Clear Sky Science · fr
Apprentissage automatique pour l’analyse quantitative LIBS des alliages d’aluminium : comparaison des forêts aléatoires, du gradient boosting et des arbres extrêmement randomisés
Pourquoi c’est important pour l’usage quotidien des métaux
Des avions et des voitures aux canettes de boisson et aux coques de téléphones, les alliages d’aluminium sont omniprésents. Leurs performances dépendent d’un dosage précis des composants, mais vérifier ce mélange rapidement et avec précision est difficile. Cette étude montre qu’en associant un test laser rapide à des méthodes modernes d’apprentissage automatique, on peut obtenir des lectures précises de la composition des alliages d’aluminium, ce qui pourrait aider l’industrie à mieux recycler, réduire les déchets et améliorer la sécurité des produits.
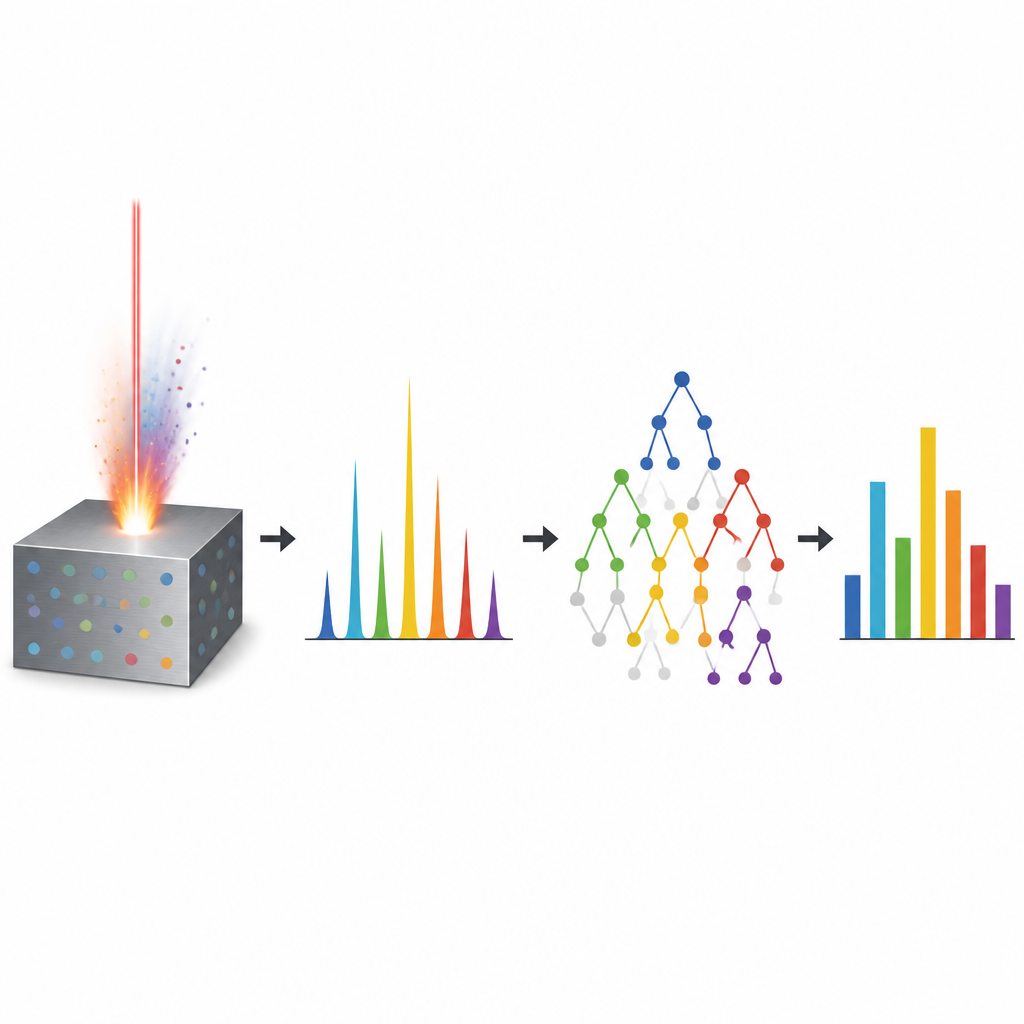
Un laser qui lit la composition d’un métal
Le travail porte sur une technique appelée spectroscopie d’ablation induite par laser, ou LIBS. En termes simples, une impulsion laser courte et intense frappe une surface métallique et vaporise une infime quantité de matière dans un nuage incandescant. En refroidissant, ce nuage émet des couleurs qui dépendent des éléments présents. Un spectromètre enregistre cette empreinte colorée sur de nombreuses longueurs d’onde. La LIBS est attractive car elle est rapide, nécessite presque aucune préparation d’échantillon et peut être utilisée sur site. Toutefois, transformer ces motifs lumineux complexes en concentrations précises pour chaque élément — cuivre, zinc, magnésium, etc. — est difficile. Des effets comme l’auto-absorption, le chevauchement des raies d’éléments différents et les variations du plasma d’un tir à l’autre rendent la relation entre couleur et composition fortement non linéaire.
