Clear Sky Science · de
Technologie zur Sicherung des Informationsaustauschs in Lieferketten basierend auf Blockchain-Konsensalgorithmus und föderiertem Lernen
Warum sicherer Austausch in Lieferketten wichtig ist
Moderne Lieferketten sind auf schnellen Datenaustausch zwischen Fabriken, Lagerhäusern und Transportunternehmen angewiesen. Doch je mehr Informationen online fließen, desto größer werden die Risiken von Lecks, Betrug und Manipulation. Diese Studie untersucht einen neuen Weg, wie viele Unternehmen sensible Daten schnell teilen können, ohne dabei deren Vertraulichkeit und Vertrauenswürdigkeit zu opfern, indem Konzepte aus digitalen Hauptbüchern und gemeinsamem maschinellen Lernen kombiniert werden.
Das Problem von Vertrauen und Privatsphäre
Lieferketten umfassen viele unabhängige Unternehmen, die oft zusammenarbeiten müssen, sich aber nicht vollständig gegenseitig vertrauen. Heutzutage werden Informationen wie Bestellungen, Lagerbestände und Versandaufzeichnungen häufig in zentralen Systemen gespeichert. Solche Systeme können zu Single Points of Failure werden, und Insider oder Hacker können Datensätze kopieren oder verändern. Traditionelle Verschlüsselung schützt Daten während der Übertragung, aber nach dem Entschlüsseln ist es schwierig, sie für gemeinsame Analysen zu nutzen, ohne Geheimnisse preiszugeben. Die Herausforderung besteht darin, Partner voneinander lernen zu lassen, ohne die Rohdaten offenzulegen.
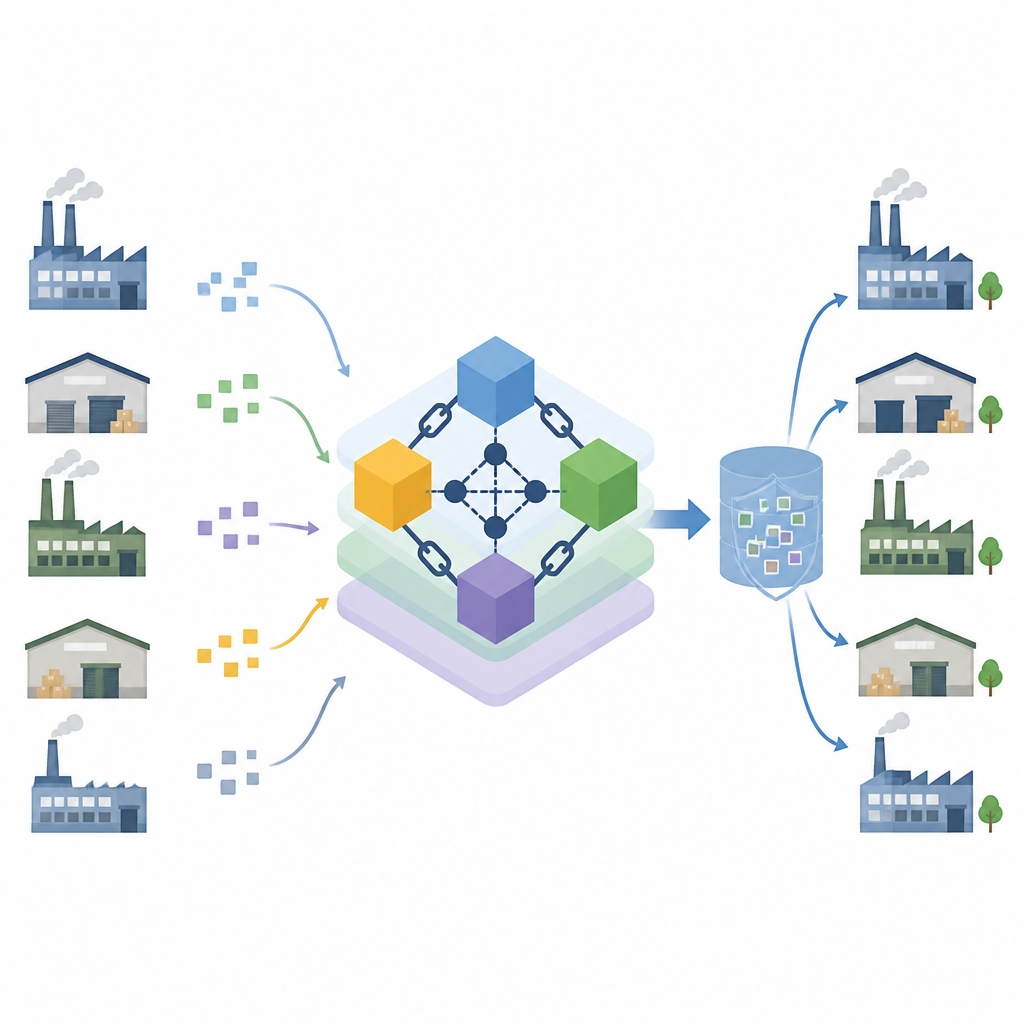
Ein gemeinsames Hauptbuch, das Führerschaft fair wählt
Die Autorinnen und Autoren bauen auf Blockchain auf, einem gemeinsamen Hauptbuch, das von vielen Rechnern gemeinsam geführt wird, sodass keine einzelne Partei die Aufzeichnungen kontrolliert. Sie passen ein bekanntes Koordinationsverfahren an, das einen Rechner als Führer auswählt, um Updates zu sammeln und zu bestätigen, und stärken es mit einer überprüfbaren Lotterie. Jeder Knoten nutzt seinen Geheimschlüssel und einen Zufallswert, um