Clear Sky Science · pl
ChunkyBERT: nowa technika wykrywania wieloklasowego uprzedzenia politycznego w mediach informacyjnych
Dlaczego ukryte nastawienia w wiadomościach mają znaczenie
Codziennie ludzie przeglądają nagłówki polityczne, nie zdając sobie sprawy, jak dobór słów i wybór tematów może subtelnie kierować ich opiniami. W tym badaniu wprowadzono ChunkyBERT — model komputerowy zaprojektowany do wykrywania, czy długie artykuły informacyjne mają orientację lewicową, centrową czy prawicową, wykorzystując cały tekst zamiast kilku wybranych sygnałów. Celem jest pomóc czytelnikom, dziennikarzom i obserwatorom lepiej dostrzegać stronniczość we współczesnych mediach cyfrowych.
Jak polityczne nastawienie kształtuje to, co czytamy
Media informacyjne mogą wpływać na opinię nie tylko przez to, co mówią, ale też przez to, co pomijają, jak przedstawiają wydarzenia i jakich emocjonalnych zwrotów używają. W erze platform internetowych może to pogłębiać podziały, wzmacniać bańki informacyjne i rozprzestrzeniać mylące informacje. Wcześniejsze narzędzia komputerowe próbowały to mierzyć, licząc słowa pozytywne lub negatywne albo śledząc częstotliwość występowania określonych terminów. Choć pomocne, narzędzia te miały trudności z kontekstem, takim jak sarkazm czy subtelne ramowanie, i często wymagały dużej ręcznej konfiguracji przez ekspertów.
Od ręcznie konstruowanych wskazówek do czytania pełnego tekstu
Ostatnie postępy w technologii językowej pozwalają modelom uczyć się znaczeń bezpośrednio z surowego tekstu. Systemy oparte na sieciach neuronowych i transformerach, takie jak BERT, potrafią uchwycić, jak słowa wpływają na siebie w zdaniu i między akapitami. Wiele wcześniejszych badań używało tych narzędzi do wykrywania mowy nienawiści, fałszywych wiadomości czy analizy sentymentu, a niektóre próbowały oceniać orientację polityczną na podstawie krótkich nagłówków lub tweetów. Jednak długie artykuły polityczne pozostają wyzwaniem, ponieważ standardowe modele mają ograniczenia co do długości tekstu, który mogą przetworzyć jednorazowo, a oznaki stronniczości mogą być rozproszone po całym tekście, a nie zawarte w jednym mocnym cytacie.

Dzielenie długich artykułów na łatwiejsze kawałki
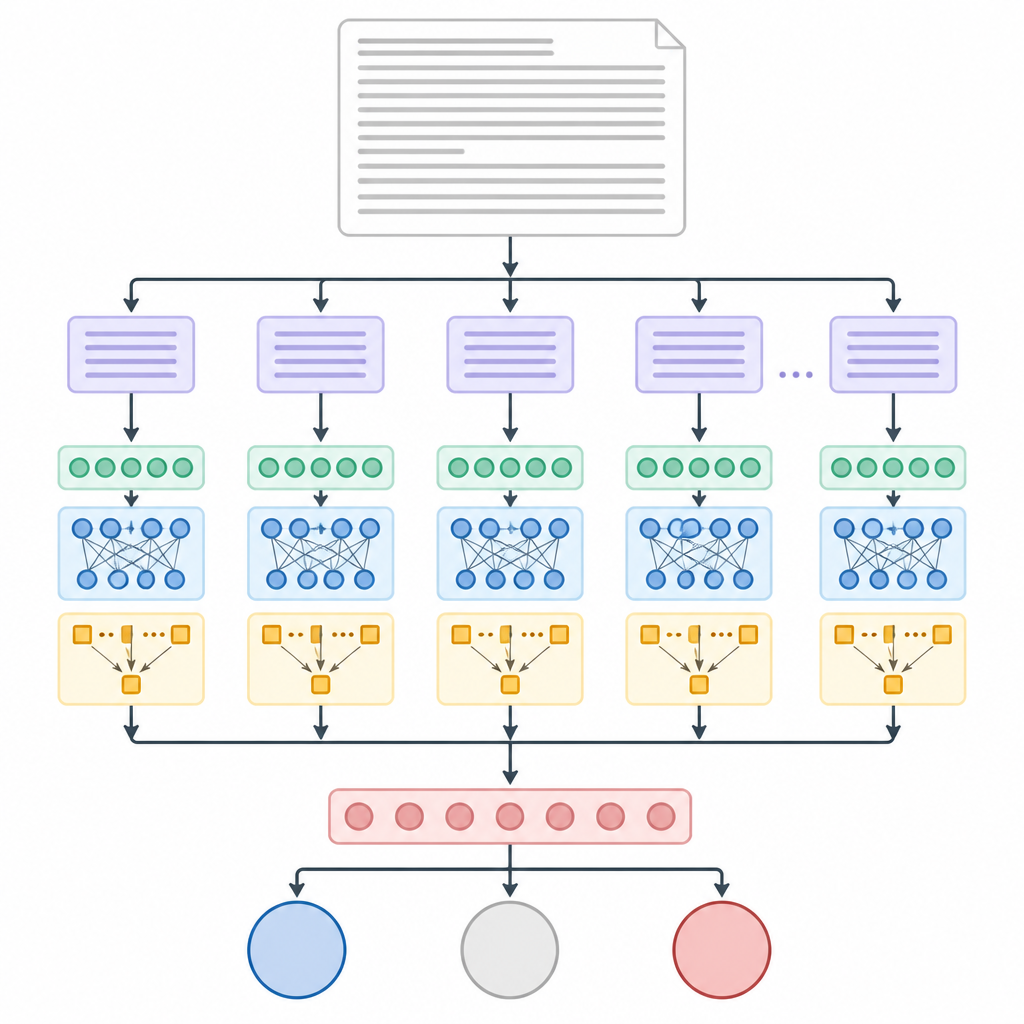
ChunkyBERT rozwiązuje ten problem, najpierw dzieląc każdy długi artykuł na mniejsze fragmenty o równej długości, zwane chunkami. Te fragmenty nie są dopasowane do zdań ani akapitów, co utrzymuje proces prostym i przewidywalnym dla komputera. Każdy chunk trafia następnie do wstępnie wytrenowanego modelu językowego, który przekształca słowa w wzorce liczbowe uchwycające ich znaczenie w kontekście. Druga warstwa transformera dopracowuje te wzorce, a mechanizm atencji pozwala systemowi dyskretnie wyróżnić słowa i zwroty, które wydają się najbardziej wymowne w określaniu orientacji politycznej, przy jednoczesnym przytłumieniu neutralnego tła.
