Clear Sky Science · pl
PS-SNN: uczenie separacji wzorców dla rozszerzalnych kolczastych sieci neuronowych w uczeniu przyrostowym klas
Dlaczego warto nauczyć maszyny „pamiętać”
Współczesne systemy sztucznej inteligencji robią wrażenie, ale mają poważną słabość: gdy uczą się czegoś nowego, mają tendencję do zapominania wcześniejszych informacji. Ta „amnezja” stanowi poważną przeszkodę dla robotów, telefonów i innych urządzeń, które muszą nadal uczyć się ze zmieniającego się świata bez ponownego trenowania od zera. Artykuł o PS-SNN wprowadza zainspirowane mózgiem rozwiązanie, które pomaga energooszczędnym kolczastym sieciom neuronowym uczyć się nowych kategorii w czasie, jednocześnie zachowując wcześniejszą wiedzę, co wskazuje drogę ku mądrzejszej i bardziej niezawodnej sztucznej inteligencji działającej na sprzęcie niskiego poboru mocy.
Problem zapominania w czasie
Większość modeli AI jest trenowana jednokrotnie na ustalonym zbiorze danych, a potem wdrażana. W praktyce jednak dane napływają falami: kamera może zobaczyć nowy rodzaj obiektów w przyszłym miesiącu, które wcześniej nie były oznaczone. Gdy standardowa sieć neuronowa jest aktualizowana o te nowe kategorie, jej wewnętrzna „przestrzeń cech” ulega przekształceniu, a wydajność na wcześniejszych kategoriach często się załamuje — zjawisko to nazywa się katastrofalnym zapominaniem. To jest szczególnie trudne w uczeniu przyrostowym klas, gdzie system musi rozpoznawać wszystkie dotąd napotkane kategorie bez informacji, z której fazy treningu pochodzą. Kolczaste sieci neuronowe, które komunikują się krótkimi impulsami elektrycznymi podobnie jak neurony biologiczne i są atrakcyjne dla energooszczędnych układów, cierpią na ten sam problem i otrzymały znacznie mniej uwagi niż konwencjonalne głębokie sieci.
Uczenie się przez wzrost i separację w mózgu
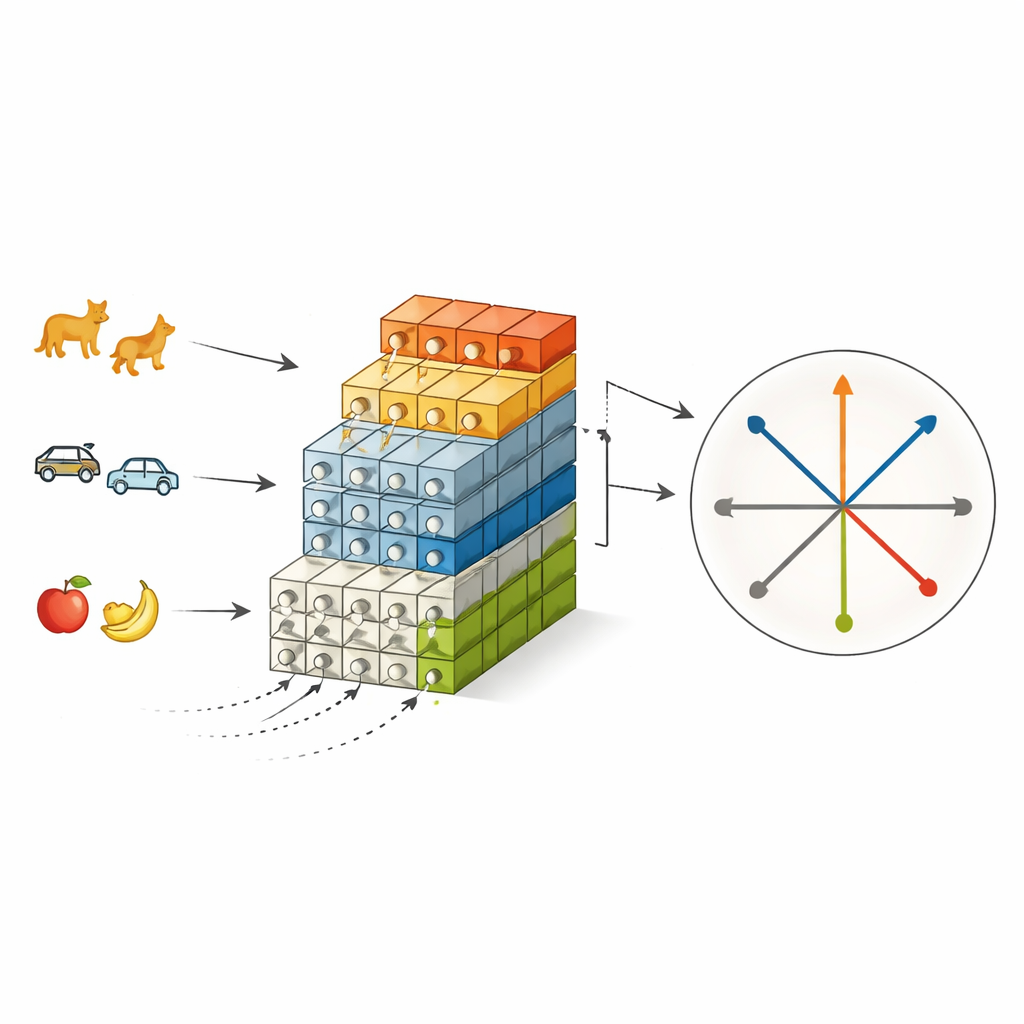
Neuroscience sugeruje dwa komplementarne pomysły dla uczenia się przez całe życie. Po pierwsze, mózg może wytwarzać nowe neurony, zwłaszcza w obszarze zwanym hipokampem, co pozwala przechowywać nowe wspomnienia bez nadpisywania starych. Po drugie, inna część hipokampu, zakręt zębaty (dentate gyrus), uważana jest za „separator wzorców”: nawet podobne doświadczenia są mapowane na odrębne, niepokrywające się wzorce aktywności, aby nie wchodziły ze sobą w konflikt. Istniejące metody uczenia ciągłego dla sieci kolczastych zwykle koncentrują się na zmianie struktury sieci lub ponownym wykorzystaniu starych danych, ale nadal polegają na losowo inicjowanych warstwach wyjściowych, co może powodować drift i nakładanie się wewnętrznych reprezentacji kategorii w miarę pojawiania się nowych zadań. Autorzy twierdzą, że ten pomijany projekt klasyfikatora jest kluczowym źródłem niestabilności.
