Clear Sky Science · pt
Um sistema algorítmico para detecção de notícias falsas em árabe usando redes neurais e embeddings de transformers com ponderação de classes
Por que identificar histórias falsas online importa
No mundo sempre conectado de hoje, uma manchete dramática em árabe pode viajar de uma página pouco conhecida no Facebook para milhões de telefones em minutos. Algumas dessas histórias são falsificações cuidadosamente elaboradas que podem inflamar a opinião pública, distorcer eleições ou semear desconfiança nas instituições. Ainda assim, a maioria das ferramentas automáticas para identificar notícias falsas foi desenvolvida para o inglês. Este estudo enfrenta essa lacuna ao projetar e testar um sistema eficiente capaz de sinalizar artigos de notícias em árabe enganosos com um nível de precisão próximo ao de verificadores humanos.
Construindo um retrato realista das notícias em árabe
Para espelhar a realidade confusa da informação online, os pesquisadores primeiro reuniram uma coleção grande e mista de 7.474 artigos de notícias em árabe publicados entre 2015 e 2025. Os textos vieram de redações confiáveis, blogs e postagens de redes sociais não verificadas e amostras traduzidas de conjuntos de dados de notícias falsas bem conhecidos em inglês. Cada item foi rotulado como verdadeiro ou falso, usando checagens cuidadosas contra fontes oficiais e plataformas árabes de verificação de fatos. Um subconjunto foi verificado por três especialistas, e o forte acordo entre eles deu confiança de que os rótulos eram confiáveis. O conjunto de dados final reflete como histórias falsas são, na prática, menos numerosas que reportagens genuínas — um desbalanceamento de classes que costuma prejudicar detectores automáticos.
Ensinando máquinas a realmente ler o árabe
Em vez de depender de contagens simples de palavras, a equipe recorreu a uma família moderna de modelos de linguagem chamados Transformers, capazes de capturar significado a partir do contexto. Usaram um modelo árabe conhecido como CAMeLBERT, treinado especificamente em Árabe Padrão Moderno, como uma espécie de leitor sofisticado. Cada artigo passou por um pipeline de pré‑processamento especializado que remove emojis, links e caracteres ruidosos, preservando as nuances linguísticas importantes no árabe. O CAMeLBERT então converteu cada artigo limpo em uma impressão digital numérica densa que captura sutilezas de significado, estilo e estrutura. Essas impressões foram alimentadas em uma rede neural profunda compacta que aprende padrões que distinguem notícias verdadeiras de falsas.
Corrigindo o desbalanceamento entre verdadeiro e falso
Um desafio chave foi que artigos verdadeiros eram mais numerosos que os falsos no conjunto de dados, assim como ocorre na vida cotidiana. Se não for tratado, um modelo tende a jogar pelo seguro e classificar a maioria das histórias como verdadeiras, perdendo falsificações perigosas. Muitos estudos anteriores tentaram corrigir isso duplicando exemplos raros de falsas, inventando sintéticos ou descartando alguns artigos verdadeiros, mas esses truques podem adicionar ruído ou desperdiçar informação útil. Em vez disso, este trabalho focou em uma solução ao nível do algoritmo chamada ponderação de classes. Durante o treinamento, erros em artigos falsos passam a ser mais “custosos” para o modelo do que erros em artigos verdadeiros. Sem alterar os dados, isso faz a rede neural prestar atenção extra à classe minoritária de falsas e traçar uma fronteira mais equilibrada entre histórias verdadeiras e falsas.
