Clear Sky Science · nl
Machine learning voor kwantitatieve LIBS-analyse van aluminiumlegeringen: een vergelijking van random forest, gradient boosting en extreem gerandomiseerde bomen
Waarom dit belangrijk is voor alledaags metaalgebruik
Van vliegtuigen en auto’s tot frisdrankblikjes en telefoonbehuizingen: aluminiumlegeringen zijn overal. Hun prestaties hangen af van de juiste samenstelling, maar die samenstelling snel en nauwkeurig controleren is niet eenvoudig. Deze studie toont aan dat het combineren van een snelle lasertest met moderne machine learning nauwkeurige uitslagen kan geven over wat er in aluminiumlegeringen zit, wat de industrie kan helpen beter te recyclen, afval te verminderen en productveiligheid te verbeteren.
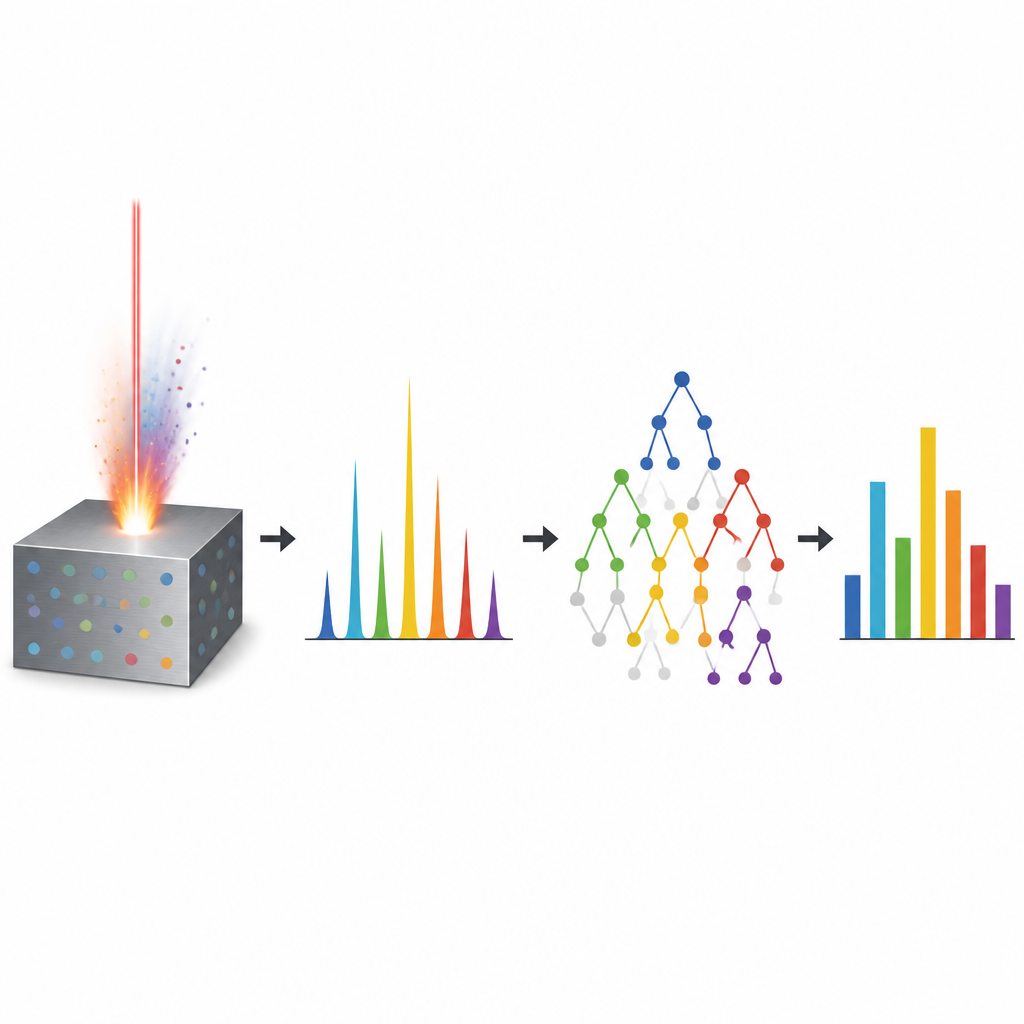
Een laser die leest waar metaal uit bestaat
Het werk draait om een techniek die laser induced breakdown spectroscopy, of LIBS, heet. Simpel gezegd raakt een korte, intense laserpuls een metalen oppervlak en blaast een kleine hoeveelheid materiaal in een gloedwolk. Terwijl die wolk afkoelt, straalt ze kleuren die afhangen van welke elementen aanwezig zijn. Een spectrometer registreert dit kleurrijke vingerafdrukje over veel golflengten. LIBS is aantrekkelijk omdat het snel werkt, bijna geen preparatie van het monster vereist en ter plaatse toepasbaar is. Toch is het lastig om die complexe lichtpatronen om te zetten in nauwkeurige hoeveelheden voor elk element, zoals koper, zink of magnesium. Effecten zoals zelfabsorptie van licht, overlappende lijnen van verschillende elementen en variaties in de hete wolk van schot tot schot maken de relatie tussen kleur en samenstelling sterk niet-lineair.
