Clear Sky Science · it
Tecnologia di condivisione della sicurezza delle informazioni nella supply chain basata su algoritmo di consenso blockchain e apprendimento federato
Perché la condivisione sicura nelle supply chain è importante
Le supply chain moderne si basano su uno scambio rapido di dati tra stabilimenti, magazzini e società di trasporto. Ma con l’aumento delle informazioni online crescono anche i rischi di fughe, frodi e manomissioni. Questo studio esplora un nuovo modo per molte aziende di condividere dati sensibili con rapidità preservandone al contempo privacy e affidabilità, impiegando concetti provenienti dai registri digitali e dall’apprendimento condiviso.
Il problema della fiducia e della privacy
Le supply chain coinvolgono molte aziende indipendenti che spesso devono cooperare ma non si fidano completamente l’una dell’altra. Oggi informazioni come ordini, livelli di inventario e registri di spedizione sono solitamente memorizzate in sistemi centrali. Questi sistemi possono diventare punti di singola falla, e insider o hacker possono copiare o alterare i record. La crittografia tradizionale protegge i dati durante la trasmissione, ma una volta decrittografati è difficile usarli per analisi congiunte senza esporre segreti. La sfida è permettere ai partner di apprendere dai dati reciproci senza rivelare i dettagli grezzi.
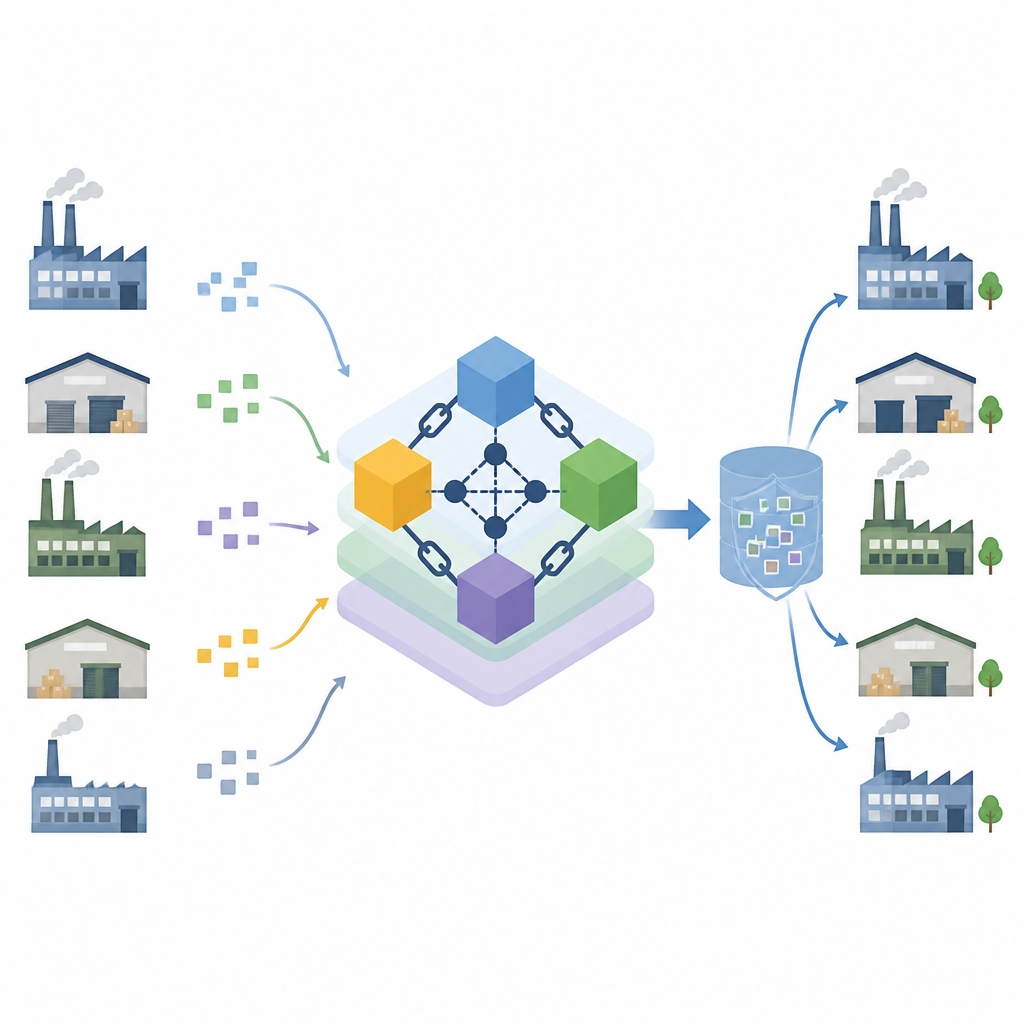
Un registro condiviso che sceglie i leader in modo equo
Gli autori si basano sulla blockchain, un registro condiviso che più computer mantengono insieme in modo che nessuna singola parte controlli i record. Adattano un metodo di coordinamento noto, che sceglie un computer come leader per raccogliere e confermare gli aggiornamenti, ma lo rinforzano con una lotteria verificabile. Ogni nodo usa la propria chiave segreta e un valore casuale per generare un timer che gli altri possono controllare, rendendo