Clear Sky Science · de
Maschinelles Lernen für die quantitative LIBS-Analyse von Aluminiumlegierungen: ein Vergleich von Random Forest, Gradient Boosting und Extremely Randomized Trees
Warum das für den täglichen Einsatz von Metallen wichtig ist
Von Flugzeugen und Autos bis zu Getränkedosen und Handyhüllen sind Aluminiumlegierungen allgegenwärtig. Ihre Leistungsfähigkeit hängt davon ab, die Zusammensetzung genau abzustimmen, doch eine schnelle und präzise Kontrolle dieser Mischung ist nicht einfach. Diese Studie zeigt, wie die Kombination eines schnellen Lasertests mit modernen Machine-Learning-Methoden präzise Auskünfte über den Inhalt von Aluminiumlegierungen liefern kann, was Industrie und Recycling helfen, Abfall zu reduzieren und Produktsicherheit zu verbessern.
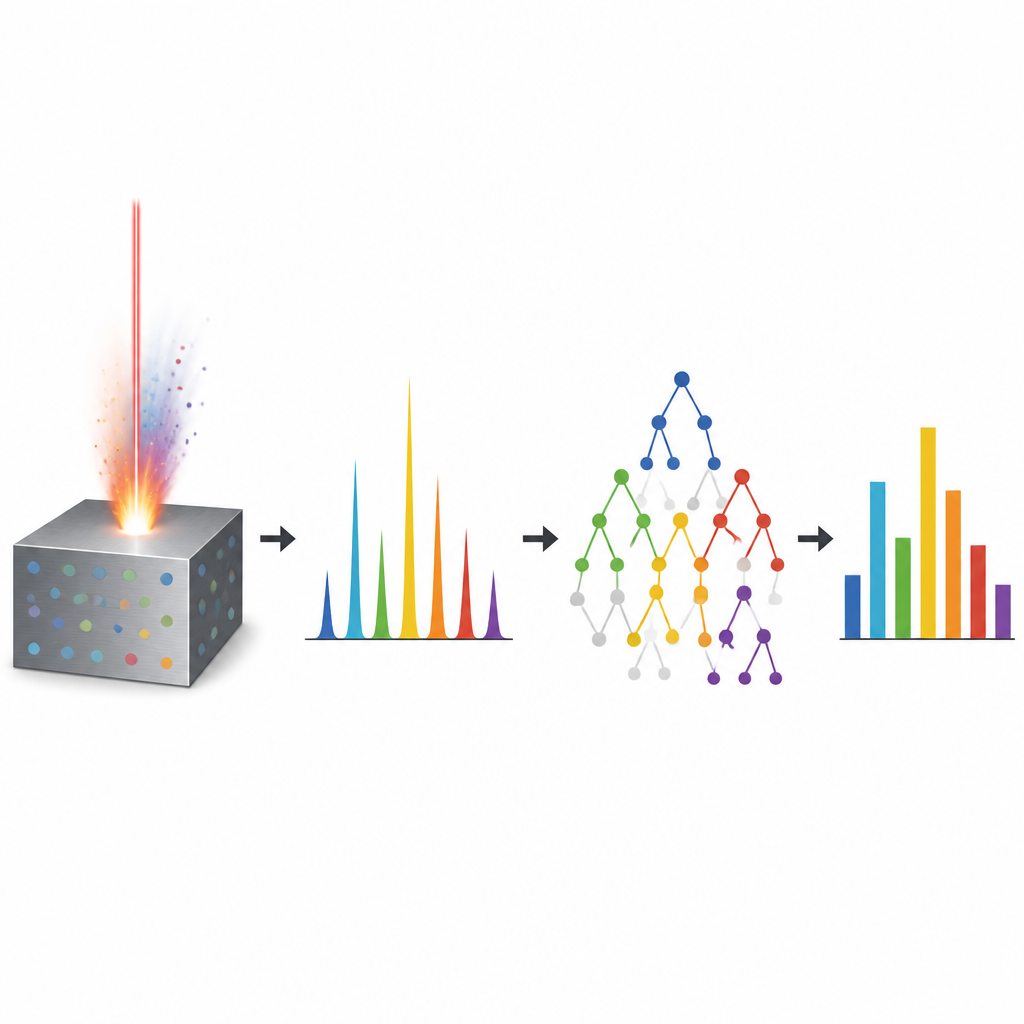
Ein Laser, der liest, woraus Metall besteht
Die Arbeit konzentriert sich auf eine Technik namens laserinduzierte Plasmaspektroskopie, kurz LIBS. Einfach gesagt trifft ein kurzer, intensiver Laserimpuls auf eine Metalloberfläche und verdampft einen winzigen Teil des Materials zu einer leuchtenden Wolke. Während diese Wolke abkühlt, strahlt sie in Farben, die von den vorhandenen Elementen abhängen. Ein Spektrometer zeichnet diesen bunten Fingerabdruck über viele Wellenlängen auf. LIBS ist attraktiv, weil es schnell arbeitet, kaum Probenvorbereitung braucht und vor Ort einsetzbar ist. Allerdings ist es schwierig, diese komplexen Lichtmuster in genaue Mengenangaben für einzelne Elemente wie Kupfer, Zink oder Magnesium zu übersetzen. Effekte wie Selbstabsorption, sich überlappende Linien verschiedener Elemente und Schwankungen in der heißen Wolke von Schuss zu Schuss machen die Beziehung zwischen Farbe und Zusammensetzung stark nichtlinear.
