Clear Sky Science · de
PS-SNN: Mustertrennungslernen für erweiterbare spikende neuronale Netze im klassen-incrementellen Lernen
Warum es wichtig ist, Maschinen das „Erinnern“ beizubringen
Moderne KI-Systeme beeindrucken, haben aber eine gravierende Schwäche: Wenn sie etwas Neues lernen, neigen sie dazu, zuvor Gelerntes zu vergessen. Diese „Amnesie“ ist ein großes Hindernis für Roboter, Telefone und andere Geräte, die in einer sich verändernden Welt weiterlernen müssen, ohne von Grund auf neu trainiert zu werden. Das Paper zu PS-SNN stellt einen vom Gehirn inspirierten Ansatz vor, der energieeffizienten spikenden neuronalen Netzen hilft, im Laufe der Zeit neue Kategorien zu lernen, ohne vorhandenes Wissen zu verlieren. Das weist den Weg zu intelligenterer und verlässlicherer KI, die auf stromsparender Hardware laufen kann.
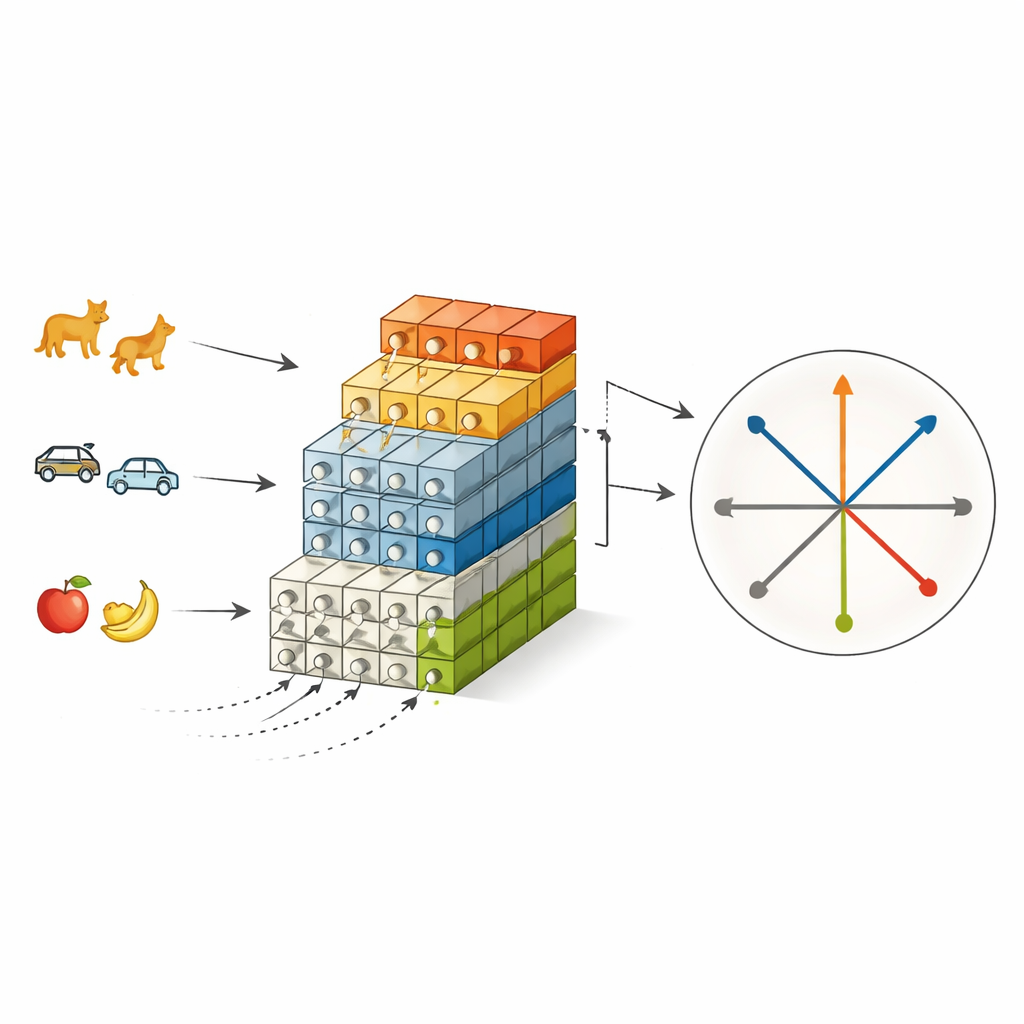
Das Problem des Vergessens über die Zeit
Die meisten KI-Modelle werden einmal auf einem festen Datensatz trainiert und dann eingesetzt. In der Praxis treffen Daten jedoch in Wellen ein: Eine Kamera kann nächsten Monat neue Objektarten sehen, die zuvor nie gelabelt wurden. Wenn ein Standard-Neuronales Netz auf diese neuen Kategorien aktualisiert wird, verändert sich sein interner „Merkmalsraum“ und die Leistung auf früheren Kategorien bricht oft zusammen — ein Phänomen, das als katastrophales Vergessen bekannt ist. Das ist besonders anspruchsvoll beim klassen-incrementellen Lernen, bei dem das System alle bisher gesehenen Kategorien erkennen muss, ohne zu wissen, aus welcher Trainingsphase sie stammen. Spikende neuronale Netze, die wie biologische Neuronen mit kurzen elektrischen Spike-Impulsen kommunizieren und sich für energieeffiziente Chips eignen, sind von demselben Problem betroffen, haben aber deutlich weniger Aufmerksamkeit erhalten als konventionelle tiefe Netze.