difficile a un nodo disonesto barare per ottenere la leadership. I nodi sono raggruppati in zone con piccoli comitati, il che riduce il consumo energetico e accelera il consenso sulle nuove voci. Controlli di integrità monitorano costantemente nodi malfunzionanti o malevoli e li retrocedono automaticamente a un ruolo meno affidabile.
Imparare insieme senza condividere i dati grezzi
Sopra questo registro, lo studio costruisce un sistema di apprendimento rispettoso della privacy. Invece di centralizzare tutti i record in un unico punto, le aziende mantengono i dati localmente e addestrano insieme un modello condiviso. Un nodo master speciale e un piccolo comitato aiutano a coordinare l’addestramento, ma non vedono mai dati non protetti. Prima di combinare i record, il sistema individua clienti o spedizioni corrispondenti tra i partner usando funzioni casuali intelligenti e un metodo di packing chiamato cuckoo hashing. Questo allineamento rivela solo quali voci corrispondono, non i contenuti completi, e mantiene basso il sovraccarico di comunicazione anche quando si uniscono molti nodi.
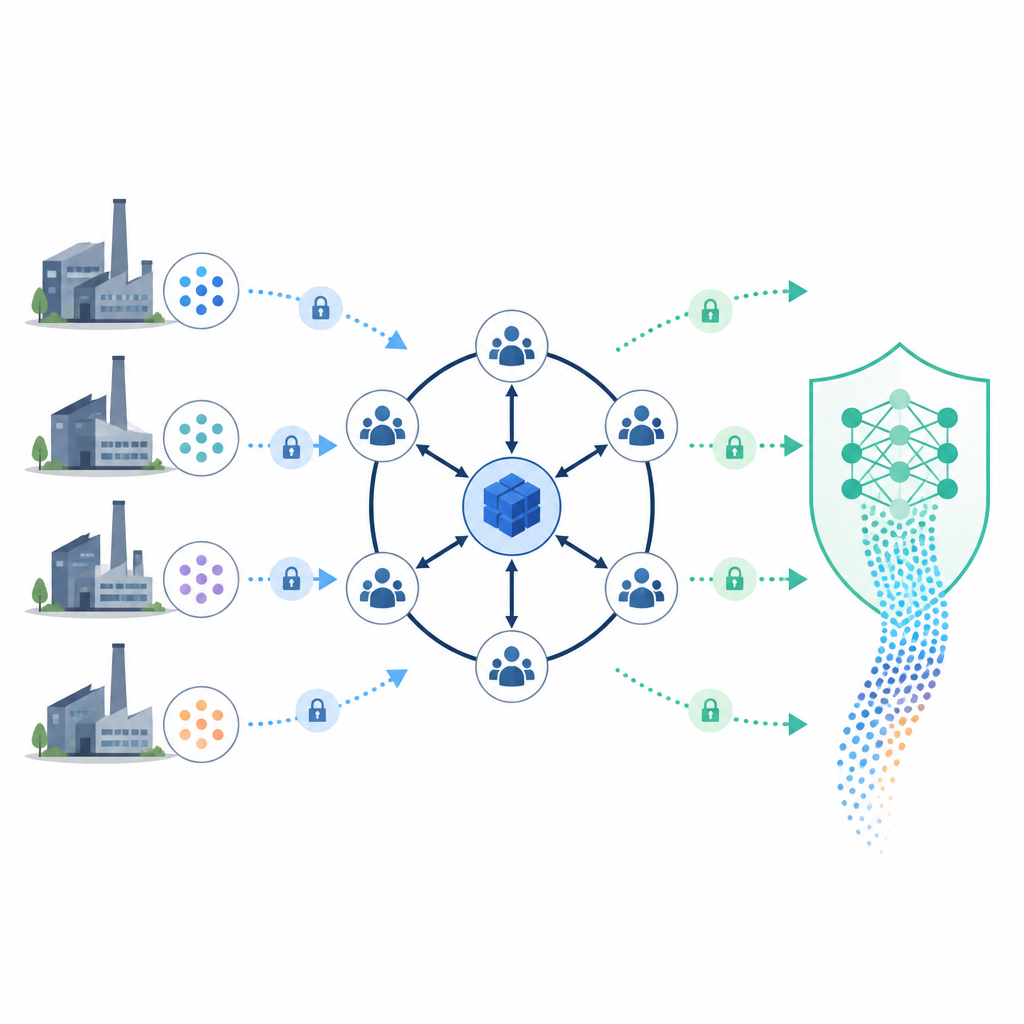
Bloccare i calcoli con crittografia intelligente
Durante l’addestramento, il nodo master crea una coppia di chiavi crittografiche e consegna solo la chiave pubblica ai partecipanti. Essi cifrano i risultati intermedi in modo che somme e altre operazioni possano essere eseguite mentre i dati restano bloccati. Pezzi della chiave segreta sono suddivisi tra diversi nodi del comitato, così se il master fallisce un altro nodo può recuperare la chiave congiuntamente, senza che una singola parte detenga il potere completo. Accorgimenti aggiuntivi, come l’aggiunta di rumore controllato alle etichette e il controllo di comportamenti anomali negli aggiornamenti, aiutano a difendersi da frodi d’identità, manomissioni dei dati e tentativi di ricostruire record privati dal modello.