Algorithmen lernen aus vielen Spektren
Um dieses Problem anzugehen, griffen die Autoren auf maschinelles Lernen zurück, bei dem Computer Muster aus Daten lernen statt festen Formeln zu folgen. Sie sammelten 500 LIBS-Spektren von zertifizierten Aluminiumproben, darunter kommerziell reines Aluminium und Legierungen mit unterschiedlichen Anteilen an Kupfer und Zink. Jedes Spektrum wurde sorgfältig geglättet, über einen breiten Farbbereich interpoliert und normalisiert, sodass das vollständige Muster, nicht nur wenige Peaks, in die Algorithmen eingegeben werden konnte. Statt Merkmale manuell auszuwählen, erhielten die Modelle etwa sechstausend Intensitätswerte pro Spektrum, wodurch sie subtile Hinweise auf Spurenelemente im Leuchten entdecken konnten.
Drei baumbasierte Modelle treten gegeneinander an
Das Team verglich drei verwandte Machine-Learning-Methoden, die alle große Ensembles von Entscheidungsbäumen aufbauen: Random Forest, Gradient Boosting und Extremely Randomized Trees. Diese Methoden teilen die Daten immer wieder in Verzweigungen auf, die schließlich zu einer vorhergesagten Zusammensetzung führen. Durch die Kombination vieler solcher Bäume können sie komplexe und verrauschte Zusammenhänge handhaben. Die Forschenden trainierten die Modelle mit dem Großteil der Spektren und hielten einige zur Prüfung zurück. Anschließend überprüften sie, wie gut jede Methode die bekannten Anteile von Aluminium, Kupfer, Zink, Magnesium, Eisen und Silizium vorhersagen konnte. Alle drei erreichten hohe Genauigkeit, mit mittleren Fehlern deutlich unter einem Viertel Gewichtsprozent. Am besten schnitt das Extremely Randomized Trees-Modell ab, das insgesamt die niedrigsten Fehler und die höchste Übereinstimmung mit den Referenzwerten zeigte, besonders bei binären und ternären Legierungen, in denen mehrere Elemente miteinander interagieren.
