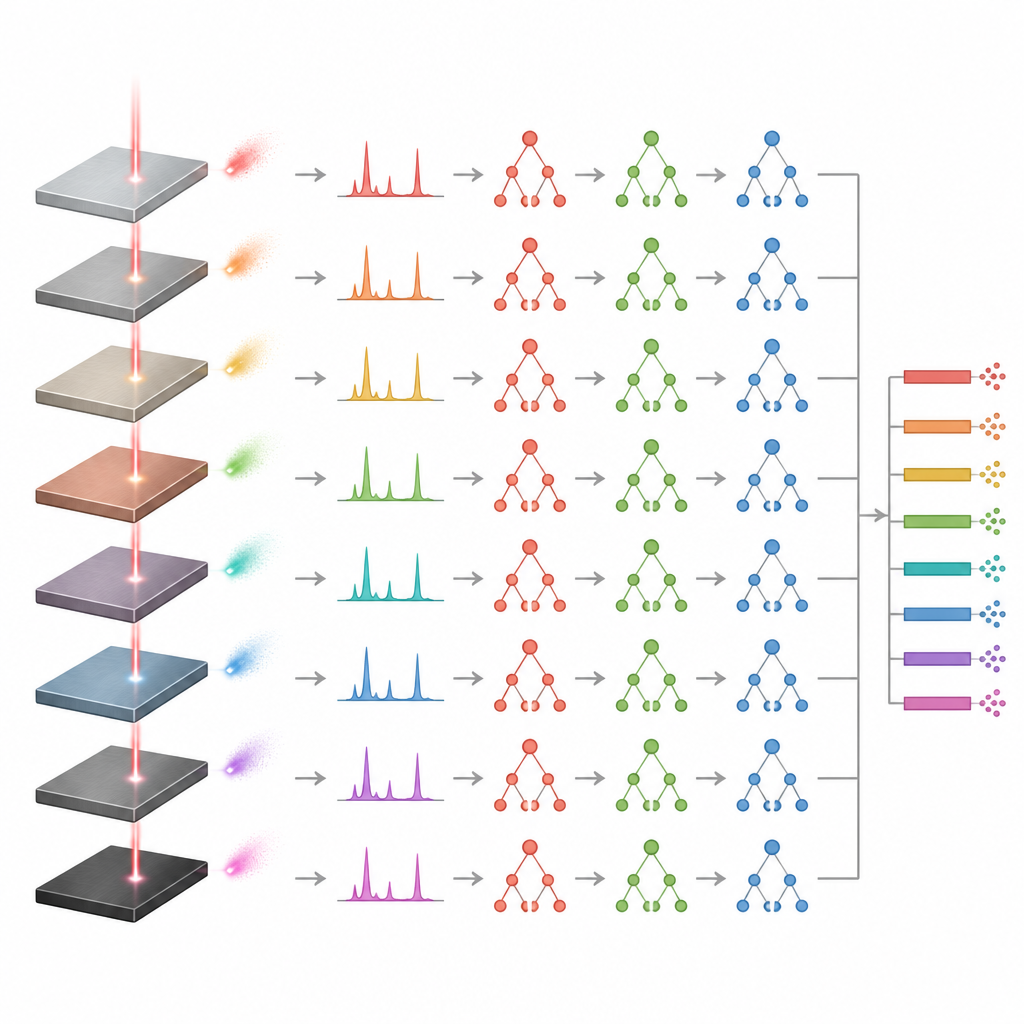
Testing real samples and limits
To see whether the models truly generalized rather than memorizing, the authors tested them on independent samples that had not been used during training. The predictions for these new alloys remained close to the certified compositions, confirming that the models could handle unseen cases. The Extremely Randomized Trees approach again showed the most stable behavior, while Gradient Boosting produced more variable results, which sometimes looked statistically acceptable only because of that higher spread. The study also found an important practical limit: when the training data contained only one sample from a given alloy family, predictions became unreliable. At least three representative samples per family were needed for the models to learn the range of possible compositions.
What the study means in simple terms
In essence, this paper shows that a fast laser based test, when paired with well chosen machine learning tools, can read the recipe of aluminum alloys with high precision. The best method, based on highly randomized trees, keeps errors small even when the spectra are noisy and the chemistry is complex. The work also stresses that good results depend not only on clever algorithms but also on having a varied training set. With richer libraries of known samples, this combined approach could become a practical, scalable way for factories and recyclers to check metal quality in real time.
Citation: Capella, A.G., López, M.M., de Damborenea González, J.J. et al. Machine learning for quantitative LIBS analysis of aluminum alloys: a comparison of random forest, gradient boosting, and extremely randomized trees. Sci Rep 16, 14758 (2026). https://doi.org/10.1038/s41598-026-46449-2
Keywords: laser induced breakdown spectroscopy, machine learning, aluminum alloys, random forest, spectral analysis