Clear Sky Science · pl
Technologia udostępniania informacji o łańcuchu dostaw oparta na algorytmie konsensusu blockchain i uczeniu federacyjnym
Dlaczego bezpieczne udostępnianie w łańcuchach dostaw ma znaczenie
Współczesne łańcuchy dostaw opierają się na szybkim przepływie danych między fabrykami, magazynami i firmami transportowymi. Jednak w miarę jak coraz więcej informacji trafia do sieci, rośnie ryzyko wycieków, oszustw i manipulacji. Niniejsze badanie bada nowy sposób, w jaki wiele firm może szybko udostępniać wrażliwe dane, zachowując jednocześnie ich prywatność i wiarygodność, wykorzystując rozwiązania z rejestrów cyfrowych i wspólnego uczenia maszynowego.
Problem zaufania i prywatności
Łańcuchy dostaw obejmują wiele niezależnych firm, które często muszą współpracować, ale nie darzą się pełnym zaufaniem. Obecnie informacje takie jak zamówienia, poziomy zapasów i zapisy przesyłek są zwykle przechowywane w systemach centralnych. Systemy te mogą stać się pojedynczymi punktami awarii, a osoby mające dostęp lub hakerzy mogą kopiować lub zmieniać zapisy. Tradycyjne szyfrowanie zabezpiecza dane podczas przesyłu, ale po odszyfrowaniu trudno jest je wykorzystać do wspólnej analizy bez ujawniania tajemnic. Wyzwanie polega na pozwoleniu partnerom na uczenie się na podstawie danych innych podmiotów bez ujawniania surowych szczegółów.
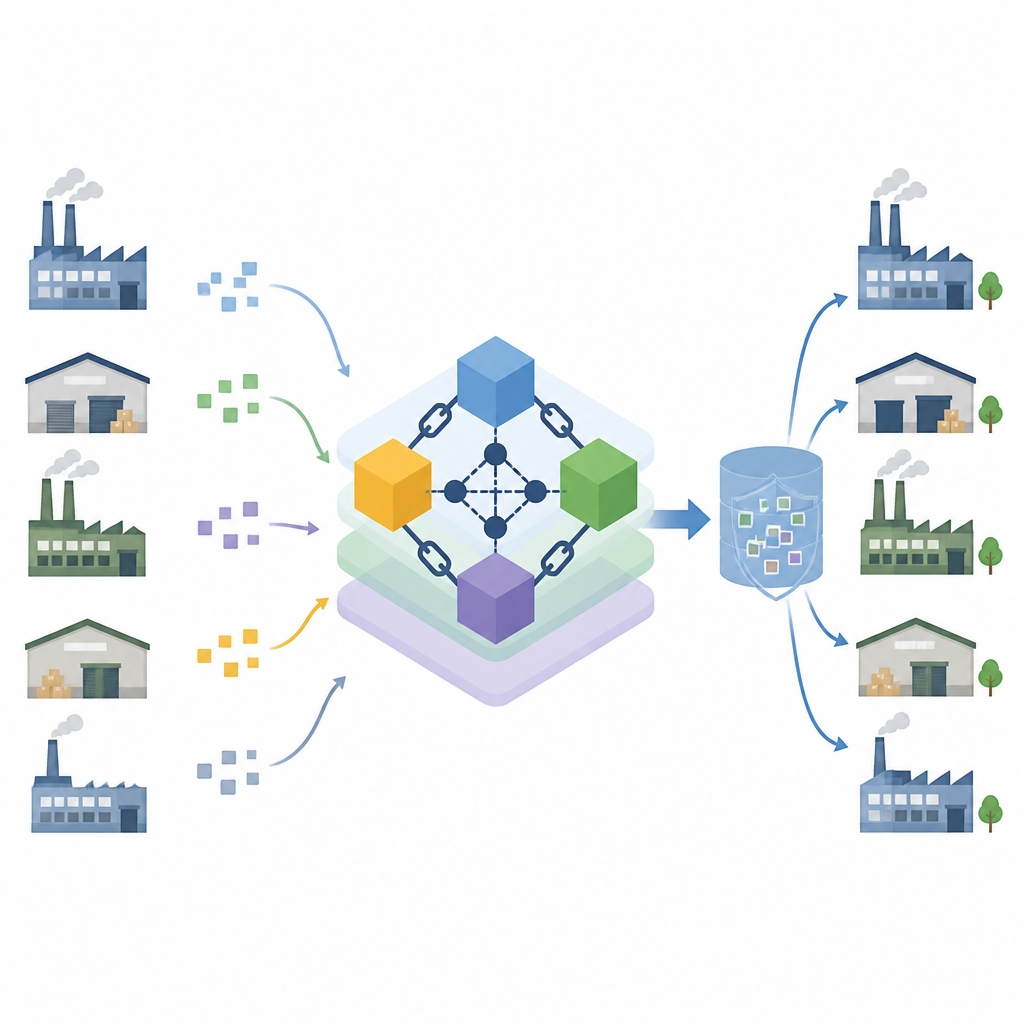
Wspólny rejestr, który sprawiedliwie wybiera liderów
Autorzy opierają się na blockchainie, wspólnym rejestrze utrzymywanym przez wiele komputerów tak, aby żaden pojedynczy podmiot nie kontrolował zapisów. Adaptują znaną metodę koordynacji, która wybiera jeden komputer jako lidera do zbierania i potwierdzania aktualizacji, wzmacniając ją weryfikowalną loterią. Każdy węzeł używa swojego klucza prywatnego i losowej wartości do