Laisser les algorithmes apprendre à partir de nombreux spectres
Pour relever ce défi, les auteurs se sont tournés vers l’apprentissage automatique, où les ordinateurs apprennent des motifs à partir de données plutôt que d’appliquer des formules fixes. Ils ont collecté 500 spectres LIBS d’échantillons d’aluminium certifiés, incluant de l’aluminium commercial pur et des alliages contenant du cuivre et du zinc en différentes proportions. Chaque spectre a été soigneusement lissé, interpolé sur une large gamme spectrale et normalisé de sorte que le motif complet, et pas seulement quelques pics, soit utilisé par les algorithmes. Plutôt que de sélectionner des caractéristiques à la main, les modèles ont reçu environ six mille valeurs d’intensité par spectre, leur permettant de découvrir des indices subtils d’éléments mineurs cachés dans l’émission.
Trois modèles basés sur des arbres s’affrontent
L’équipe a comparé trois méthodes d’apprentissage apparentées qui construisent toutes de grands ensembles d’arbres de décision : la forêt aléatoire, le gradient boosting et les arbres extrêmement randomisés. Ces méthodes scindent les données à plusieurs reprises en branches qui aboutissent finalement à une composition prédite. En combinant de nombreux arbres, elles peuvent gérer des relations complexes et bruitées. Les chercheurs ont entraîné les modèles sur la majorité des spectres et en ont réservé quelques-uns pour les tests. Ils ont ensuite évalué la capacité de chaque méthode à prédire les quantités connues d’aluminium, cuivre, zinc, magnésium, fer et silicium. Les trois ont obtenu une grande précision, avec des erreurs moyennes bien inférieures à un quart de pour cent en poids. Parmi elles, le modèle d’arbres extrêmement randomisés a présenté la meilleure performance globale, affichant les erreurs les plus faibles et la meilleure concordance avec les valeurs de référence, en particulier pour les alliages binaires et ternaires où plusieurs éléments interagissent.
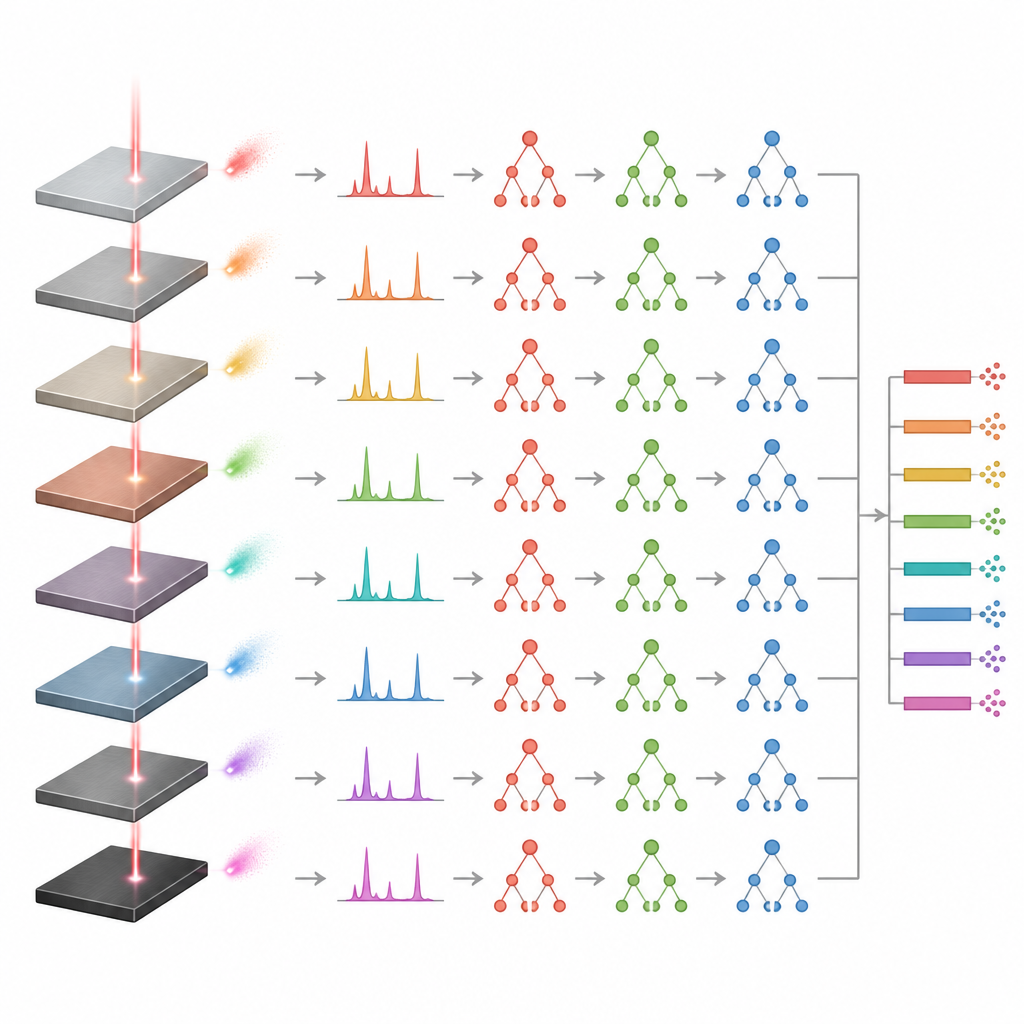
Tests sur échantillons réels et limites