Lernen durch Wachstum und Trennung im Gehirn
Die Neurowissenschaft liefert zwei komplementäre Ideen für lebenslanges Lernen. Erstens kann das Gehirn neue Neuronen bilden, besonders in einer Region namens Hippocampus, wodurch neue Erinnerungen gespeichert werden können, ohne alte zu überschreiben. Zweitens wird einem Teil des Hippocampus, dem Gyrus dentatus, eine Funktion als „Mustertrenner“ zugeschrieben: Selbst ähnliche Erfahrungen werden auf unterschiedliche, sich nicht überlappende Aktivitätsmuster abgebildet, sodass sie einander nicht stören. Bestehende Methoden des kontinuierlichen Lernens für spikende Netze konzentrieren sich typischerweise auf die Veränderung der Netzwerkstruktur oder die Wiederverwendung alter Daten, verlassen sich jedoch immer noch auf zufällig initialisierte Ausgabeschichten, was dazu führen kann, dass sich die internen Repräsentationen von Kategorien verschieben und überlappen, wenn neue Aufgaben eintreffen. Die Autoren argumentieren, dass dieses übersehene Design des Klassifikators eine zentrale Quelle der Instabilität ist.
Wie PS-SNN den Lernprozess umgestaltet
PS-SNN kombiniert diese beiden gehirninspirierten Ideen in einem spikenden Netzwerk, das für klassen-incrementelles Lernen entwickelt wurde. Wenn neue Gruppen von Klassen eintreffen, wächst das Netzwerk durch Hinzufügen frischer Feature-Extraktionsmodule, während frühere Module eingefroren werden — ein Echo der Neurogenese, das vorheriges Wissen bewahrt. Gleichzeitig wird statt jedes Mal eine neue Ausgabeschicht von Grund auf zu lernen jeder möglichen Klasse eine vorab berechnete Richtung im Merkmalsraum zugewiesen. Diese Richtungen sind so konstruiert, dass sie paarweise orthogonal sind, das heißt jede Klasse ist von Anfang an an einen eindeutigen, nicht überlappenden Slot gebunden. Während der ersten Trainingsphase, genannt Mustertrennungslernen, bleibt der Klassifikator fixiert und nur die Feature-Extraktoren passen sich an, wodurch die spike-basierten Repräsentationen jeder Klasse eng um ihre zugewiesene Richtung gruppiert werden und Konflikte zwischen alten und neuen Aufgaben reduziert werden.

Feinabstimmung von Entscheidungen ohne Erinnerungen zu zerstören
Orthogonale Anker verbessern die Stabilität erheblich, sind aber auch starr. Um Flexibilität zurückzugewinnen, fügt PS-SNN eine zweite Phase namens Musterverfeinerungslernen hinzu. Hier werden die Feature-Extraktoren eingefroren und nur der Klassifikator angepasst, wobei eine sorgfältig ausbalancierte Mischung aus alten und neuen Beispielen verwendet wird, sodass keine Klassegruppe dominiert. Diese Phase formt die Entscheidungsgrenzen zwischen den bereits gut getrennten Klassendirektionen subtil um und verbessert die Diskrimination — besonders bei visuell ähnlichen Kategorien — ohne die zugrunde liegenden Repräsentationen zu stören, die in der ersten Phase stabilisiert wurden. Das System führt außerdem einen kleinen Replay-Speicher vergangener Proben, der beide Phasen unterstützt und gleichzeitig den Speicherbedarf gering hält.
Was die Ergebnisse für die zukünftige KI bedeuten
Getestet auf gängigen Bild-Benchmarks, bei denen Klassen in mehreren Schritten eintreffen, übertrifft PS-SNN frühere spikende Methoden des kontinuierlichen Lernens deutlich und kommt sogar an einige führende konventionelle tiefe Netze heran oder übertrifft sie, während es gleichzeitig die energiesparenden Vorteile spike-basierter Berechnung beibehält. Durch die Kombination einer erweiterbaren Netzwerkstruktur mit festen, gut getrennten Klassenankern verringert der Ansatz die langsame Drift interner Repräsentationen, die üblicherweise langfristiges Lernen untergräbt, deutlich. Für Nicht-Fachleute lautet die Botschaft: Diese Arbeit bringt KI dem Gehirn näher, indem sie die Fähigkeit unterstützt, weiterzulernen, ohne zu vergessen — in einer Form, die effizient auf zukünftigen neuromorphen Chips in Alltagsgeräten laufen könnte.
Zitation: Hu, K., Wen, L., Zhang, T. et al. PS-SNN: pattern separation learning for expandable spiking neural networks in class-incremental learning. Sci Rep 16, 12653 (2026). https://doi.org/10.1038/s41598-026-42970-6
Schlüsselwörter: kontinuierliches Lernen, spikende neuronale Netze, katastrophales Vergessen, neuromorphe Rechnersysteme, Mustertrennung