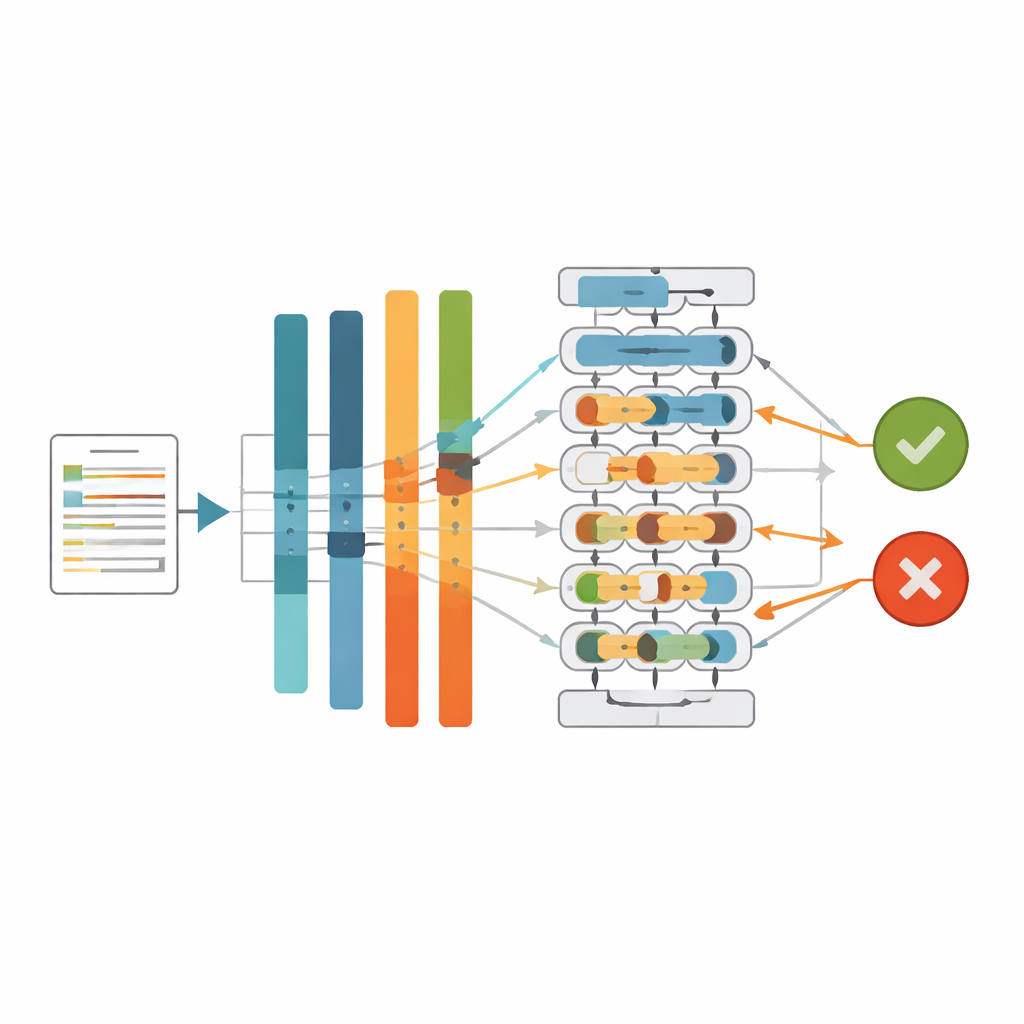
Colocando o sistema à prova
Os pesquisadores compararam várias abordagens: modelos tradicionais de aprendizado de máquina usando recursos de contagem de palavras, a mesma rede neural alimentada por diferentes modelos Transformer em árabe e o melhor Transformer combinado com várias estratégias de balanceamento. O CAMeLBERT emergiu como a espinha dorsal mais forte entre os Transformers em árabe, superando alternativas como AraBERT, MARBERTv2 e AraELECTRA. Quando emparelhado com ponderação de classes, o sistema baseado em CAMeLBERT classificou corretamente notícias em árabe com uma precisão de cerca de 95,5% e uma pontuação F1 — um equilíbrio entre precisão e recall — de cerca de 96,2%. Tão importante quanto, o sistema ajustado reduziu acentuadamente o erro mais preocupante: histórias falsas tratadas incorretamente como verdadeiras. Para abrir a “caixa‑preta”, a equipe também aplicou ferramentas modernas de explicação (LIME e SHAP) que revelam quais pistas e padrões linguísticos nas representações internas do modelo tendem a empurrar um artigo na direção de uma decisão de falso ou verdadeiro.
O que isso significa para leitores cotidianos
Do ponto de vista do público em geral, este estudo mostra que máquinas podem ser treinadas para ler notícias em árabe de maneira surpreendentemente nuançada, identificando pistas estilísticas e contextuais sutis que frequentemente separam postagens fabricadas de reportagens profissionais. Ao combinar um modelo de linguagem voltado ao Árabe Padrão Moderno com uma estratégia de treinamento consciente da equidade, os autores entregam um detector que é ao mesmo tempo preciso e relativamente leve — adequado para integração em plataformas de verificação de fatos, redações e ferramentas de monitoramento de redes sociais. Embora não substitua o julgamento humano, esse sistema oferece uma base sólida para verificação automática de fatos em árabe, ajudando a frear a disseminação de desinformação prejudicial e a apoiar um espaço informacional mais saudável no mundo árabe.
Citação: Saad, M., Abdelrazek, S. & Abdelmaksoud, I.R. An algorithmic system for arabic fake news detection using neural networks and transformer embeddings with class weighting. Sci Rep 16, 12226 (2026). https://doi.org/10.1038/s41598-026-45653-4
Palavras-chave: Notícias falsas em árabe, modelos transformer, redes neurais, desbalanceamento de classes, sistemas de verificação de fatos