Złożenie historii z powrotem
Gdy każdy chunk zostanie w ten sposób zreasumowany, ChunkyBERT uśrednia podsumowania chunków do pojedynczego ogólnego odcisku artykułu. Ten odcisk trafia następnie do końcowej warstwy decyzyjnej, która wybiera między lewicą, centrum a prawicą. Badacze trenowali i testowali system na ponad 37 000 artykułów informacyjnych z przypisanymi etykietami politycznymi, głównie ze źródeł z USA. Porównali ChunkyBERT z bardziej tradycyjnymi metodami uczenia maszynowego oraz z innymi modelami neuronowymi, w tym opartymi na sieciach rekurencyjnych i konwolucjach czasowych, zarówno z chunkowaniem i atencją, jak i bez nich.
Jak dobrze działa system
Eksperymenty wykazały, że ChunkyBERT klasyfikował artykuły z dokładnością na zbiorze walidacyjnym wynoszącą około 86 procent oraz uzyskał silny wynik w standardowej miarze separacji, sprawdzającej, jak dobrze rozróżnia klasy. Szczególnie dobrze radził sobie z wykrywaniem wyraźnie lewicowych lub prawicowych tekstów, podczas gdy artykuły centrowe bywały czasem mylone z jedną ze stron, co odzwierciedla ich bardziej mieszany ton. Badanie abla cyjne, w którym autorzy wyłączali części modelu, ujawniło, że zarówno dzielenie długich dokumentów na chunk, jak i warstwy transformera były kluczowe dla osiągnięcia wysokiej wydajności. System przewyższał też wcześniejsze metody wykrywania uprzedzeń testowane na tym samym zestawie danych.
Co to oznacza dla czytelników wiadomości
Mówiąc prosto, ChunkyBERT zachowuje się jak uważny, nieustający czytelnik, który skanuje całe polityczne relacje i ocenia, gdzie plasują się na spektrum politycznym. Nie usuwa uprzedzeń z wiadomości ani nie rozstrzyga, które poglądy są słuszne, ale może pomóc wykryć nastawienia, które w innym wypadku pozostałyby niezauważone. Po dopracowaniu i dostosowaniu do innych języków i regionów podobne narzędzia mogłyby wspierać monitoring mediów, dyskusje w klasie i platformy kształcące w zakresie umiejętności cyfrowych, dając ludziom jaśniejszy obraz tego, jak informacje są kształtowane, zanim trafią na ich ekrany.
Cytowanie: Loiya, D., Kulal, S.S., Reddy, M.S.M. et al. ChunkyBERT: a novel technique for multiclass political bias detection in news media. Sci Rep 16, 15323 (2026). https://doi.org/10.1038/s41598-026-46646-z
Słowa kluczowe: uprzedzenie w mediach politycznych, klasyfikacja wiadomości, modele transformerowe, BERT, czytelnictwo cyfrowe