Clear Sky Science · ja
クラス重み付けを用いたニューラルネットワークとトランスフォーマー埋め込みによるアラビア語フェイクニュース検出のアルゴリズムシステム
なぜオンライン上の偽情報を見抜くことが重要か
常時接続された現代では、アラビア語の衝撃的な見出しが、無名のFacebookページから数分で何百万もの携帯電話に広がることがあります。こうした記事の中には世論を扇動し、選挙を歪め、制度への不信をまき散らすように巧妙に作られた偽情報が含まれることがあります。しかし、偽ニュース検出の自動化ツールの多くは英語向けに構築されています。本研究はそのギャップに取り組み、誤導的なアラビア語のニュース記事を人間のファクトチェッカーに近い精度でフラグ付けできる効率的なシステムを設計・検証しました。
アラビア語ニュースの現実的な姿を構築する
オンライン情報の混沌とした現実を反映するために、研究者らはまず2015年から2025年に公開された7,474件のアラビア語ニュース記事からなる大規模で混合されたコレクションを作成しました。テキストは信頼できる報道機関、未検証のブログやソーシャルメディア投稿、著名な英語フェイクニュースデータセットから翻訳されたサンプルなどから収集されました。各項目は公式情報源やアラビア語のファクトチェックプラットフォームによる慎重な照合を経て真偽のラベルが付けられました。サブセットは3人の専門家によって再確認され、彼らの高い一致度はラベルの信頼性を裏付けました。最終データセットは、実際に偽記事が真の記事より少数であるという現象、つまり自動検出器をしばしばつまずかせるクラス不均衡を反映しています。
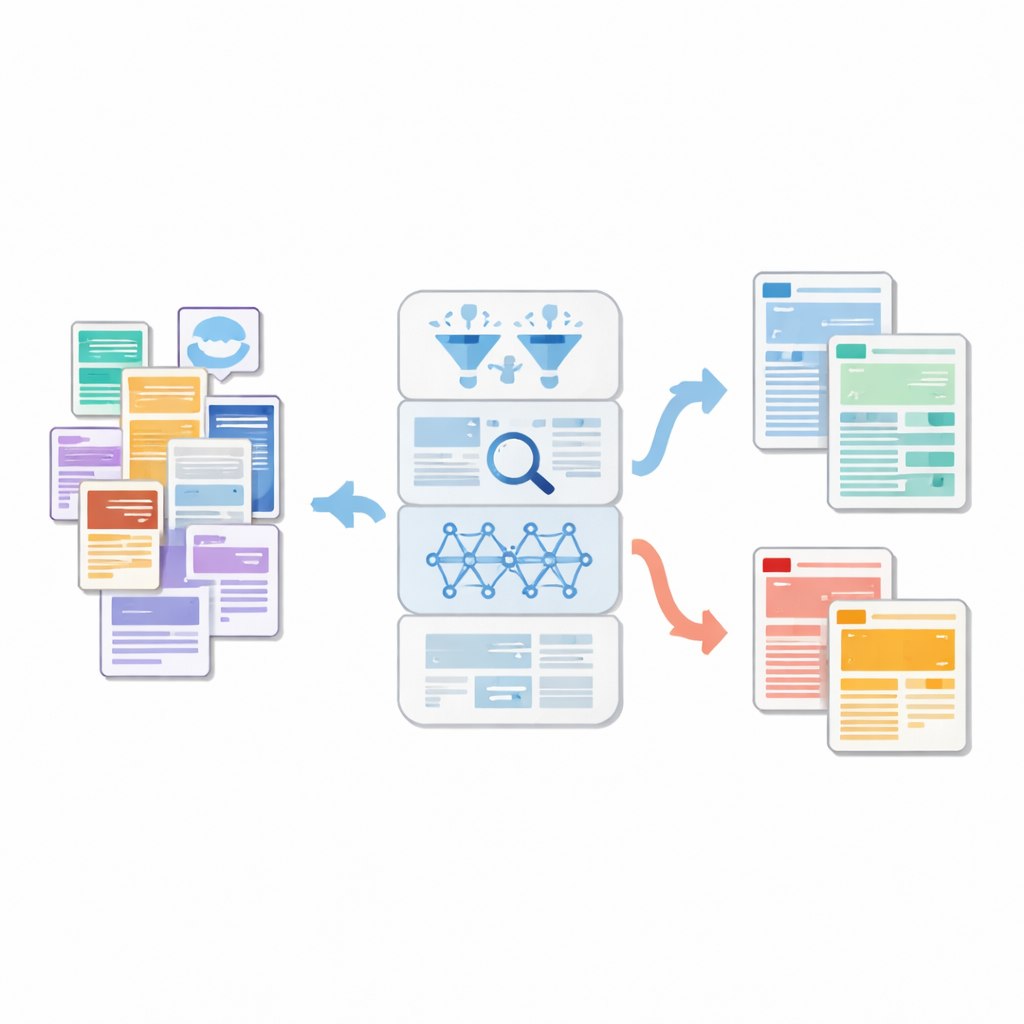
機械にアラビア語を“本当に読む”ことを教える