Algoritmes laten leren van veel spectra
Om dit probleem aan te pakken, keken de auteurs naar machine learning, waarbij computers patronen uit data leren in plaats van vaste formules te volgen. Ze verzamelden 500 LIBS-spectra van gecertificeerde aluminiummonsters, waaronder commercieel zuiver aluminium en legeringen met koper en zink in uiteenlopende hoeveelheden. Elk spectrum werd zorgvuldig gesmeerd, geïnterpoleerd over een breed kleurgebied en genormaliseerd zodat het volledige patroon, en niet slechts een paar pieken, aan de algoritmes kon worden gevoed. In plaats van handmatig kenmerken te kiezen, kregen de modellen ongeveer zesduizend intensiteitswaarden per spectrum, waardoor ze subtiele aanwijzingen van spoorelementen in de gloed konden ontdekken.
Drie boomgebaseerde modellen gaan de confrontatie aan
Het team vergeleek drie aan elkaar verwante machine learning-methoden die allemaal grote ensembles van beslisbomen bouwen: Random Forest, Gradient Boosting en Extremely Randomized Trees. Deze methoden splitsen de data telkens opnieuw in takken die uiteindelijk leiden tot een voorspelde samenstelling. Door veel van zulke bomen te combineren kunnen ze complexe en lawaaierige relaties aan. De onderzoekers trainden de modellen op het grootste deel van de spectra en hielden een deel apart voor testen. Daarna Controleerden ze hoe goed elke methode de bekende hoeveelheden aluminium, koper, zink, magnesium, ijzer en silicium kon voorspellen. Alle drie bereikten ze hoge nauwkeurigheid, met gemiddelde fouten ruim onder een kwart procent per gewicht. De Extremely Randomized Trees-prestatie was overall het beste: de laagste fouten en de hoogste overeenstemming met referentiewaarden, vooral bij binare en ternare legeringen waar meerdere elementen op elkaar inwerken.
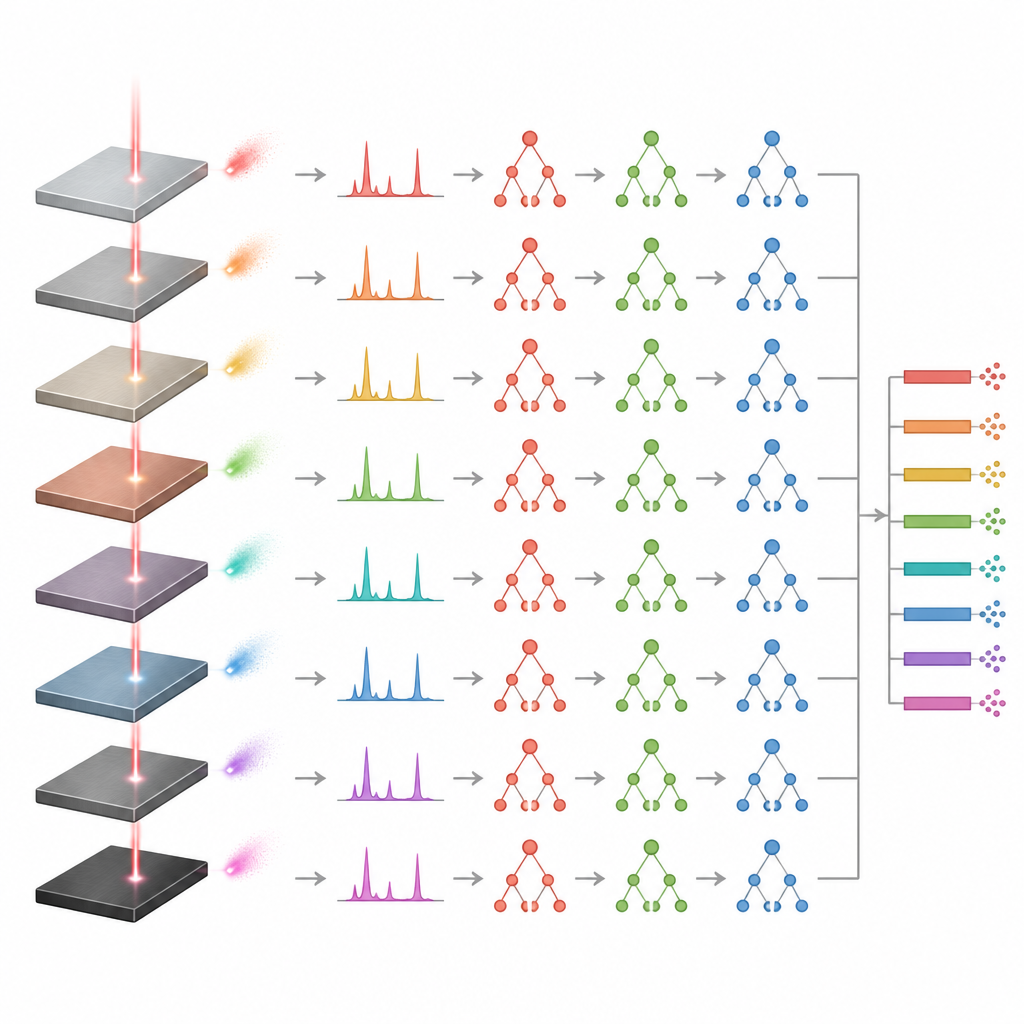
Testen met echte monsters en grenzen
