Clear Sky Science · nl
Informatiebeveiligings- en deeltechnologie voor de toeleveringsketen op basis van een blockchain-consensusalgoritme en federated learning
Waarom veilig delen in toeleveringsketens belangrijk is
Moderne toeleveringsketens zijn afhankelijk van snelle gegevensuitwisseling tussen fabrieken, magazijnen en transportbedrijven. Maar naarmate meer informatie online wordt verplaatst, nemen ook het risico op lekken, fraude en manipulatie toe. Deze studie onderzoekt een nieuwe manier voor veel bedrijven om gevoelige gegevens snel te delen, terwijl ze toch privé en betrouwbaar blijven, met behulp van concepten uit digitale grootboeken en gezamenlijk machine learning.
Het probleem van vertrouwen en privacy
Toeleveringsketens beslaan veel onafhankelijke bedrijven die vaak moeten samenwerken maar elkaar niet volledig vertrouwen. Tegenwoordig worden informatie zoals bestellingen, voorraadniveaus en verzendingsgegevens meestal in centrale systemen opgeslagen. Die systemen kunnen een enkel storingspunt vormen, en insiders of hackers kunnen records kopiëren of wijzigen. Traditionele encryptie beschermt gegevens tijdens verzending, maar eenmaal ontsleuteld is het moeilijk om ze gezamenlijk te analyseren zonder geheimen prijs te geven. De uitdaging is om partners van elkaars gegevens te laten leren zonder de ruwe details te onthullen.
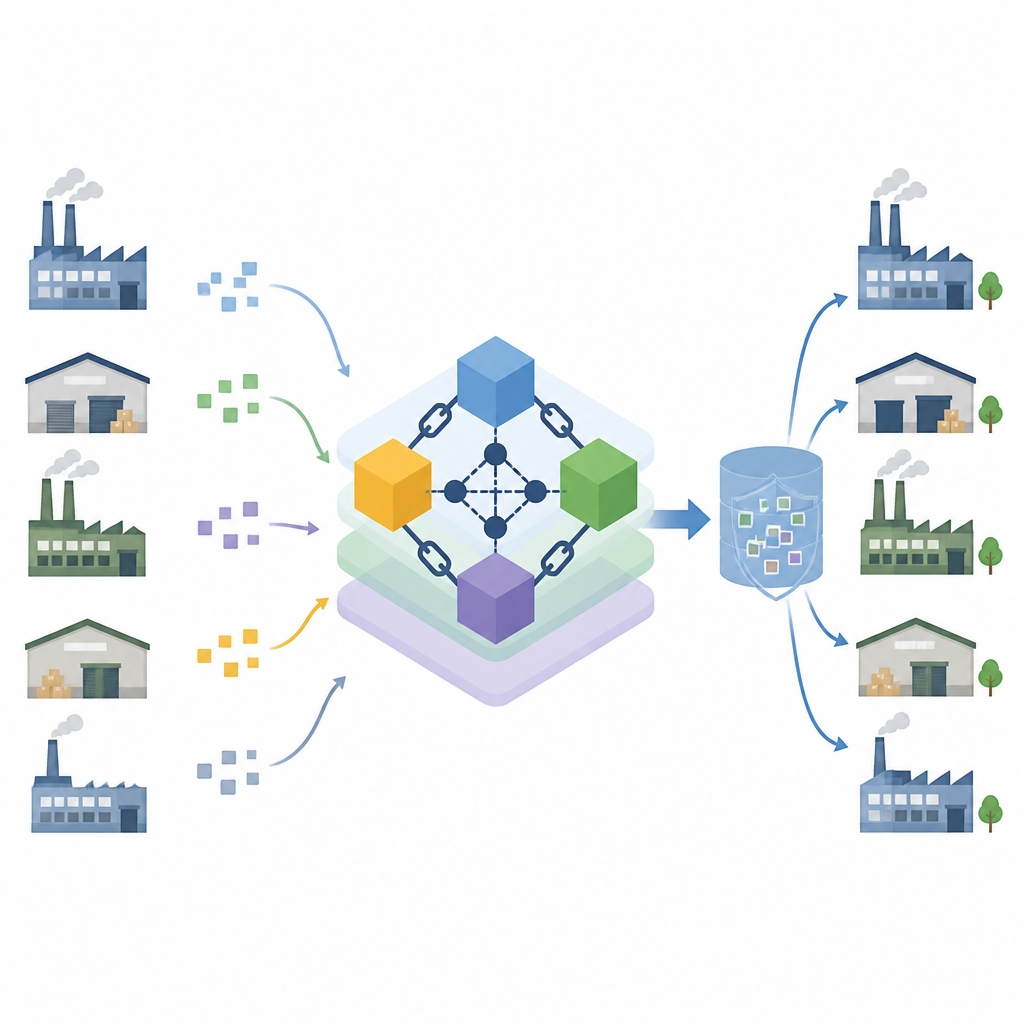
Een gedeeld grootboek dat leiders eerlijk kiest
De auteurs bouwen voort op blockchain, een gedeeld grootboek dat meerdere computers gezamenlijk bijhouden zodat geen enkele partij de records beheerst. Ze passen een bekende coördinatiemethode aan die één computer als leider kiest om updates te verzamelen en te bevestigen, maar ze versterken deze met een verifieerbare loting. Elke node gebruikt zijn geheime sleutel en een willekeurige waarde om een timer te genereren die anderen kunnen