Clear Sky Science · fr
ChunkyBERT : une technique nouvelle pour la détection multiclasses du biais politique dans les médias
Pourquoi les orientations cachées dans les médias importent
Chaque jour, des personnes parcourent des titres politiques sans se rendre compte à quel point le choix des mots et des sujets peut orienter discrètement leurs opinions. Cette étude présente ChunkyBERT, un modèle informatique conçu pour détecter si de longs articles de presse penchent à gauche, au centre ou à droite, en utilisant le texte intégral plutôt que quelques signaux choisis. L'objectif est d'aider les lecteurs, les journalistes et les observateurs à mieux repérer le biais dans les médias numériques contemporains.
Comment l'inclinaison politique façonne ce que nous lisons
Les médias peuvent influencer l'opinion non seulement par ce qu'ils disent, mais aussi par ce qu'ils omettent, par la manière dont ils cadrent les événements et par les tournures de phrase émotionnelles qu'ils emploient. À l'ère des plateformes en ligne, cela peut approfondir les divisions, alimenter des chambres d'écho et diffuser des informations trompeuses. Les outils informatiques antérieurs cherchaient à mesurer cela en comptant les mots positifs ou négatifs, ou en suivant la fréquence d'apparition de certains termes. Bien qu'utiles, ces méthodes peinent face au contexte, comme le sarcasme ou un cadrage subtil, et exigent souvent beaucoup de paramétrage manuel par des expert·e·s.
Du repérage manuel au lecture du texte intégral
Les avancées récentes en technologie du langage permettent aux modèles d'apprendre le sens directement à partir du texte brut. Les systèmes basés sur des réseaux neuronaux et des transformers, tels que BERT, saisissent comment les mots s'influencent mutuellement dans une phrase et entre paragraphes. De nombreuses études ont utilisé ces outils pour le discours de haine, la détection de fausses informations ou l'analyse de sentiment, et certaines ont tenté d'estimer l'orientation politique à partir de titres courts ou de tweets. Pourtant, les longs articles politiques restent un défi, car les modèles standards ont des limites quant à la quantité de texte qu'ils peuvent traiter simultanément, et parce que les indices de biais peuvent être dispersés tout au long de l'article plutôt que concentrés dans une citation marquante.

Découper les longs articles en morceaux plus simples
ChunkyBERT aborde ce problème en découpant d'abord chaque long article en morceaux plus petits de longueur égale, appelés chunks. Ces chunks ne sont pas alignés sur des phrases ou des paragraphes, ce qui rend le processus simple et prévisible pour l'ordinateur. Chaque chunk est ensuite transmis à un modèle de langage pré-entraîné qui transforme les mots en représentations numériques capturant leur sens dans le contexte. Une seconde couche de transformer affine ces représentations, et une étape d'attention permet au système de mettre en avant discrètement les mots et expressions les plus révélateurs de l'orientation politique tout en minimisant le texte de fond neutre.
Reconstituer l'article
Une fois chaque chunk résumé de cette manière, ChunkyBERT calcule la moyenne des résumés de chunks pour obtenir une empreinte unique de l'article. Cette empreinte est ensuite envoyée dans une couche de décision finale qui choisit entre gauche, centre ou droite. Les chercheur·e·s ont entraîné et évalué le système sur plus de 37 000 articles de presse avec des étiquettes politiques connues, principalement provenant de sources américaines. Ils ont comparé ChunkyBERT à des méthodes d'apprentissage automatique plus traditionnelles et à d'autres modèles neuronaux, y compris des réseaux récurrents et des convolutions temporelles, avec ou sans découpage en chunks et mécanisme d'attention.