Om te bekijken of de modellen echt generaliseerden in plaats van te memoriseren, testten de auteurs ze op onafhankelijke monsters die niet tijdens de training waren gebruikt. De voorspellingen voor deze nieuwe legeringen bleven dicht bij de gecertificeerde samenstellingen, wat bevestigt dat de modellen ongeziene gevallen aankunnen. De Extremely Randomized Trees-benadering toonde opnieuw het meest stabiele gedrag, terwijl Gradient Boosting meer variabele resultaten gaf, die soms statistisch acceptabel leken alleen door die grotere spreiding. De studie vond ook een belangrijke praktische limiet: wanneer de trainingsdata slechts één monster uit een bepaalde legeringsfamilie bevatte, werden voorspellingen onbetrouwbaar. Minimaal drie representatieve monsters per familie waren nodig zodat de modellen het bereik van mogelijke samenstellingen konden leren.
Wat de studie in eenvoudige termen betekent
Kort gezegd toont dit artikel aan dat een snelle lasergestuurde test, gecombineerd met goed gekozen machine learning-tools, het recept van aluminiumlegeringen met hoge precisie kan bepalen. De beste methode, gebaseerd op sterk gerandomiseerde bomen, houdt de fouten klein zelfs wanneer de spectra ruis bevatten en de chemie complex is. Het werk benadrukt ook dat goede resultaten niet alleen afhangen van slimme algoritmes maar ook van een gevarieerde trainingsset. Met rijkere bibliotheken van bekende monsters zou deze gecombineerde aanpak een praktische, schaalbare manier kunnen worden voor fabrieken en recyclingbedrijven om metaalkwaliteit realtime te controleren.
Bronvermelding: Capella, A.G., López, M.M., de Damborenea González, J.J. et al. Machine learning for quantitative LIBS analysis of aluminum alloys: a comparison of random forest, gradient boosting, and extremely randomized trees. Sci Rep 16, 14758 (2026). https://doi.org/10.1038/s41598-026-46449-2
Trefwoorden: laser induced breakdown spectroscopy, machine learning, aluminiumlegeringen, random forest, spectrale analyse