Cosa mostrano gli esperimenti nella pratica
I ricercatori testano il loro progetto in una rete simulata di dozzine di nodi e con dati in stile supply chain reali provenienti da due aziende. Il loro metodo migliorato di elezione del leader arriva a decisioni più velocemente rispetto a due alternative comuni, con ritardi inferiori e maggiore throughput anche all’aumentare del numero di nodi. Il modello di apprendimento potenziato raggiunge maggiore accuratezza con meno round di addestramento e gira svariate volte più rapidamente di una configurazione standard. Nei test di condivisione live, il metodo produce dati generati che corrispondono ai record originali con circa il 92% di accuratezza, rileva quasi il 99% dei tentativi di manomissione e mantiene le violazioni della privacy estremamente rare, il tutto rispondendo in circa un secondo in media.
Cosa significa questo per le supply chain reali
Per i non specialisti, il messaggio chiave è che sta diventando più realistico per aziende concorrenti e collaboranti imparare dai dati condivisi senza consegnarli tutti a un unico operatore fidato. Fondendo un registro condiviso con apprendimento attento alla privacy e una gestione accurata delle chiavi, questo approccio permette alle aziende di individuare rapidamente errori e frodi, scambiare insight utili e nel contempo tenere nascoste informazioni aziendali sensibili. In termini pratici, indica supply chain in cui l’informazione può circolare liberamente ma in sicurezza, con registri chiari di chi ha fatto cosa e quando.
Citazione: Xu, D., Li, J. & Ren, Z. Supply chain information security sharing technology based on blockchain consensus algorithm and federated learning. Sci Rep 16, 16175 (2026). https://doi.org/10.1038/s41598-026-46101-z
Parole chiave: blockchain, apprendimento federato, supply chain, sicurezza delle informazioni, condivisione dei dati