Pour vérifier que les modèles généralisaient vraiment plutôt que de mémoriser, les auteurs les ont testés sur des échantillons indépendants non utilisés lors de l’entraînement. Les prédictions pour ces nouveaux alliages sont restées proches des compositions certifiées, confirmant que les modèles pouvaient traiter des cas non vus. L’approche des arbres extrêmement randomisés a de nouveau montré le comportement le plus stable, tandis que le gradient boosting a produit des résultats plus variables, parfois statistiquement acceptables en raison de cette plus grande dispersion. L’étude a aussi mis en évidence une limite pratique importante : lorsque l’ensemble d’entraînement comprenait un seul échantillon d’une même famille d’alliage, les prédictions devenaient peu fiables. Au moins trois échantillons représentatifs par famille étaient nécessaires pour que les modèles apprennent l’éventail des compositions possibles.
Ce que l’étude signifie en termes simples
En substance, cet article montre qu’un test laser rapide couplé à des outils d’apprentissage automatique bien choisis peut déterminer la recette des alliages d’aluminium avec une grande précision. La méthode la plus performante, basée sur des arbres fortement randomisés, maintient de faibles erreurs même lorsque les spectres sont bruyants et la chimie complexe. Les auteurs soulignent également que de bons résultats dépendent non seulement d’algorithmes performants, mais aussi d’un jeu d’entraînement varié. Avec des bibliothèques plus riches d’échantillons connus, cette approche combinée pourrait devenir un moyen pratique et évolutif pour les usines et les centres de recyclage de contrôler la qualité des métaux en temps réel.
Citation: Capella, A.G., López, M.M., de Damborenea González, J.J. et al. Machine learning for quantitative LIBS analysis of aluminum alloys: a comparison of random forest, gradient boosting, and extremely randomized trees. Sci Rep 16, 14758 (2026). https://doi.org/10.1038/s41598-026-46449-2
Mots-clés: spectroscopie d’ablation induite par laser, apprentissage automatique, alliages d’aluminium, forêt aléatoire, analyse spectrale