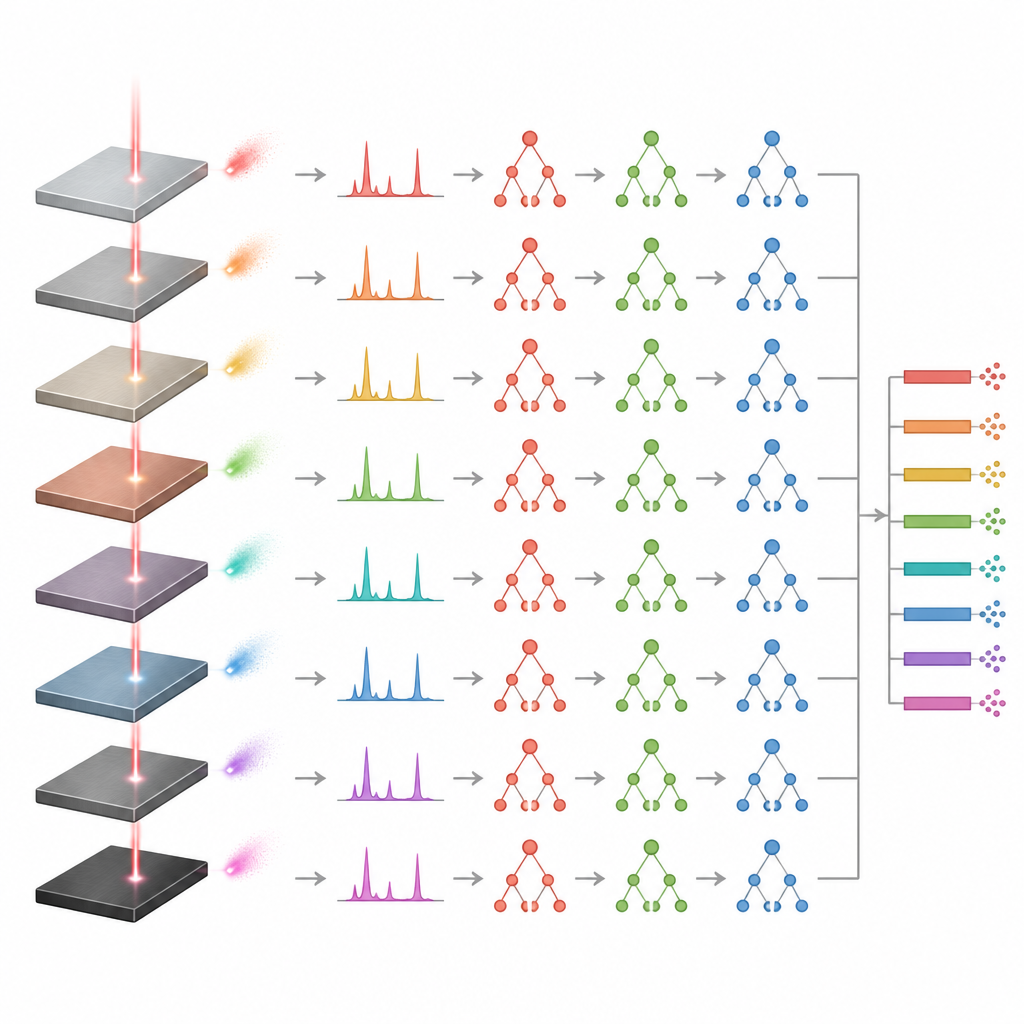
Prüfung an realen Proben und Grenzen
Um zu prüfen, ob die Modelle wirklich generalisieren und nicht nur auswendig gelernt haben, testeten die Autoren sie an unabhängigen Proben, die beim Training nicht verwendet wurden. Die Vorhersagen für diese neuen Legierungen lagen nahe an den zertifizierten Zusammensetzungen, was bestätigt, dass die Modelle mit bisher ungesehenen Fällen umgehen können. Der Ansatz mit Extremely Randomized Trees zeigte erneut das stabilste Verhalten, während Gradient Boosting variablere Ergebnisse lieferte, die manchmal nur aufgrund dieser größeren Streuung statistisch akzeptabel wirkten. Die Studie identifizierte außerdem eine praktische Grenze: Wenn die Trainingsdaten nur eine Probe aus einer bestimmten Legierungsfamilie enthielten, wurden die Vorhersagen unzuverlässig. Mindestens drei repräsentative Proben pro Familie waren nötig, damit die Modelle den möglichen Kompositionsbereich erlernen konnten.
Was die Studie einfach ausgedrückt bedeutet
Kernaussage: Ein schneller Lasertest kombiniert mit passenden Machine-Learning-Werkzeugen kann die „Rezeptur" von Aluminiumlegierungen mit hoher Präzision lesen. Die beste Methode, basierend auf stark randomisierten Bäumen, hält die Fehler klein, selbst bei verrauschten Spektren und komplexer Chemie. Die Arbeit betont zudem, dass gute Ergebnisse nicht nur von cleveren Algorithmen abhängen, sondern auch von einer vielfältigen Trainingsmenge. Mit reichhaltigeren Bibliotheken bekannter Proben könnte dieser kombinierte Ansatz für Fabriken und Recycler zu einer praktischen, skalierbaren Möglichkeit werden, Metallqualität in Echtzeit zu prüfen.
Zitation: Capella, A.G., López, M.M., de Damborenea González, J.J. et al. Machine learning for quantitative LIBS analysis of aluminum alloys: a comparison of random forest, gradient boosting, and extremely randomized trees. Sci Rep 16, 14758 (2026). https://doi.org/10.1038/s41598-026-46449-2
Schlüsselwörter: laserinduzierte Plasmaspektroskopie, maschinelles Lernen, Aluminiumlegierungen, Random Forest, Spektralanalyse