Clear Sky Science · nl
ChunkyBERT: een nieuwe techniek voor meervoudige politieke biasdetectie in nieuwsmedia
Waarom verborgen voorkeuren in nieuws ertoe doen
Dagelijks scrollen mensen langs politieke koppen zonder te beseffen hoe woordkeuze en verhaalselectie hun mening subtiel kunnen sturen. Deze studie introduceert ChunkyBERT, een computermodel dat kan vaststellen of lange nieuwsartikelen links, centrum of rechts neigen, door de volledige tekst te gebruiken in plaats van enkele handgeplukte signalen. Het doel is lezers, journalisten en waakhonden te helpen bias in moderne digitale media beter zichtbaar te maken.
Hoe politieke inslag beïnvloedt wat we lezen
Nieuwsmedia kunnen opinies beïnvloeden niet alleen door wat ze zeggen, maar ook door wat ze weglaten, hoe ze gebeurtenissen framen en welke emotionele formuleringen ze kiezen. In het tijdperk van online platforms kan dit verdeeldheid verdiepen, echokamers voeden en misleidende informatie verspreiden. Vroegere computergereedschappen probeerden dit te meten door positieve of negatieve woorden te tellen of door bij te houden hoe vaak bepaalde termen voorkomen. Hoewel nuttig, hebben die instrumenten moeite met context, zoals sarcasme of subtiele framing, en vereisen ze vaak veel handmatige afstemming door experts.
Van handgemaakte aanwijzingen naar volledig tekstbegrip
Recente vorderingen in taaltechnologie stellen modellen in staat betekenis rechtstreeks uit ruwe tekst te leren. Systemen gebaseerd op neurale netwerken en transformers, zoals BERT, kunnen vastleggen hoe woorden elkaar beïnvloeden binnen een zin en over alinea’s heen. Veel eerdere studies gebruikten deze middelen voor haatspraak, nepnieuws of sentimentdetectie, en sommigen probeerden politieke inslag te schatten aan de hand van korte koppen of tweets. Lange politieke artikelen blijven echter een uitdaging, omdat standaardmodellen een limiet hebben aan hoeveel tekst ze in één keer kunnen verwerken en omdat aanwijzingen voor bias verspreid kunnen liggen door het hele verhaal in plaats van in een enkele krachtige quote.

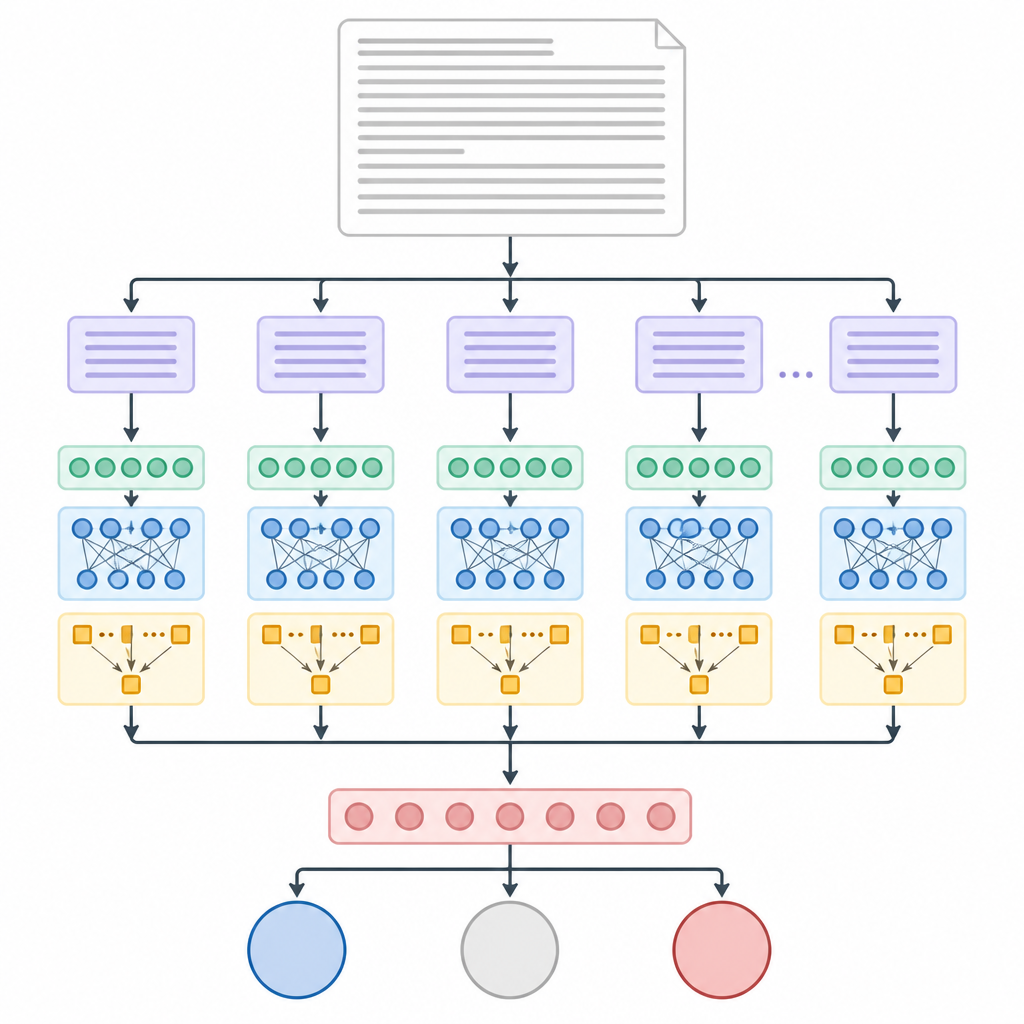
Het opdelen van lange artikelen in hanteerbare stukken
ChunkyBERT pakt dit probleem aan door elk lang artikel eerst in kleinere stukjes van gelijke lengte te knippen, zogeheten chunks. Deze chunks zijn niet uitgelijnd op zinnen of alinea’s, wat het proces eenvoudig en voorspelbaar houdt voor de computer. Elk chunk wordt vervolgens door een voorgetraind taalmodel gehaald dat woorden omzet in numerieke patronen die hun betekenis in context vastleggen. Een tweede transformerlaag verfijnt deze patronen, en een attention-stap laat het systeem stilletjes de woorden en zinnen benadrukken die het meest onthullend lijken voor politieke inslag, terwijl neutrale achtergrondtekst naar de achtergrond wordt geschoven.