wygenerowania timera, który inni mogą sprawdzić, co utrudnia nieuczciwemu węzłowi oszustwo przy wyborze lidera. Węzły są pogrupowane w strefy z małymi komitetami, co zmniejsza zużycie energii i przyspiesza uzgadnianie nowych wpisów. Stałe kontrole zdrowia obserwują węzły pod kątem awarii lub niewłaściwego zachowania i automatycznie przenoszą je do mniej zaufanej roli.
Wspólne uczenie bez udostępniania surowych danych
Na bazie tego rejestru badanie buduje system uczenia przyjazny prywatności. Zamiast gromadzić wszystkie zapisy w jednym miejscu, firmy przechowują dane lokalnie i wspólnie trenują model. Specjalny węzeł nadrzędny i niewielki komitet pomagają koordynować trening, ale nigdy nie widzą niechronionych danych. Przed łączeniem zapisów system odnajduje pasujących klientów lub przesyłki między partnerami, używając sprytnych losowych funkcji i metody pakowania zwanej cuckoo hashing. To dopasowanie ujawnia tylko które wpisy pasują, a nie ich pełną zawartość, i utrzymuje niskie obciążenie komunikacyjne nawet przy dużej liczbie węzłów.
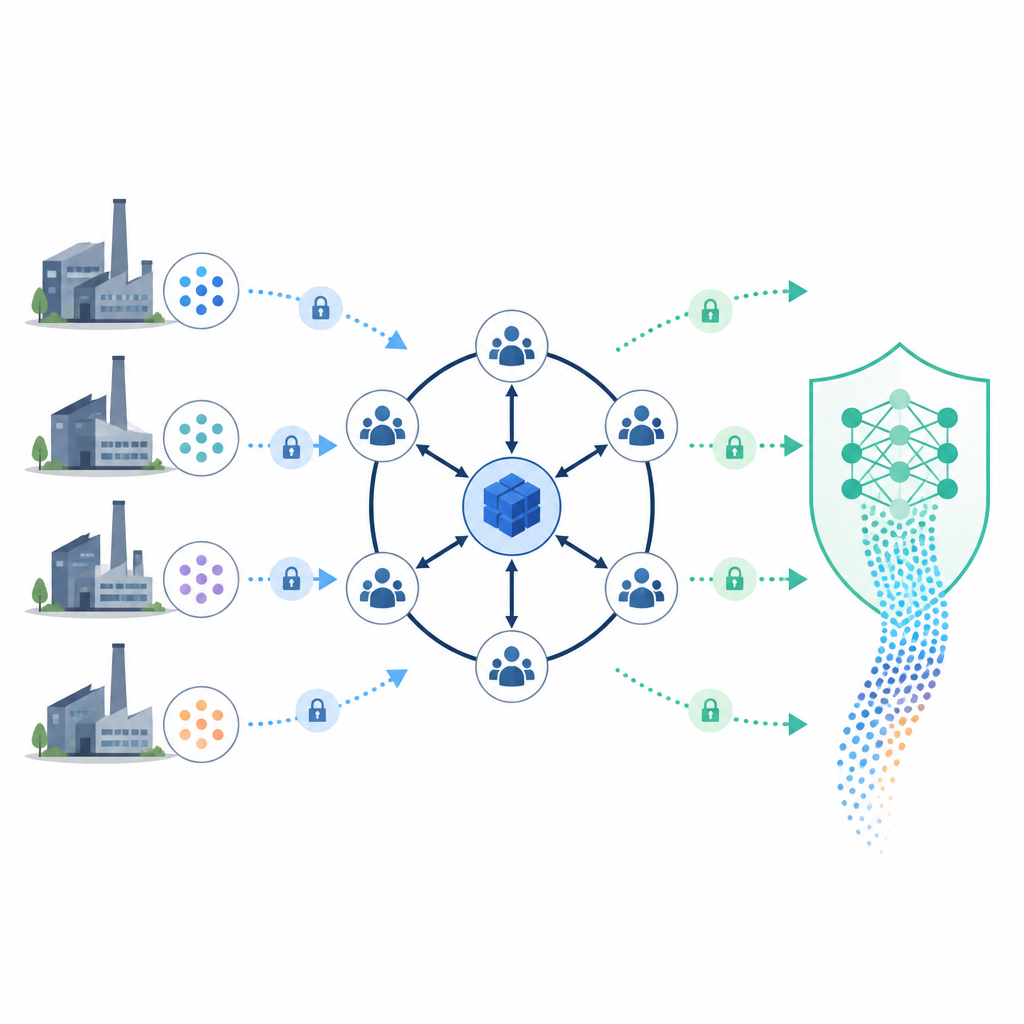
Zabezpieczanie obliczeń inteligentnym szyfrowaniem
Podczas treningu węzeł nadrzędny generuje parę kluczy szyfrujących i przekazuje uczestnikom jedynie klucz publiczny. Szyfrują oni swoje wyniki pośrednie tak, aby można było wykonywać dodawanie i inne operacje, podczas gdy dane pozostają zaszyfrowane. Fragmenty klucza tajnego są rozdzielone między kilka węzłów komitetu, więc jeśli węzeł nadrzędny zawiedzie, inny węzeł może wspólnie odzyskać klucz, bez żadnego pojedynczego podmiotu posiadającego pełną władzę. Dodatkowe zabiegi, takie jak dodawanie kontrolowanego szumu do etykiet i sprawdzanie nietypowych zachowań w aktualizacjach, pomagają bronić się przed kradzieżą tożsamości, manipulacją danymi i próbami odtworzenia prywatnych zapisów z modelu.