einen Timer zu erzeugen, den andere überprüfen können, was es für einen unehrlichen Knoten erschwert, sich die Führerschaft zu erschleichen. Knoten sind in Zonen mit kleinen Ausschüssen gruppiert, was den Energieverbrauch senkt und das Erreichen von Übereinkunft über neue Einträge beschleunigt. Gesundheitsprüfungen überwachen ständig ausfallende oder fehlverhaltende Knoten und versetzen sie automatisch in eine weniger vertrauenswürdige Rolle.
Gemeinsam lernen, ohne Rohdaten zu teilen
Auf dieses Hauptbuch setzt die Studie ein datenschutzfreundliches Lernsystem. Anstatt alle Aufzeichnungen an einem Ort zu bündeln, behalten Unternehmen ihre Daten lokal und trainieren zusammen ein gemeinsames Modell. Ein spezieller Master-Knoten und ein kleiner Ausschuss helfen bei der Koordination des Trainings, sehen jedoch niemals ungeschützte Daten. Bevor Datensätze zusammengeführt werden, findet das System übereinstimmende Kunden oder Sendungen zwischen den Partnern mithilfe clevere Zufallsfunktionen und einer Packmethode namens Cuckoo-Hashing. Diese Abgleichsmethode offenbart nur, welche Einträge übereinstimmen, nicht deren vollständige Inhalte, und hält den Kommunikationsaufwand auch bei vielen teilnehmenden Knoten niedrig.
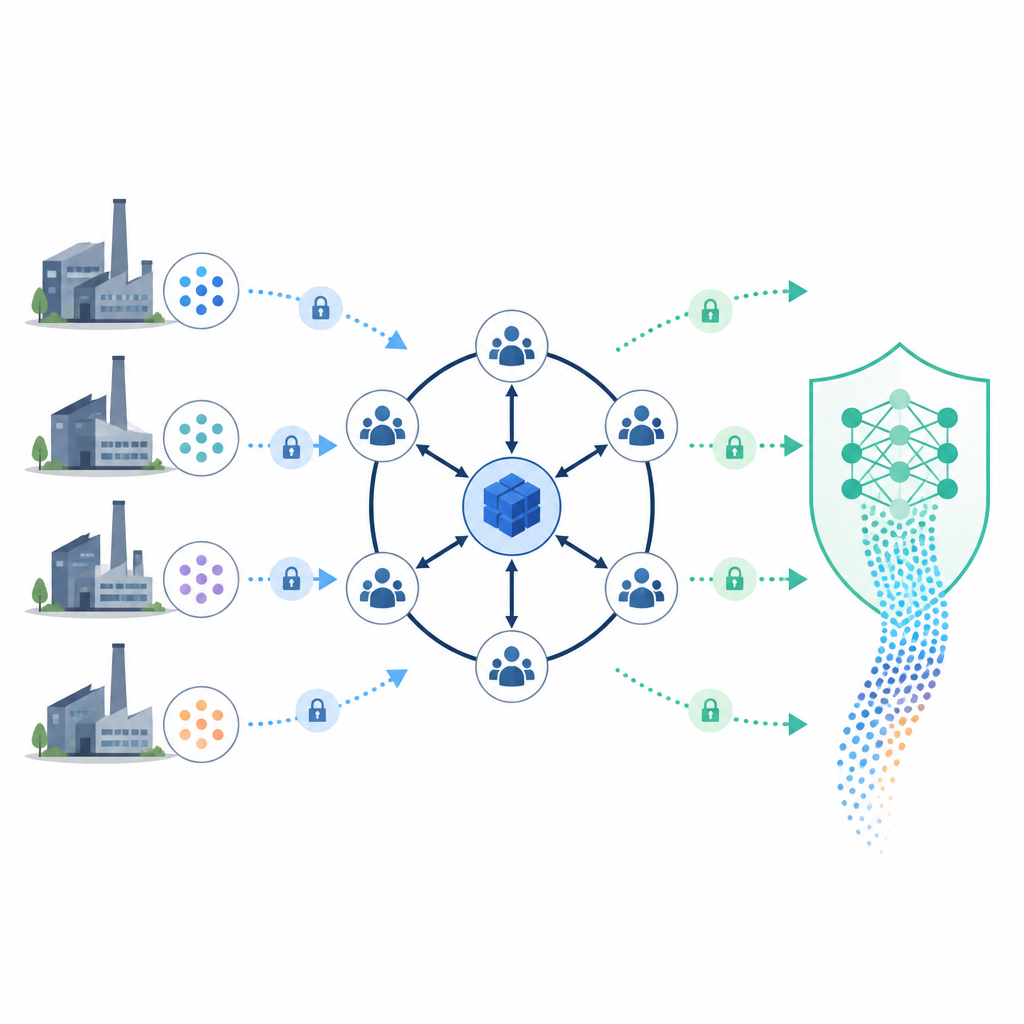
Berechnungen absichern mit intelligenter Verschlüsselung
Während des Trainings erzeugt der Master-Knoten ein Schlüsselpaar und gibt nur den öffentlichen Schlüssel an die Teilnehmer. Sie verschlüsseln ihre Zwischenresultate so, dass Additionen und andere Operationen durchgeführt werden können, während die Daten verschlossen bleiben. Teile des privaten Schlüssels werden auf mehrere Ausschussknoten verteilt, sodass im Fehlerfall ein anderer Knoten den Schlüssel gemeinsam wiederherstellen kann, ohne dass eine einzelne Partei die volle Macht besitzt. Zusätzliche Maßnahmen, wie das Hinzufügen kontrollierten Rauschens zu Labels und die Prüfung auf auffälliges Verhalten in Updates, helfen, Identitätsbetrug, Datenmanipulation und Versuche, private Datensätze aus dem Modell zu rekonstruieren, abzuwehren.