Jak PS-SNN zmienia proces uczenia
PS-SNN łączy te dwa inspirowane mózgiem pomysły w kolczastej sieci zaprojektowanej do uczenia przyrostowego klas. Gdy pojawiają się nowe grupy klas, sieć rośnie przez dodanie nowych modułów ekstrakcji cech, podczas gdy wcześniejsze moduły są zamrażane, co odzwierciedla neurogenezę i zachowuje wcześniejszą wiedzę. Jednocześnie, zamiast za każdym razem uczyć nowej warstwy wyjściowej od zera, metoda przypisuje każdej możliwej klasie wcześniej obliczony kierunek w przestrzeni cech. Kierunki te są skonstruowane tak, aby były wzajemnie ortogonalne, co oznacza, że każda klasa jest od początku zakotwiczona w odrębnym, niepokrywającym się miejscu. Podczas pierwszego etapu treningu, nazwanego uczeniem separacji wzorców, klasyfikator pozostaje stały, a jedynie ekstraktory cech się dostosowują, zmuszając reprezentację impulsową każdej klasy do silnego skupienia wokół przypisanego kierunku i zmniejszając konflikty między starymi i nowymi zadaniami.

Dostrajanie decyzji bez niszczenia pamięci
Kotwice ortogonalne znacznie poprawiają stabilność, ale są też sztywne. Aby odzyskać elastyczność, PS-SNN dodaje drugi etap zwany udoskonalaniem wzorców. Tutaj ekstraktory cech są zamrożone, a jedynie klasyfikator jest dostosowywany, przy użyciu starannie wyważonej mieszanki starych i nowych przykładów, tak aby żadna grupa klas nie dominowała. Ten etap subtelnie kształtuje granice decyzyjne między już dobrze rozdzielonymi kierunkami klas, poprawiając dyskryminację — szczególnie dla wizualnie podobnych kategorii — bez naruszania podstawowych reprezentacji ustabilizowanych w pierwszym etapie. System utrzymuje także małą pamięć powtórzeniową przeszłych próbek, co pomaga prowadzić oba etapy przy jednoczesnym utrzymaniu umiarkowanej pojemności przechowywania.
Co wyniki znaczą dla przyszłej AI
Testowany na standardowych benchmarkach obrazowych, gdzie klasy pojawiają się w wielu krokach, PS-SNN znacząco przewyższa wcześniejsze metody uczenia ciągłego oparte na kolczastych sieciach, a nawet dorównuje lub przewyższa kilka wiodących konwencjonalnych głębokich sieci, zachowując jednocześnie korzyści energetyczne obliczeń opartych na impulsach. Poprzez połączenie rozszerzalnej struktury sieci z stałymi, dobrze rozdzielonymi kotwicami klas, podejście to wyraźnie zmniejsza powolny drift wewnętrznych reprezentacji, który zwykle podważa długoterminowe uczenie. Dla osób spoza specjalności wniosek jest taki, że praca ta przybliża AI do zdolności mózgu do ciągłego uczenia się bez zapominania, w formie, która mogłaby działać efektywnie na przyszłych neuromorficznych chipach wbudowanych w urządzenia codziennego użytku.
Cytowanie: Hu, K., Wen, L., Zhang, T. et al. PS-SNN: pattern separation learning for expandable spiking neural networks in class-incremental learning. Sci Rep 16, 12653 (2026). https://doi.org/10.1038/s41598-026-42970-6
Słowa kluczowe: uczenie ciągłe, kolczaste sieci neuronowe, katastrofalne zapominanie, obliczenia neuromorficzne, separacja wzorców