controleren, waardoor het moeilijk wordt voor een oneerlijke node om zich tot leider te manipuleren. Nodes zijn gegroepeerd in zones met kleine commissies, wat het energieverbruik verlaagt en het bereiken van overeenstemming over nieuwe invoeren versnelt. Gezondheidscontroles houden voortdurend falende of zich slecht gedraagende nodes in de gaten en zetten ze automatisch terug in een minder vertrouwde rol.
Samen leren zonder ruwe gegevens te delen
Bovenop dit grootboek bouwt de studie een privacyvriendelijk leersysteem. In plaats van alle gegevens op één plek samen te brengen, houden bedrijven hun data lokaal en trainen ze samen een gedeeld model. Een speciale master-node en een kleine commissie helpen de training te coördineren, maar zij zien nooit onbeschermde data. Voordat records worden gecombineerd, vindt het systeem overeenkomende klanten of zendingen tussen partners met behulp van slimme willekeurige functies en een pakmethode genaamd cuckoo-hashing. Deze afstemming onthult alleen welke vermeldingen overeenkomen, niet de volledige inhoud, en houdt de communicatie-overhead laag, zelfs wanneer veel nodes deelnemen.
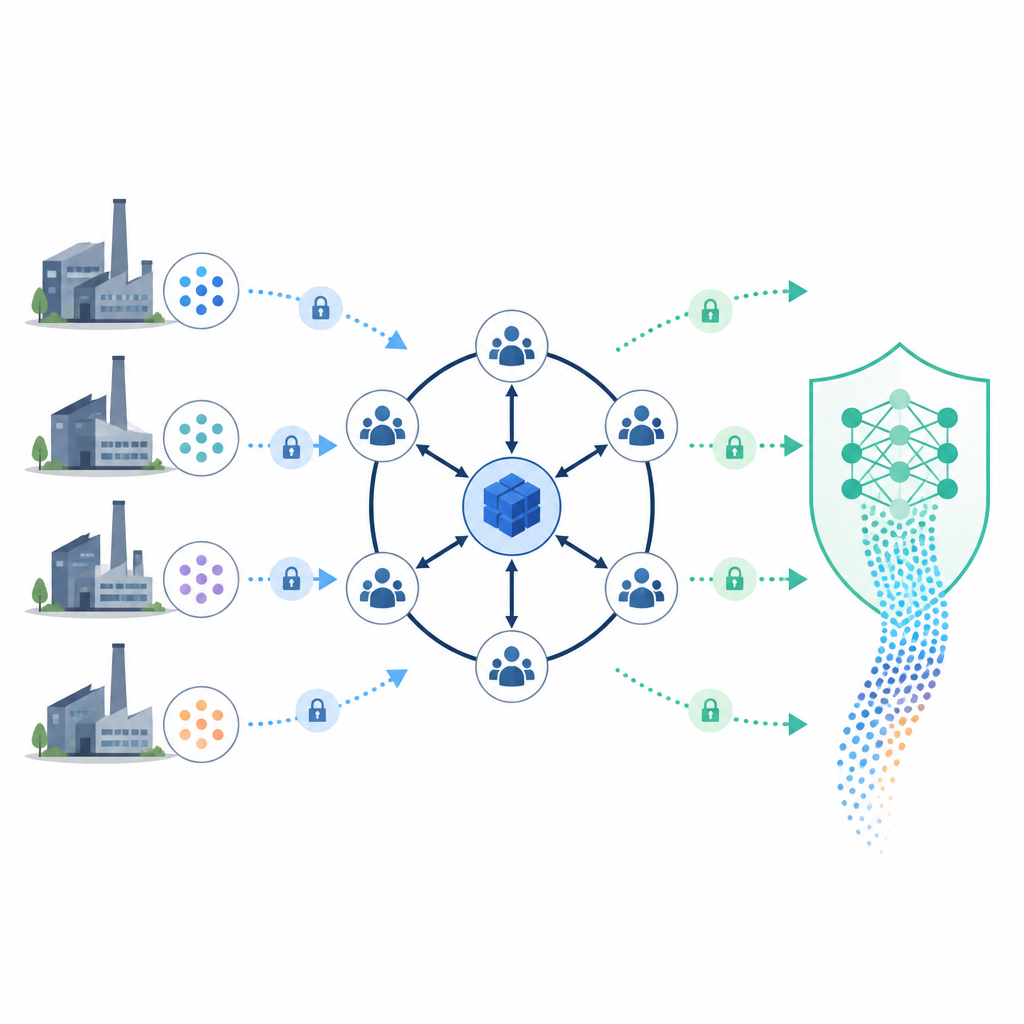
Berekeningen vergrendelen met slimme encryptie
Tijdens de training maakt de master-node een sleutelpaard voor encryptie aan en geeft alleen de publieke sleutel aan de deelnemers. Zij versleutelen hun tussenresultaten zodat optellingen en andere bewerkingen kunnen worden uitgevoerd terwijl de gegevens vergrendeld blijven. Stukken van de geheime sleutel worden verdeeld over meerdere commissie-nodes, zodat als de master uitvalt een andere node de sleutel gezamenlijk kan herstellen, zonder dat één partij volledige macht heeft. Extra middelen, zoals het toevoegen van gecontroleerde ruis aan labels en het controleren op vreemd gedrag in updates, helpen verdedigen tegen identiteitsfraude, gegevensmanipulatie en pogingen om privégegevens uit het model te reconstrueren.
