Clear Sky Science · it
ChunkyBERT: una tecnica innovativa per la rilevazione multiclass di bias politico nei media
Perché gli orientamenti nascosti nelle notizie contano
Ogni giorno le persone scorrono titoli politici senza rendersi conto di come la scelta delle parole e delle storie possa silenziosamente orientare le loro opinioni. Questo studio introduce ChunkyBERT, un modello informatico progettato per individuare se lunghi articoli di cronaca politica tendono a sinistra, al centro o a destra, utilizzando il testo integrale anziché pochi segnali selezionati. L’obiettivo è aiutare lettori, giornalisti e organismi di controllo a vedere il bias in modo più chiaro nei media digitali contemporanei.
Come l’inclinazione politica plasma ciò che leggiamo
I media possono influenzare l’opinione non solo per ciò che dicono, ma anche per ciò che omettono, per come inquadrano gli eventi e per quali espressioni emotive scelgono. Nell’era delle piattaforme online questo può approfondire le divisioni, alimentare camere dell’eco e diffondere informazioni fuorvianti. Strumenti informatici precedenti cercavano di misurare questo fenomeno contando parole positive o negative o rintracciando la frequenza di certi termini. Pur essendo utili, questi strumenti faticano con il contesto, come il sarcasmo o i riquadri sottili, e spesso richiedono molta messa a punto manuale da parte di esperti.
Da indizi costruiti a lettura del testo integrale
I recenti progressi nelle tecnologie del linguaggio permettono ai modelli di apprendere il significato direttamente dal testo grezzo. Sistemi basati su reti neurali e transformer, come BERT, possono cogliere come le parole influenzano reciprocamente il significato in una frase e attraverso i paragrafi. Molti studi passati hanno usato questi strumenti per rilevare discorsi d’odio, fake news o sentiment, e alcuni hanno provato a stimare l’inclinazione politica da titoli brevi o tweet. Tuttavia, i lunghi articoli politici restano una sfida, perché i modelli standard hanno limiti sulla quantità di testo che possono leggere in una volta e perché i segnali di bias possono essere sparsi lungo il pezzo invece di trovarsi in una singola citazione incisiva.

Spezzare i lunghi articoli in pezzi più gestibili
ChunkyBERT affronta il problema tagliando ogni lungo articolo in pezzi più piccoli di uguale lunghezza, chiamati chunk. Questi chunk non sono allineati a frasi o paragrafi, il che mantiene il processo semplice e prevedibile per il computer. Ogni chunk viene quindi elaborato da un modello linguistico pre-addestrato che trasforma le parole in schemi numerici che catturano il loro significato nel contesto. Un secondo strato transformer affina questi schemi e un meccanismo di attenzione consente al sistema di mettere in evidenza silenziosamente le parole e le frasi più rivelatrici dell’orientamento politico, attenuando il testo neutro di sfondo.
Ricomporre la storia
Una volta che ogni chunk è stato così riassunto, ChunkyBERT calcola la media delle sintesi dei chunk in un’unica impronta complessiva per l’articolo. Questa impronta entra poi in un livello decisionale finale che sceglie tra sinistra, centro o destra. I ricercatori hanno addestrato e testato il sistema su oltre 37.000 articoli di notizie con etichette politiche note, per lo più da fonti statunitensi. Hanno confrontato ChunkyBERT con metodi di machine learning più tradizionali e con altri modelli neurali, inclusi quelli basati su reti ricorrenti e convoluzioni temporali, sia con che senza chunking e attenzione.