Co pokazują eksperymenty w praktyce
Naukowcy testują swoje rozwiązanie w symulowanej sieci kilkudziesięciu węzłów oraz na danych wzorowanych na łańcuchu dostaw od dwóch firm. Ich ulepszona metoda wyboru lidera podejmuje decyzje szybciej niż dwie powszechne alternatywy, z niższym opóźnieniem i większą przepustowością nawet przy wzroście liczby węzłów. Ulepszony model uczenia osiąga wyższą dokładność przy mniejszej liczbie rund treningowych i działa kilkukrotnie szybciej niż standardowe rozwiązanie. W testach udostępniania na żywo metoda generuje dane zgodne z oryginalnymi rekordami w około 92% przypadków, wykrywa niemal 99% prób manipulacji i utrzymuje incydenty naruszenia prywatności na skrajnie niskim poziomie, wszystko przy średnim czasie reakcji około jednej sekundy.
Co to oznacza dla rzeczywistych łańcuchów dostaw
Dla osób niebędących specjalistami kluczowe przesłanie jest takie, że staje się bardziej realne, aby konkurujące i współpracujące firmy uczyły się na podstawie wspólnych danych bez przekazywania ich jednemu zaufanemu operatorowi. Łącząc wspólny rejestr z prywatnościowo świadomym uczeniem i starannym zarządzaniem kluczami, podejście to pozwala firmom szybko wykrywać błędy i oszustwa, wymieniać przydatne wnioski i jednocześnie trzymać wrażliwe szczegóły biznesowe poza zasięgiem. W praktyce wskazuje to kierunek ku łańcuchom dostaw, w których informacje mogą płynąć swobodnie, lecz bezpiecznie, z przejrzystymi zapisami kto co i kiedy zrobił.
Cytowanie: Xu, D., Li, J. & Ren, Z. Supply chain information security sharing technology based on blockchain consensus algorithm and federated learning. Sci Rep 16, 16175 (2026). https://doi.org/10.1038/s41598-026-46101-z
Słowa kluczowe: blockchain, uczenie federacyjne, łańcuch dostaw, bezpieczeństwo informacji, udostępnianie danych