Het verhaal weer samenvoegen
Zodra elk chunk op deze manier is samengevat, berekent ChunkyBERT het gemiddelde van de chunk-samenvattingen tot één algeheel vingerafdruk voor het artikel. Deze vingerafdruk gaat vervolgens naar een laatste beslislaag die kiest tussen links, centrum of rechts. De onderzoekers trainden en testten het systeem op meer dan 37.000 nieuwsartikelen met bekende politieke labels, voornamelijk afkomstig uit de Verenigde Staten. Ze vergeleken ChunkyBERT met meer traditionele machine learning-methoden en met andere neurale modellen, inclusief modellen gebaseerd op recurrente netwerken en temporele convoluties, zowel met als zonder chunking en attention.
Hoe goed het systeem presteert
De experimenten toonden aan dat ChunkyBERT artikelen classificeerde met een validatie-accuratesse van ongeveer 86 procent en een sterke score op een standaard maat voor scheiding die controleert hoe goed het onderscheid tussen klassen is. Het presteerde vooral goed bij het herkennen van duidelijk links- of rechtsgerichte stukken, terwijl centrump artikelen soms werden verward met één van de zijden, wat hun meer gemengde toon weerspiegelt. Een ablation-studie, waarin de auteurs onderdelen van het model uitschakelden, liet zien dat zowel het opdelen van lange documenten in chunks als de transformerlagen cruciaal waren om hoge prestaties te bereiken. Het systeem overtrof ook eerdere methoden voor biasdetectie die op dezelfde dataset werden getest.
Wat dit betekent voor nieuwslezers
In eenvoudige bewoordingen gedraagt ChunkyBERT zich als een zorgvuldige, niet vermoeiende lezer die hele politieke verhalen scant en inschat waar ze op het politieke spectrum zitten. Het verwijdert geen bias uit het nieuws en bepaalt niet welke opvattingen juist zijn, maar het kan helpen voorkeuren aan te wijzen die anders ongezien blijven. Met verfijning en aanpassing aan andere talen en regio’s kunnen vergelijkbare hulpmiddelen mediatoezicht, klasdiscussies en platforms voor digitale geletterdheid ondersteunen, en mensen een helderder beeld geven van hoe informatie wordt gevormd voordat deze hun scherm bereikt.
Bronvermelding: Loiya, D., Kulal, S.S., Reddy, M.S.M. et al. ChunkyBERT: a novel technique for multiclass political bias detection in news media. Sci Rep 16, 15323 (2026). https://doi.org/10.1038/s41598-026-46646-z
Trefwoorden: politieke mediabias, nieuwsclassificatie, transformermodellen, BERT, digitale geletterdheid