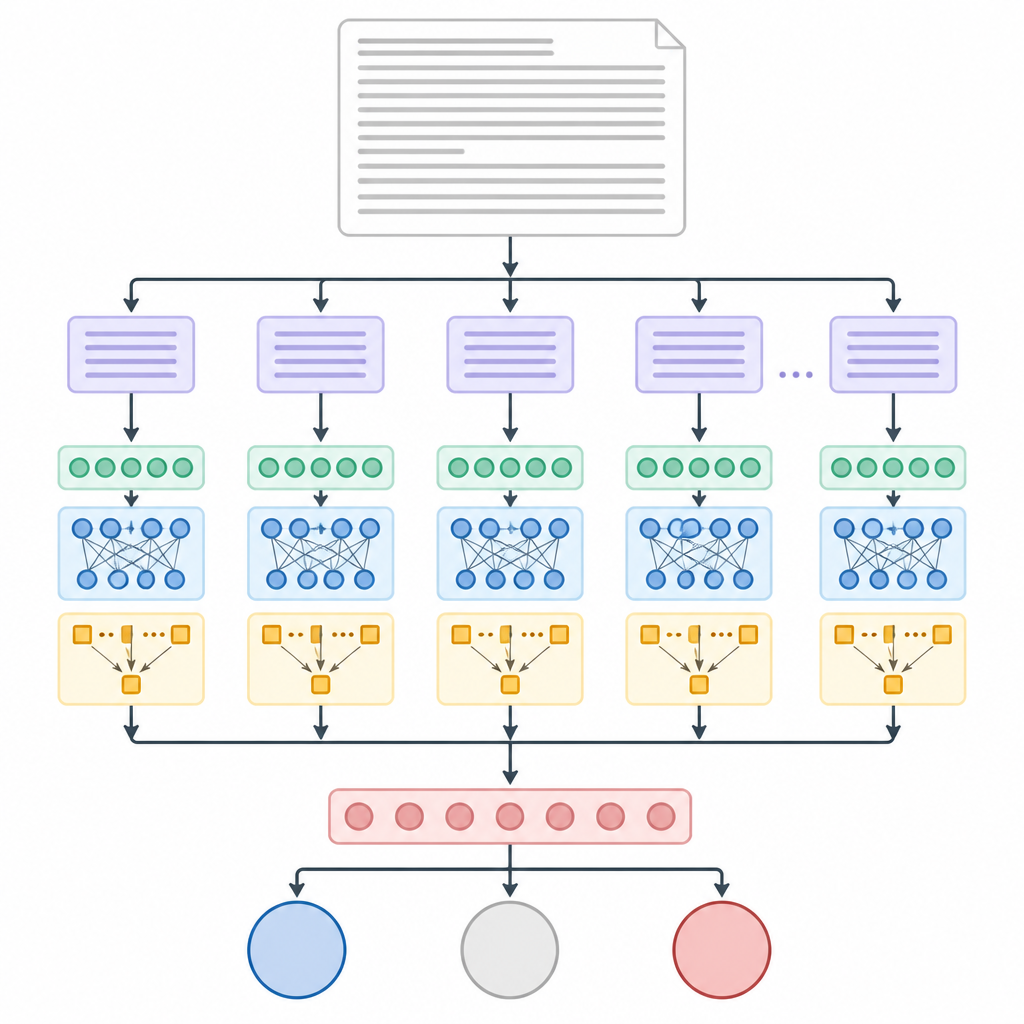
Quanto bene si comporta il sistema
Gli esperimenti hanno mostrato che ChunkyBERT classificava gli articoli con una precisione di validazione di circa l’86 percento e con un buon punteggio su una misura standard di separazione che verifica quanto bene distingue le classi. È risultato particolarmente efficace nell’individuare pezzi chiaramente orientati a sinistra o a destra, mentre gli articoli centristi venivano talvolta confusi con uno dei due lati, riflettendo il loro tono più misto. Uno studio di ablazione, in cui gli autori hanno disattivato parti del modello, ha rivelato che sia il chunking dei documenti lunghi sia gli strati transformer erano cruciali per raggiungere alte prestazioni. Il sistema ha inoltre superato metodi precedenti di rilevamento del bias testati sullo stesso dataset.
Cosa significa per i lettori di notizie
In termini semplici, ChunkyBERT si comporta come un lettore attento e instancabile che scansiona intere storie politiche e stima dove si collocano nello spettro politico. Non elimina il bias dalle notizie, né decide quali opinioni siano corrette, ma può aiutare a segnalare inclinazioni che altrimenti potrebbero passare inosservate. Con affinamenti e adattamenti ad altre lingue e regioni, strumenti simili potrebbero supportare il monitoraggio dei media, le discussioni in classe e le piattaforme di alfabetizzazione digitale, offrendo alle persone una visione più chiara di come l’informazione venga plasmata prima di raggiungere i loro schermi.
Citazione: Loiya, D., Kulal, S.S., Reddy, M.S.M. et al. ChunkyBERT: a novel technique for multiclass political bias detection in news media. Sci Rep 16, 15323 (2026). https://doi.org/10.1038/s41598-026-46646-z
Parole chiave: parzialità dei media politici, classificazione delle notizie, modelli transformer, BERT, alfabetizzazione digitale