単純な語の頻度に頼る代わりに、研究チームはコンテキストから意味を捉える最新の言語モデル群であるトランスフォーマーに着目しました。彼らは標準アラビア語(モダンスタンダードアラビック)向けに特化して訓練されたCAMeLBERTというアラビア語モデルを洗練された読者のように利用しました。各記事は絵文字、リンク、ノイズの多い文字を取り除きつつアラビア語の重要な言語的ニュアンスを保存する専用の前処理パイプラインを通されました。CAMeLBERTは各クリーンな記事を意味や文体、構造の微妙な差異をとらえる密な数値的フィンガープリントに変換しました。これらのフィンガープリントは、本物と偽物を識別するパターンを学習する小型の深層ニューラルネットワークに入力されました。
真記事と偽記事の不均衡を解決する
主要な課題は、データセット内で真記事が偽記事より多いことでした。日常でも同様です。そのままにしておくと、モデルは無難な判断をしてほとんどの記事を真と分類し、危険な偽を見逃してしまいます。以前の多くの研究は稀な偽の例を複製したり、合成例を作ったり、一部の真記事を捨てたりしてこれを補おうとしましたが、これらのトリックはノイズを増やしたり有用な情報を失わせたりします。代わりに本研究はアルゴリズムレベルの解決策であるクラス重み付けに注目しました。訓練中に偽記事での誤りが真記事での誤りよりもモデルにとって「高いコスト」となるように設定します。データ自体を変更せずにこれを行うことで、ニューラルネットワークは少数派である偽クラスにより注意を払い、真偽の境界をよりバランスよく引くようになります。
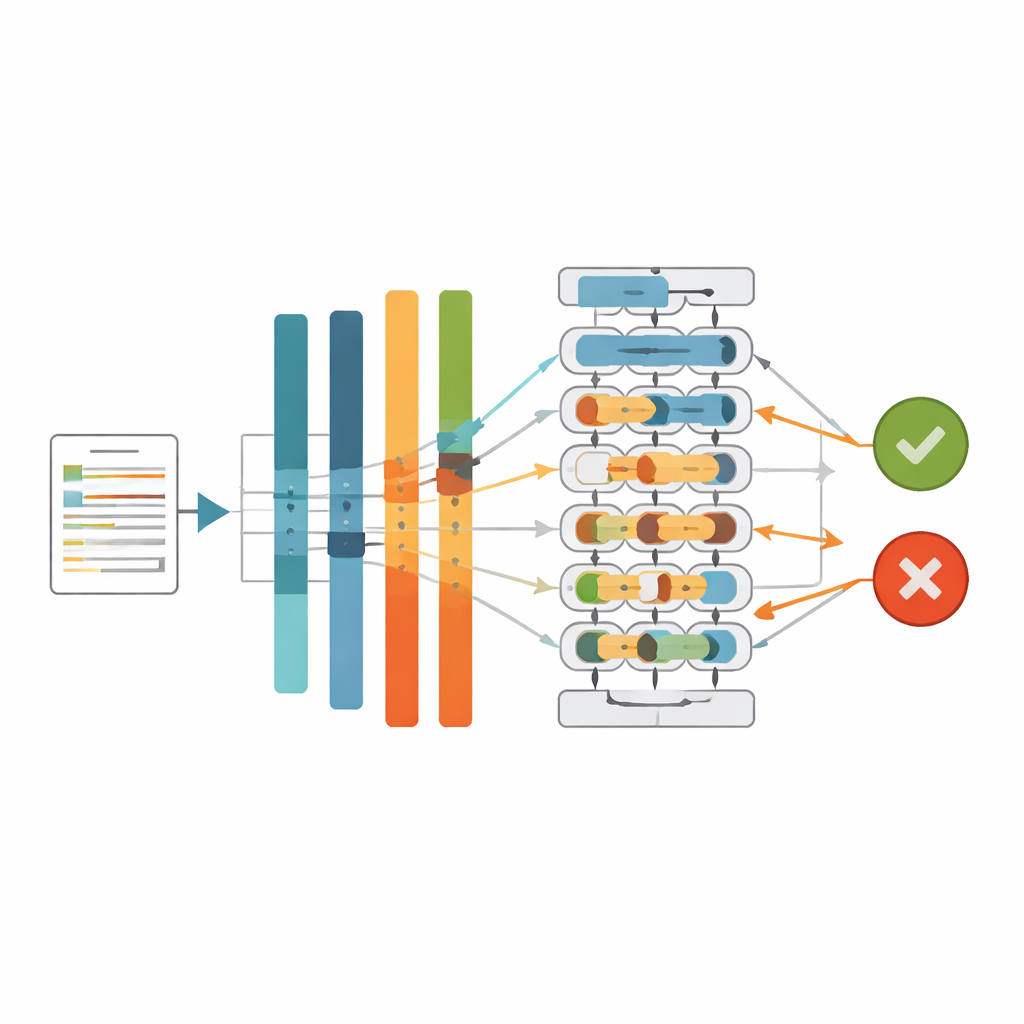
システムを実地で検証する
研究者らは複数のアプローチを比較しました:語頻度特徴を使った従来の機械学習モデル、異なるアラビア語トランスフォーマーモデルから供給された同じニューラルネットワーク、そしてさまざまなバランス調整戦略と組み合わせた最良のトランスフォーマー。CAMeLBERTはアラビア語トランスフォーマーの中で最も強力なバックボーンとして浮上し、AraBERT、MARBERTv2、AraELECTRAなどの代替手法を上回りました。