Wat de experimenten in de praktijk laten zien
De onderzoekers testen hun ontwerp in een gesimuleerd netwerk van tientallen nodes en met gegevens in toeleveringsketenstijl van twee bedrijven. Hun verbeterde leiderschapskeuze behaalt beslissingen sneller dan twee gebruikelijke alternatieven, met lagere vertraging en hogere doorvoer, zelfs naarmate het aantal nodes toeneemt. Het verbeterde leer-model bereikt hogere nauwkeurigheid met minder trainingsrondes en werkt meerdere keren sneller dan een standaardopstelling. In live-deeltests produceert de methode gegenereerde gegevens die met ongeveer 92 procent nauwkeurigheid overeenkomen met de oorspronkelijke records, detecteert bijna 99 procent van de manipulatiepogingen en houdt privacyinbreuken uiterst zeldzaam, terwijl de reactie gemiddeld in ongeveer één seconde plaatsvindt.
Wat dit betekent voor echte toeleveringsketens
Voor niet-specialisten is de kernboodschap dat het realistischer wordt voor concurrerende en samenwerkende bedrijven om van gedeelde gegevens te leren zonder alles aan één vertrouwde beheerder te geven. Door een gedeeld grootboek te combineren met privacybewust leren en zorgvuldige sleutelbeheerpraktijken, stelt deze benadering bedrijven in staat fouten en fraude snel te ontdekken, nuttige inzichten uit te wisselen en toch gevoelige bedrijfsgegevens buiten het zicht te houden. In alledaagse termen wijst het op toeleveringsketens waar informatie vrij maar veilig kan bewegen, met duidelijke logboeken van wie wat en wanneer heeft gedaan.
Bronvermelding: Xu, D., Li, J. & Ren, Z. Supply chain information security sharing technology based on blockchain consensus algorithm and federated learning. Sci Rep 16, 16175 (2026). https://doi.org/10.1038/s41598-026-46101-z
Trefwoorden: blockchain, federated learning, toeleveringsketen, informatiebeveiliging, gegevensdeling