Was die Experimente in der Praxis zeigen
Die Forschenden testen ihr Design in einem simulierten Netzwerk mit Dutzenden von Knoten und mit realistischen Lieferkettendaten von zwei Unternehmen. Ihre verbesserte Führerschafts-Wahlmethode trifft Entscheidungen schneller als zwei gängige Alternativen, mit geringerer Verzögerung und höherem Durchsatz, selbst wenn die Anzahl der Knoten wächst. Das verbesserte Lernmodell erreicht höhere Genauigkeit mit weniger Trainingsrunden und läuft mehrere Male schneller als eine Standardkonfiguration. In Live-Tests beim Teilen erzeugt die Methode Daten, die mit den Originalaufzeichnungen etwa 92 Prozent Übereinstimmung zeigen, erkennt nahezu 99 Prozent der Manipulationsversuche und hält Datenschutzverletzungen sehr selten, und das alles bei einer durchschnittlichen Reaktionszeit von etwa einer Sekunde.
Was das für reale Lieferketten bedeutet
Für Nicht-Fachleute lautet die Kernaussage: Es wird realistischer, dass konkurrierende und kooperierende Firmen aus gemeinsamen Daten lernen können, ohne diese an einen einzigen vertrauenswürdigen Betreiber zu übergeben. Durch die Kombination eines gemeinsamen Hauptbuchs mit datenschutzbewusstem Lernen und sorgfältigem Schlüsselmanagement ermöglicht dieser Ansatz, Fehler und Betrug schnell zu erkennen, nützliche Erkenntnisse auszutauschen und gleichzeitig sensible Geschäftsinformationen verborgen zu halten. Alltagssprachlich weist er in Richtung Lieferketten, in denen Informationen frei, aber sicher fließen können und mit klaren Aufzeichnungen, wer wann was getan hat.
Zitation: Xu, D., Li, J. & Ren, Z. Supply chain information security sharing technology based on blockchain consensus algorithm and federated learning. Sci Rep 16, 16175 (2026). https://doi.org/10.1038/s41598-026-46101-z
Schlüsselwörter: blockchain, federiertes Lernen, Lieferkette, Informationssicherheit, Datenfreigabe