クラス重み付けと組み合わせたとき、CAMeLBERTベースのシステムは約95.5%の精度と、適合率と再現率のバランスを示すF1スコアで約96.2%を達成しました。同じく重要なのは、調整されたシステムが最も憂慮すべき誤り、すなわち偽記事を誤って真と扱うケースを大幅に減らしたことです。「ブラックボックス」を可視化するために、研究チームはLIMEやSHAPといった現代的な説明ツールも適用し、モデルの内部表現におけるどの言語的手がかりやパターンが記事を偽または真の判断へ導く傾向があるかを明らかにしました。
一般読者にとっての意義
非専門家の視点から見ると、本研究は機械がアラビア語のニュースを驚くほどニュアンス豊かに読み取り、捏造された投稿と専門的な報道をしばしば分ける微妙な文体的・文脈的手がかりを見つけられるように訓練できることを示しています。モダンスタンダードアラビア語に特化した言語モデルと公正性を意識した学習戦略を組み合わせることで、著者らは精度が高く比較的軽量な検出器を提供しました。これはファクトチェックプラットフォーム、ニュースルーム、ソーシャルメディア監視ツールへの統合に適しています。人間の判断を置き換えるものではありませんが、このシステムはアラビア語の自動ファクトチェックの強固な基盤を提供し、有害な誤情報の拡散を緩和し、アラビア語話者圏における健全な情報環境を支援する手助けとなります。
引用: Saad, M., Abdelrazek, S. & Abdelmaksoud, I.R. An algorithmic system for arabic fake news detection using neural networks and transformer embeddings with class weighting. Sci Rep 16, 12226 (2026). https://doi.org/10.1038/s41598-026-45653-4
キーワード: アラビア語フェイクニュース, トランスフォーマーモデル, ニューラルネットワーク, クラス不均衡, ファクトチェックシステム