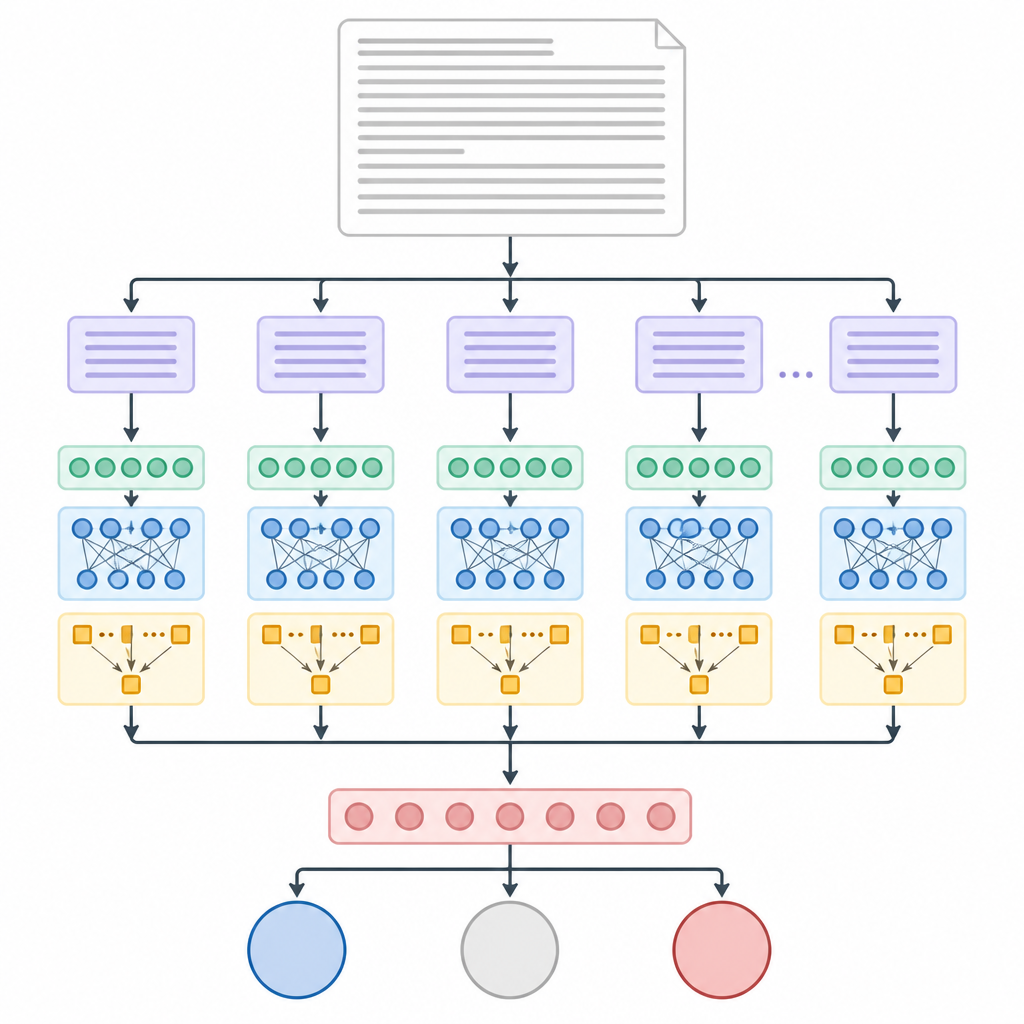
Performance du système
Les expériences ont montré que ChunkyBERT classait les articles avec une précision de validation d'environ 86 % et obtenait un score élevé sur une mesure standard de séparation qui vérifie la qualité de la distinction entre les classes. Il a particulièrement bien identifié les articles clairement orientés à gauche ou à droite, tandis que les articles centristes étaient parfois confondus avec l'un ou l'autre côté, reflétant leur ton plus nuancé. Une étude d'ablation, où les auteurs ont désactivé des composantes du modèle, a révélé que le découpage des documents longs et les couches de transformer étaient cruciaux pour atteindre de bonnes performances. Le système a également surpassé des méthodes antérieures de détection du biais testées sur le même jeu de données.
Ce que cela signifie pour les lecteurs
Concrètement, ChunkyBERT agit comme un lecteur attentif et infatigable qui examine des articles politiques dans leur intégralité et estime leur position sur l'échiquier politique. Il n'élimine pas le biais des informations, et ne tranche pas sur la validité des opinions, mais il peut aider à signaler des penchants qui autrement resteraient invisibles. Avec des ajustements et une adaptation à d'autres langues et régions, des outils similaires pourraient soutenir la surveillance des médias, les discussions en classe et les plateformes de littératie numérique, offrant aux publics une meilleure visibilité sur la manière dont l'information est façonnée avant d'atteindre leurs écrans.
Citation: Loiya, D., Kulal, S.S., Reddy, M.S.M. et al. ChunkyBERT: a novel technique for multiclass political bias detection in news media. Sci Rep 16, 15323 (2026). https://doi.org/10.1038/s41598-026-46646-z
Mots-clés: biais politique des médias, classification de l'actualité, modèles transformers, BERT, littératie numérique